一次mysql迁移的方案与踩坑实战记录
背景
由于历史业务数据采用mysql来存储的,其中有一张操作记录表video_log,每当用户创建、更新或者审核人员审核的时候,对应的video_log就会加一条日志,这个log表只有insert,可想而知,1个video对应多条log,一天10w video,平均统计一个video对应5条log,那么一天50w的log, 一个月50 * 30 = 1500w条记录, 一年就是1500 * 12 = 1.8亿。目前线上已经有2亿多的数据了,由于log本身不面向C端,用于查询问题的,所以可以忍受一点的延迟。 但是随着时间的积累,必然会越来越慢,影响效率,于是提出改造。

方案一:老数据备份
由于log本身不是最关键的数据,但是也要求实时性高(用于实时查询问题),所以一开始的想法是核心的基础存储还是保持不变,较老的数据迁移出去,毕竟突然去查询一年前的操作记录的概率很小,如果突然要查,可以走离线。设计的话,我们只需要一个定时脚本,每天在凌晨4点左右(业务低峰期)抽数据。抽出的数据可以上报到一些离线存储(一般公司都有基于hive的数仓之类的),这样就可以保持线上的video_log的数据不会一直增长。

方案二:分表
分表也是一种解决方案,相对方案一的好处就是,所有的数据都支持实时查,缺点是代码要改造了。
- 首先确认sharding key,因为video_log是和video绑定的,所以自然而然选择video_id作为我们的sharding key
