初学者从源码理解MySQL死锁问题
通过好多个深夜艰难的单步调试,终于找到了一个理想的断点,可以看到大部分获取锁的过程
代码在lock0lock.c的static enum db_err lock_rec_lock() 函数中,这个函数会显示,获取锁的过程,以及获取锁成功与否。
场景1:通过主键进行删除
表结构
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
delete from t1 where id = 10;
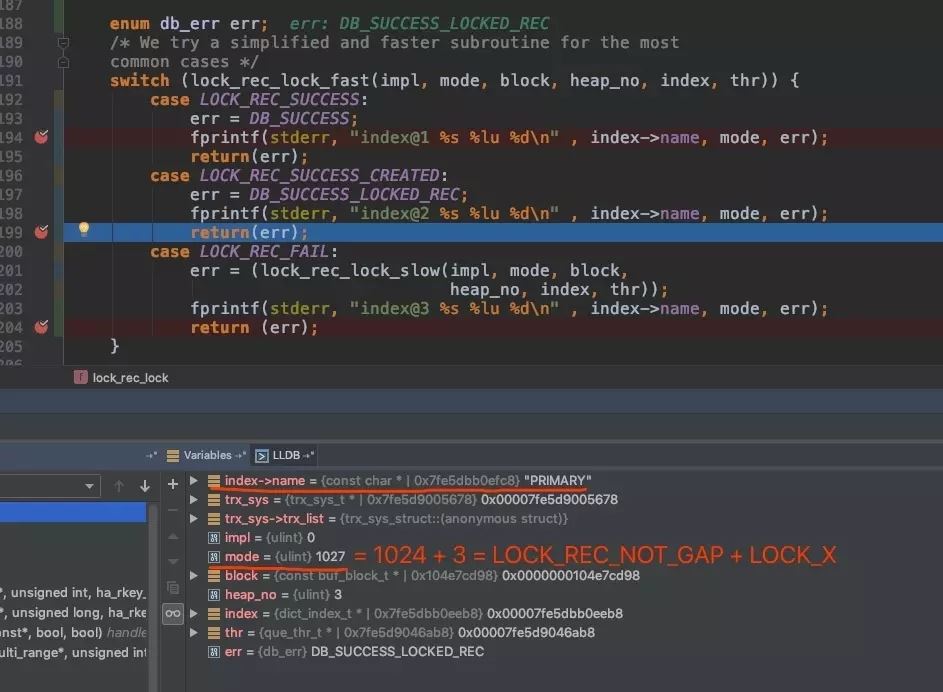
可以看到,对索引 PRIMARY 加锁,mode = 1027,1027是什么意思呢?1027 = LOCK_REC_NOT_GAP + LOCK_X(非 gap 的记录锁且是 X 锁)
过程如下
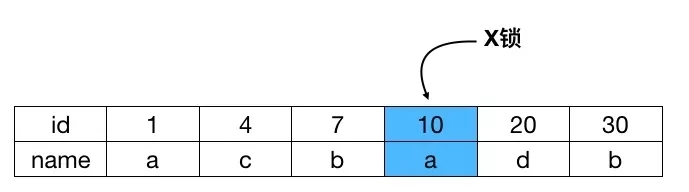
结论:根据主键 id 去删除数据,且没有其它索引的情况下,此 SQL 只需要在 id = 10 这条记录上对主键索引加 X 锁即可
