MySQL 到底是如何做到多版本并发的
MySQL 多版本并发
一、多版本并发控制
我们知道,读未提交会造成脏读、幻读、不可重复读,读已提交会造成幻读、不可重复读,可重复读可能会有幻读,和串行化就不会有这些问题。
那 InnoDB 到底是怎么解决这些问题的呢?又或者,你有没有想过造成脏读、幻读、不可重复读的底层最根本的原因是什么呢?
这就是今天要聊的主角——MVCC(Multi-Version Concurrent Controll),也叫多版本并发控制。InnoDB 是一个支持多事务并发的存储引擎,它能让数据库中的读-写操作能够并发的进行,避免由于加锁而导致读阻塞。
正是由于有了 MVCC,在事务B更新 id=1 的数据时,事务A读取 id=1 的操作才不会被阻塞。而不阻塞的背后则是不加锁的一致性读。那什么是一致性读?
1、一致性读
简单来讲,当进行 query 查询时,InnoDB 会对当前时间点的数据库创建一个快照,快照创建完之后,当前查询就只能感知到快照创建之前提交的事务改动,在快照创建之后再提交的事务就不会被当前query感知。
当然,当前事务自己更新的数据是个例外。当前事务修改过的行,再次读取时是能够拿到最新的数据的。而对于其他行,读取的仍然是打快照时的版本。
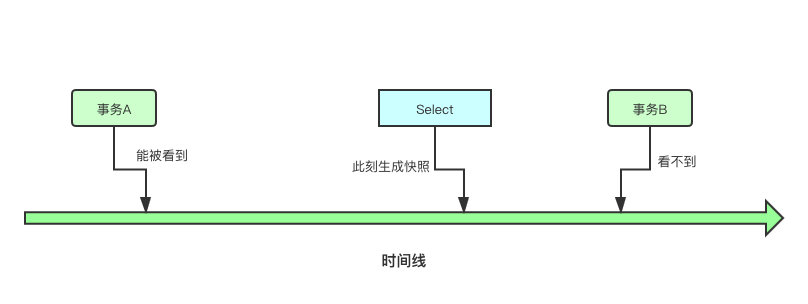
而这个快照就是 InnoDB 实现事务隔离级别的关键。
在读已提交(Read Committed)的隔离级别下,事务中的每一次的一致性读都会重新生成快照。而在可重复读(Repeatable Read)的隔离级别下,事务中所有的一致性读都只会使用第一次一致性读生成的快照。
这也就是为什么,在上图中事务B提交了事务之后,读已提交的隔离级别下能看到改动,可重复读的隔离级别看不到改动,本质上就是因为读已提交又重新生成了快照。
在读已提交、可重复读的隔离级别下,SELECT 语句都会默认走一致性读,并且在一致性读的场景下,不会加任何的锁。其他的修改操作也可以同步的进行,大大的提升了 MySQL 的性能。而这也就是MVCC多版本并发控制的实现原理。这种读还有个名字叫 快照读 。
那如果我在事务中想要立马看到其他的事务的提交怎么办?有两种方法:
(1)使用读已提交隔离级别
(2)对 SELECT 加锁,共享锁和排他锁都行,再具体点就是 FOR SHARE 和 FOR UPDATE
当然,第二种方法如果对应的记录加的锁和 SELECT 加的锁互斥,SELECT 就会被阻塞,这种读也有个别名叫 当前读。
了解完上面的解释,下次再有人问你 MVCC 是怎么实现的,你就能从一致性读(快照读)和当前读来进行解释了,并且把不同的隔离级别下对一致性读快照的刷新机制也讲清楚。
但是我觉得还不够,应该还需要继续往下深入了解。因为我们只知道个快照,其底层到底是怎么实现的呢?其实还是不知道的。
2、深入一致性读原理
从常理来说,不同的一致性读可能会读到不同版本的数据,那么这些肯定都存储在 MySQL 中的,否则不可能被读取到。是的,这些数据都存储在 InnoDB 的表空间内,再具体点这些数据存储在 Undo 表空间内。
InnoDB 内实现 MVCC 的关键其实就是三个字段,并且数据表中每一行都有这三个字段:
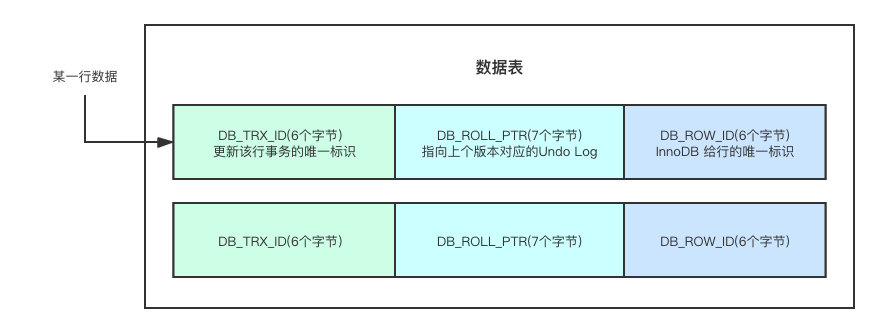