- 按什么分表确定了,接下来确认下分多少张表。先定个小目标,支撑3年。每张表最大数据量为1个亿(由于我们的查询简单),按照上面的统计,我们3年大概:3*1.8=5.4亿,那么大概需要5.4/1≈6张表。
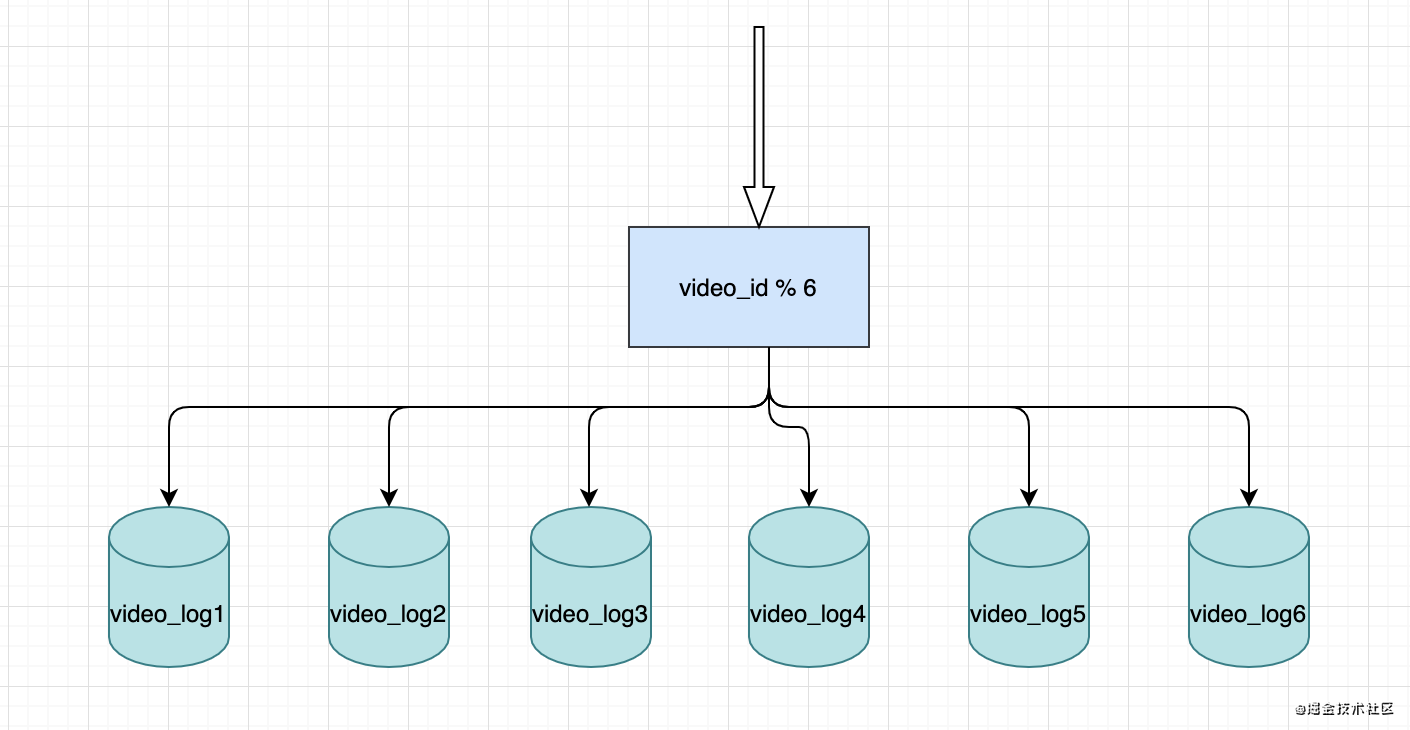
接下来就是改造代码了,得解决新老数据读写的问题。
- 新数据的插入直接插入新表
- 由于log表只有insert,所以不存在update、delete这些操作,不需要考虑这些场景。
- 分表后,一个video的log存在两张表(老表和新表),所以临时两张表都查,然后做个合并
- 同步老数据到新表中
- 下线读取老表的代码

方案三:迁移至tidb
方案二的缺点比较明显,3年后咋办,继续拆表?感觉始终有个历史债在那。于是我们的目光定位到了tidb,tidb是分布式的数据库,接入了tidb,我们就无需关心分表了,这些tidb都帮我们做了,它会自己做节点的扩容。由于是分布式的,所以tidb的主键是无序的,这点很重要。
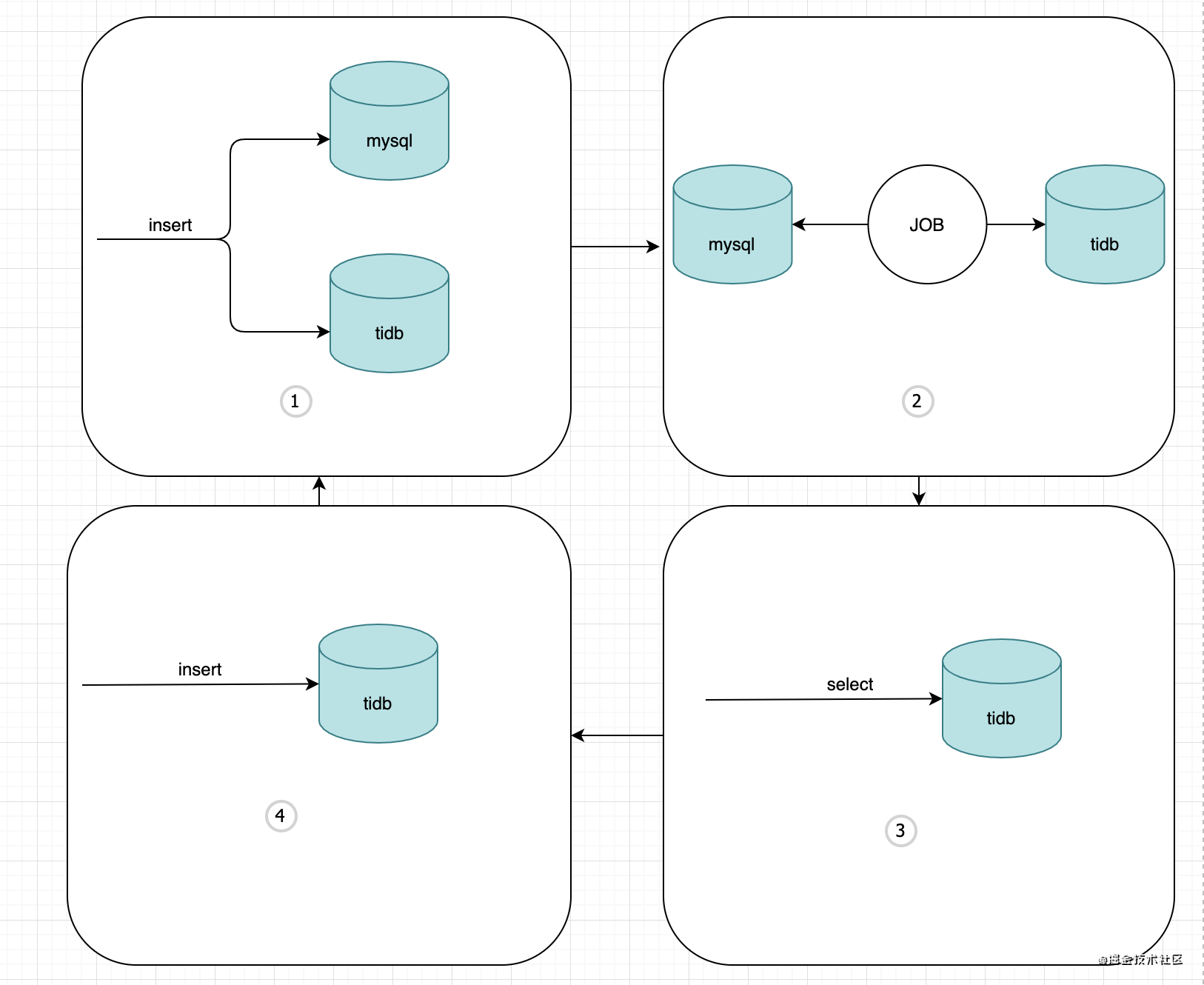
整个流程大概分为以下4个步骤:
- 先双写(记录下刚开始双写时的mysql的id,在此id前的肯定都是老数据)
- 同步老数据(通过第一步记录的id来区分)
- 切读(老数据同步完了)
- 下双写
重点说下同步老数据遇到的坑
迁移至tidb,看似很简单,其实在job脚本这里隐藏着几个坑。
- 要考虑万一job中途断了,重新启动咋办,撇开重头跑数据的时间成本,已经同步的数据重新跑会重复,还要考虑重复数据的问题。解决重复数据的问题,可以对老表新加一个字段标识是否已同步,每次同步完,更新下字段。缺点:线上数据大,加个字段不太安全,可能造成线上阻塞。