场景2:通过唯一索引进行删除
表结构做了微调,增加了 name 的唯一索引
构造数据
CREATE TABLE `t2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_name` (`name`)
) ;
INSERT INTO `t2` (`id`, `name`) VALUES
(1,'M'),
(2,'Y'),
(3,'S'),
(4,'Q'),
(5,'L');
测试sql语句
delete from t2 where name = "Y"
来看实际源码调试的结果
第一步:
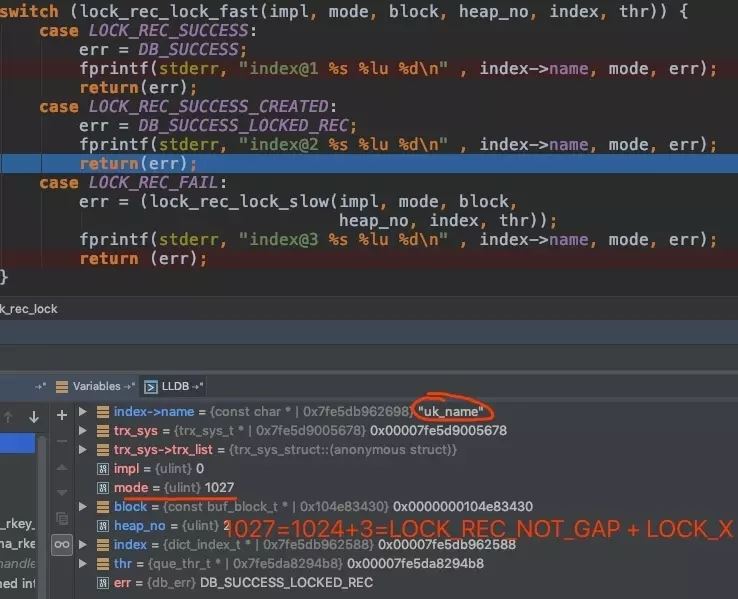
第二步:
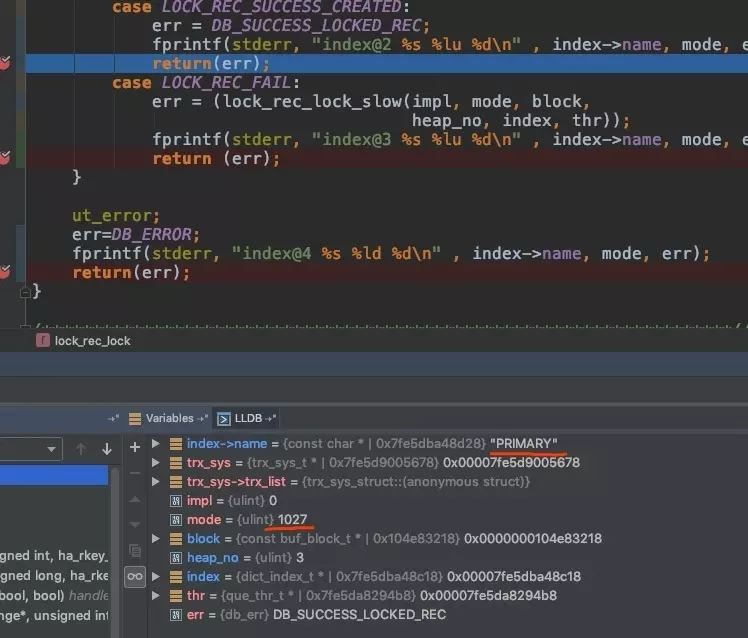
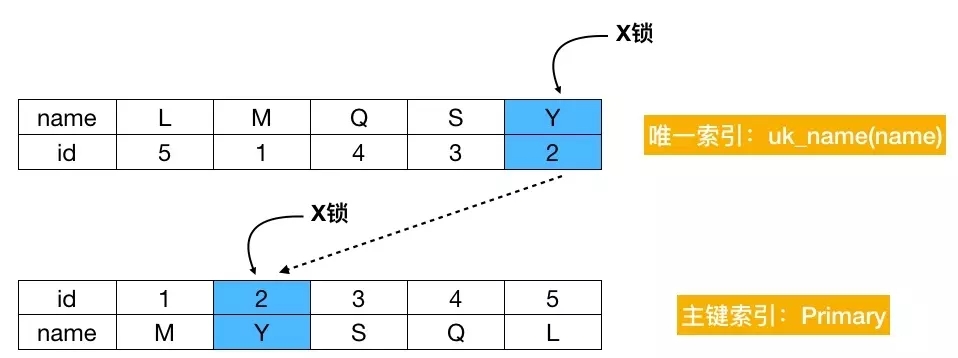
结论:这个过程是先对唯一键 uk_name 加 X 锁,然后再对聚簇索引(主键索引)加 X 锁
过程如下
场景3:通过普通索引进行删除