- DB_TRX_ID 该字段有6个字节,用于存储上次插入或者更新该行数据的事务的唯一标识。你可能会问,只有插入和更新吗?那删除呢?其实在InnoDB的内部,删除其实就是更新操作,只不过会更新该行中一个特定的比标志位,将其标记为删除。
- DB_ROLL_PTR 该字段有7个字节,你可以叫它回滚指针,该指针指向了存储在回滚段中的一条具体的Undo Log。即使当前这行数据被更新了,我们同样的可以通过回滚指针,拿到更新之前的历史版本数据。
- DB_ROW_ID 该字段有6个字节,InnoDB给该行数据的唯一标识,该唯一标识会在有新数据插入的时候单调递增,就跟我们平时定义表结构的时候定义的primary key的时候单调递增是一样的。DB_ROW_ID会被包含在聚簇索引中,其他的非聚簇索引则不会包含。
通过 DB_ROLL_PTR 可以拿到最新的一条 Undo Log,然后每一个对应的 Undo Log 指向其上一个 Undo Log,这样一来,不同的版本就可以连接起来形成链表,不同的事务根据需求和规则,从链表中选择不同的版本进行读取,从而实现多版本的并发控制,如下图:
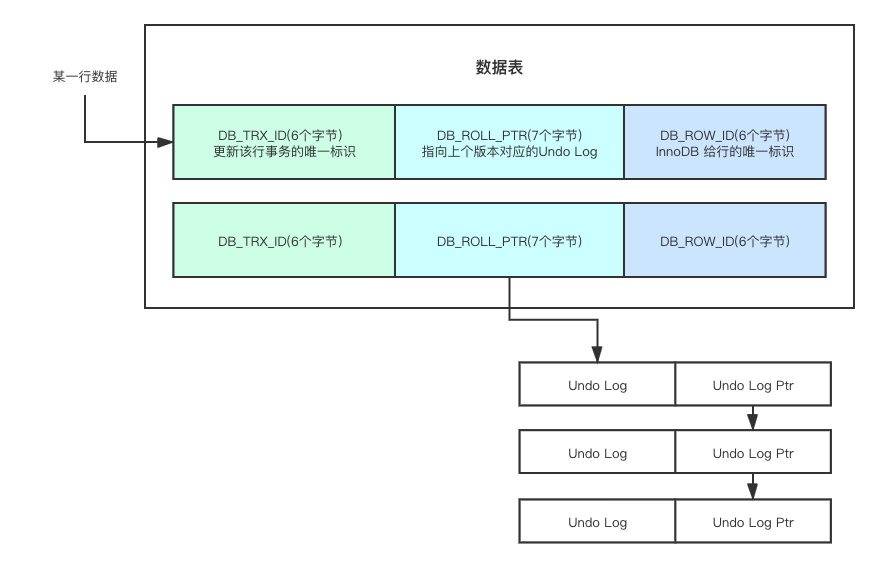
可能有人对 Undo Log 没啥概念,记住这个就好了:
Undo Log 记录的是此次事务开始前的数据状态,就有点类似于 Git 中的某个 commit,你提交了某个 commit, 然后开始做一个及其复杂的需求,然后做着做着心态就崩了,就不想要这些改动了,你就可以直接 git reset --hard $last_commit_id 回退,上个 commit 你就可以理解为 Undo Log,感兴趣的可以去看看 基于Redo Log和Undo Log的MySQL崩溃恢复流程
二、Undo Log 的组成
可能也有人会有疑问,说 Undo Log 不是应该在事务提交之后就被删除了吗?为什么我通过 MVCC 还能查到之前的数据呢?
实际上在 InnoDB 中,Undo Log 被分成了两部分,分别是
- Insert Undo Log
- Update Undo Log
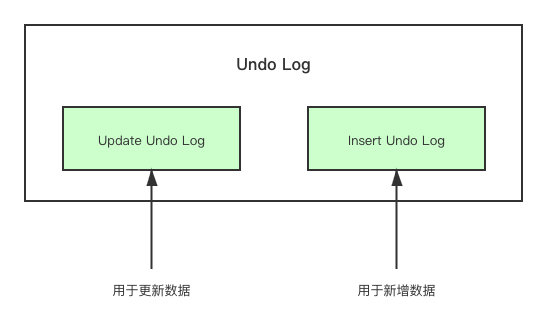
对于 Insert Undo Log 来说,它只会用于在事务中发生错误的回滚,因为一旦事务提交了,Insert Undo Log 就完全没用了,所以在事务提交之后 Insert Undo Log 就会被删除。
而 Update Undo Log 不同,其可以用于 MVCC 的一致性读,为不同版本的请求提供数据源。那这样一来,是不是 Update Undo Log 就完全没法移除了?因为你不清楚啥时候就会有个一致性读请求过来,然后导致其占用的空间越来越大。
对,但也不完全对。
一致性读本质上是要处理多事务并发时,需要按需给不同的事务以不同的数据版本,所以如果当前没有事务存在了,Update Undo Log 就可以被干掉了
到此这篇关于MySQL 到底是如何做到多版本并发的?的文章就介绍到这了,更多相关MySQL多版本并发内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 MySQL 到底是如何做到多版本并发的 的全部内容, 来源链接: utcz.com/p/231506.html