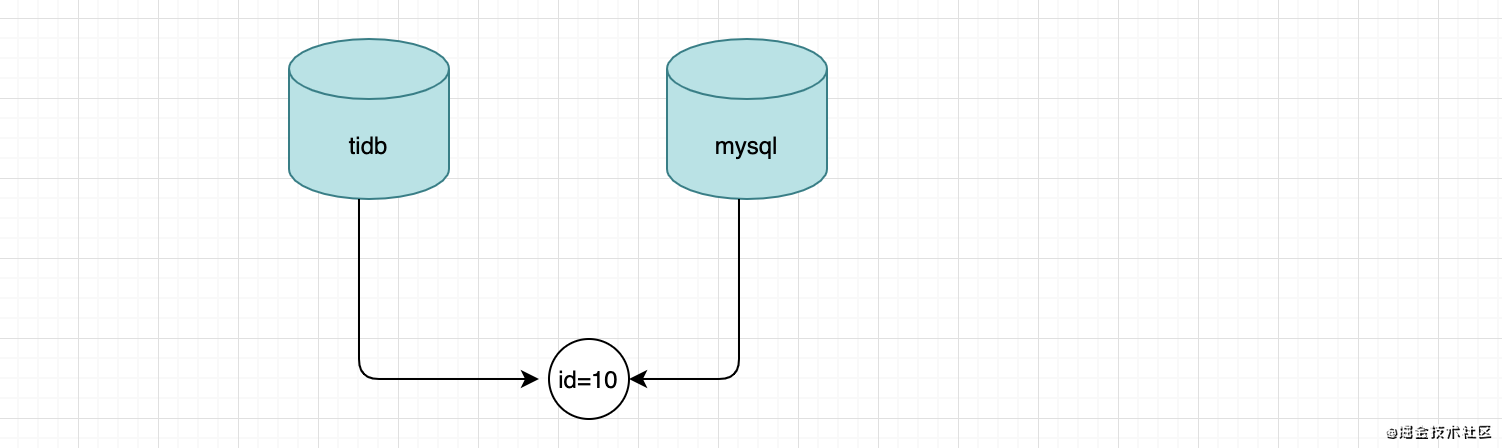
- 既然加个字段不好,那就用现有的主键id做约束,把主键id也同步过去,这样就算脚本重启,从头开始跑的,也因为相同的主健已经插入过,那么就会报错跳过。看似很完美,然而tidb是分布式的,主键id不是连续的,那么可能出现这样一种情况。正常的业务数据插入tidb,tidb分配的主键id和mysql同步的主键id重复,那么不管是谁,最后插入的那一条肯定是失败的。
最终同步脚本方案
综合考虑数据的重复性,job重启效率性,和整个同步的效率性,我大概做出以下方案:
- 任务分批提升效率:首先根据处理能力和预期完成时间,先对老数据进行分批,大概分了10批,10个job去跑不同批次的数据,互不干扰,且每次批量更新100条。
- 记录状态,重启自动恢复到断点:每次同步数据后记录下当前同步的位置(redis记录下当前的id),就算重启也可以从redis里拿到之前的更新位置,接着更新。
- 避免主键冲突:同步除了主键之外的所有字段(不同步主键)
最终通过方案三的四个切换步骤+高效率的同步脚本平稳的完成了数据的迁移
总结
到此这篇关于mysql迁移的方案与踩坑的文章就介绍到这了,更多相关mysql迁移方案与踩坑内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 一次mysql迁移的方案与踩坑实战记录 的全部内容, 来源链接: utcz.com/p/231453.html