构造数据
CREATE TABLE `t3` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
);
INSERT INTO `t3` (`id`, `name`) VALUES
(1,'N'),
(2,'G'),
(3,'I'),
(4,'N'),
(5,'X');
测试语句:
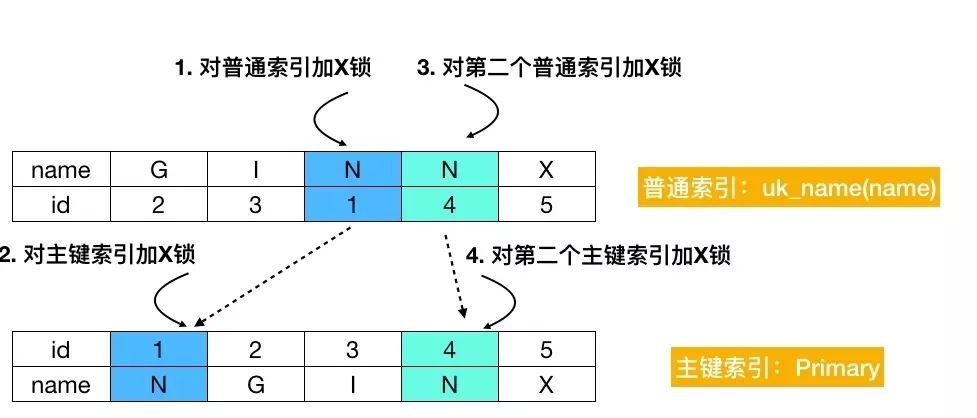
delete from t3 where name = "N";
调试过程如图:
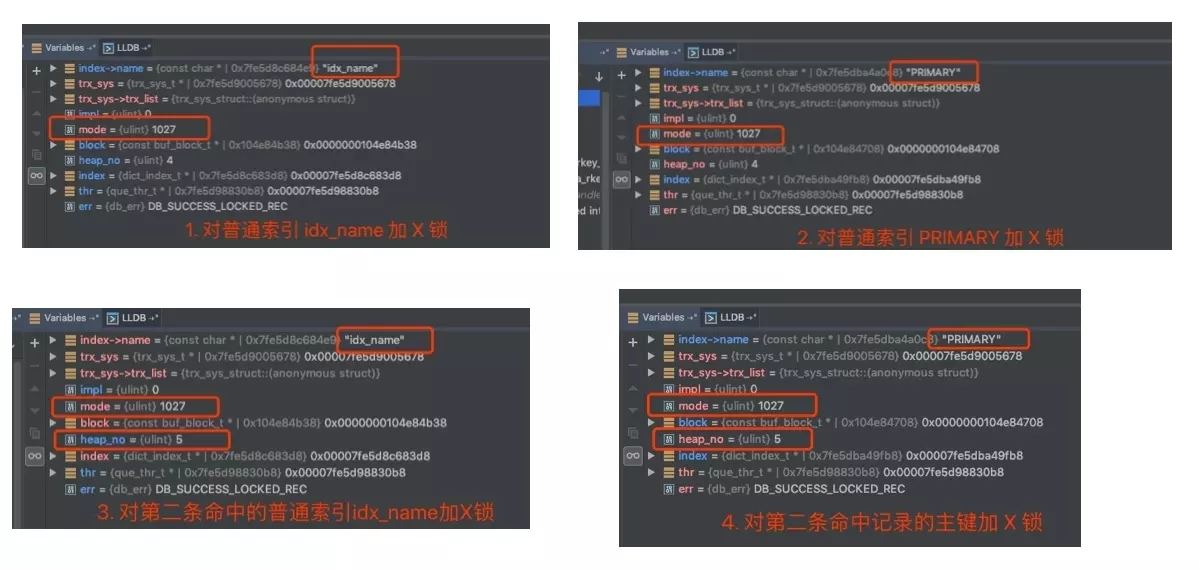
结论:通过普通索引进行更新时,会对满足条件的所有普通索引加 X 锁,同时会对相关的主键索引加 X 锁
过程如下
场景4:不走索引进行删除
CREATE TABLE `t4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
)
INSERT INTO `t4` (`id`, `name`) VALUES
