sphinx-coreseek 优化指南
html_strip:HTML 标记清除
只保留标记之间的内容,HTML 标签和 HTML 注释会被删除。比如:
<a target="_blank" class="external-link" href="http://www.google.com">google</a>开启 html_strip=1 后,就只保留内容 google。默认情况 html_strip 的值是 0,表示禁用,1 表示启用。如果要把标签之间的内容也删除的话,那么就要使用 html_remove_elements 属性了。
看下面这个例子:
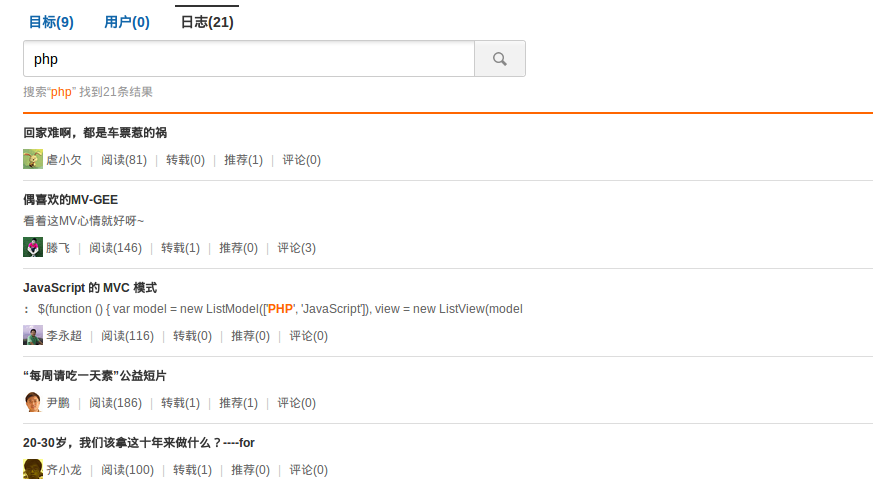
第一条记录看上去就是无相关的,点进去看了下,就是一个一个视频链接,里面有这么一段:
<embed src="http://player.youku.com/player.php/Type/Folder/Fid/18841125/Ob/1/sid/XNTA1MTg0NDg0/v.swf" type="application/x-shockwave-flash" width="660" height="500" autostart="true" loop="true">
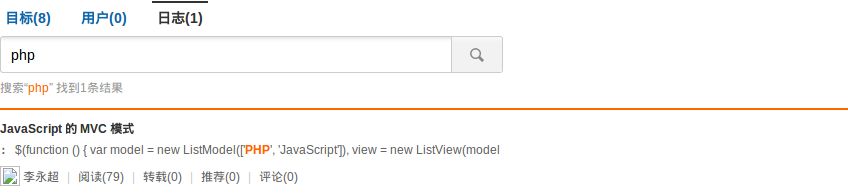
这个 embed 标签里面有一个链接包含 php 的字符。我们设置 html_strip=1,再来看结果就只有一条记录了。
exceptions
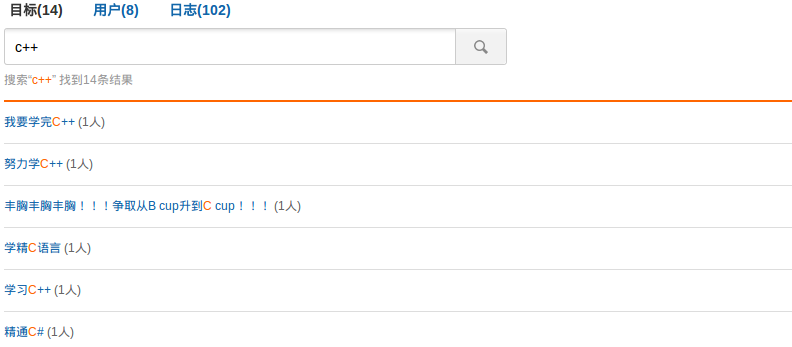
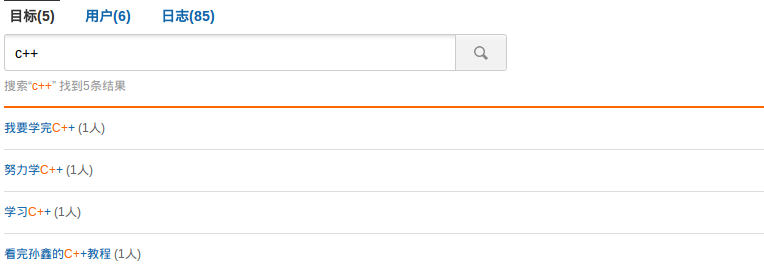
在搜索 c++、c# 等词的时候,包含 c 的内容都搜索出来了,显然这不是我们想要的,exceptions 的功能就是将一个或多个 Token 映射成一个单独的关键字,与 wordforms 类似,但是也有很多不同的地方。
- exceptions 大小写敏感,wordforms 大小写无关
- exeptions 可以使用 charset_table 中没有的特殊符号,wordforms 完全遵从 charset_table。
示例:
AT & T => AT&TAT&T => AT&T
Standarten Fuehrer => standartenfuhrer
Standarten Fuhrer => standartenfuhrer