(1,'M'),
(2,'Y'),
(3,'S'),
(4,'Q'),
(5,'L');
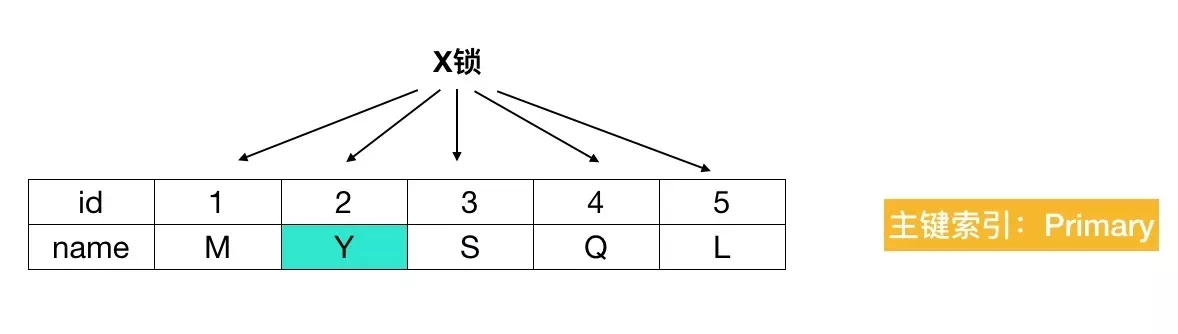
delete from t4 where name = "S";
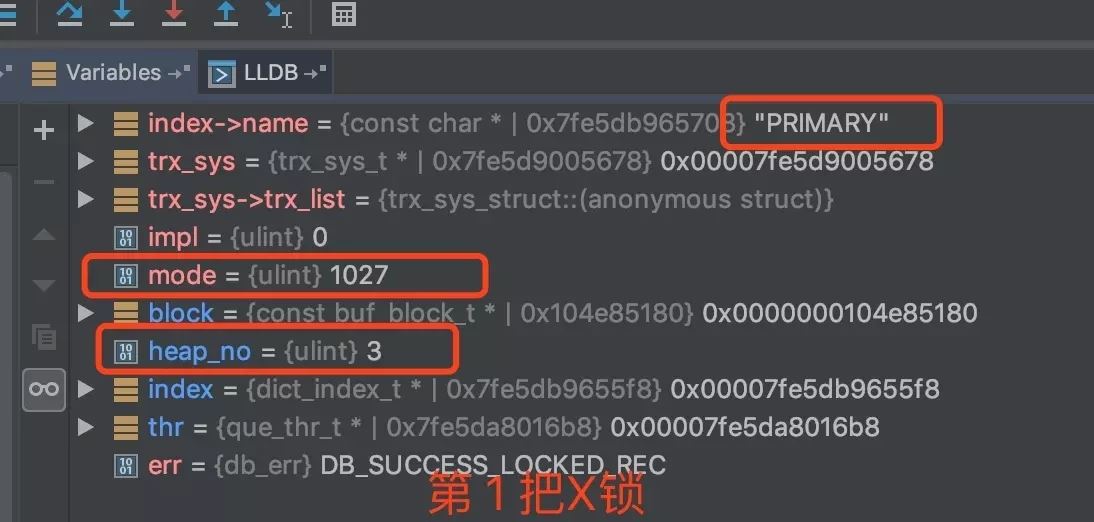
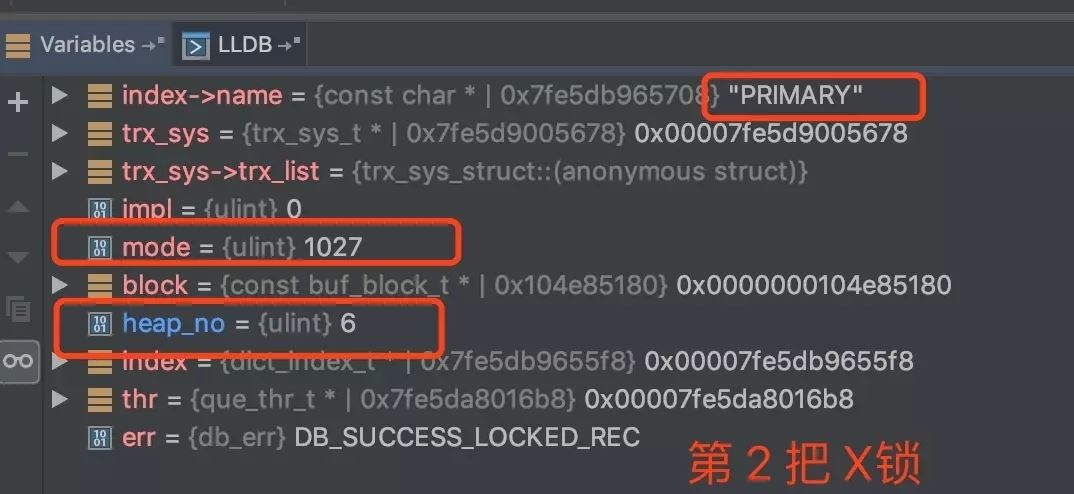
总共有 5 把 X 锁,剩下的 3 把就不一一放上来了
结论:不走索引进行更新时,sql 会走聚簇索引(主键索引)对全表进行扫描,因此每条记录,无论是否满足条件,都会被加上X锁。还没完...
但是为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。
过程如下
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
以上是 初学者从源码理解MySQL死锁问题 的全部内容, 来源链接: utcz.com/p/229638.html