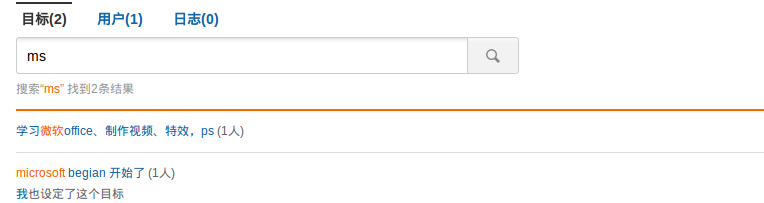
MS Windows => ms windows
Microsoft Windows => ms windows
C++ => cplusplus
c++ => cplusplus
C plus plus => cplusplus
注意 => 的字符串都是单个完成的字符串,无论是 & 还是空格都是看作单个字符串的一部分。
exception 和 wordform 还相互影响
wordforms:词形字典
wordforms = /usr/local/sphinx/data/wordforms.txt用来将不同形式的词形编程单一的标准形式,如:microsoft、ms、微软 变成同一的形式 microsoft。格式是:
ms > microsoft微软 > microsoft
目标词形 microsoft 只能是单个词,比如:
zhang san > 张三查询 chang san 的时候,只匹配张,就是说只要是含有 张 字的都匹配,无论是张三还是张四。
一元切分模式
有时候使用一元切分模式,反而降低的搜索的准确率。比如我在搜索 小小 时,使用一元分词后,凡是含有 小 字的内容都被搜索出来了。显然不是我们想要的。
如果不想启动一元分词时,charset_type = utf-8,要改成 charset_type = zh_cn.utf-8,否则是搜出去东西来的。
sphnix 的匹配模式
- SPH_MATCH_ALL:匹配所有查询词,这是 sphinx 的默认模式,比如搜索:中国,那么只有文档中同时出现 中国 二字时才会匹配,当然 中国 可以不出现在一块。
- SPH_MATCH_ANY:匹配任意一个
- SPH_MATCH_PHRASE
数据源的一些限制条件
document 的 id 必须是唯一的无符号的非 0 的整数,直白点就是要大于 0 的整数,至于是 32 位还是 64 位的根据自己的喜好设定。我们的线上环境就有一个 id 为 -1 的数据,搜不出来,该主键是非常麻烦的,所以在新建数据的时候就要特别注意。
BuildExcerpts 产生文本摘要和高亮
function BuildExcerpts ( $docs, $index, $words, $opts = array() )docs:包含文档内容的数组
index:索引
words:需要高亮的字符串
opts:字典类型
以上是 sphinx-coreseek 优化指南 的全部内容, 来源链接: utcz.com/p/233288.html