Mysql InnoDB引擎的索引与存储结构详解
前言
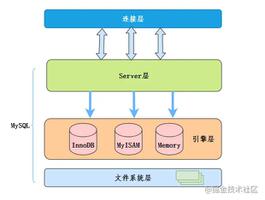
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。
而MySql数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。
MySQL主要存储引擎的区别
MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE、MEMORY(HEAP)等。
主要的几个存储引擎
MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力。
MyISAM是Mysql的默认存储引擎。当create创建新表时,未指定新表的存储引擎时,默认使用MyISAM。每个MyISAM在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是.frm(存储表定义)、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。数据文件和索引文件可以放置在不同的目录,平均分布io,获得更快的速度。
InnoDB存储引擎用于事务处理应用程序,具有众多特性,包括ACID事务支持,提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
Memory将所有数据保存在内存中,可以应用于临时表中在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。Memory使用哈希索引,所以数据的存取速度非常快。
Merge允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
不同存储引擎的横向对比
| 特点 | MyISAM | BDB | Memory | InnoDB |
|---|---|---|---|---|
| 存储限制 | 没有 | 没有 | 有 | 64TB |
| 事务安全 | 支持 | 支持 | ||
| 锁机制 | 表锁 | 页锁 | 表锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | 支持 | ||
| 全文索引 | 支持 | |||
| 集群索引 | 支持 | |||
| 数据缓存 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | |
| 数据可压缩 | 支持 | |||
| 空间使用 | 低 | 低 | N/A | 高 |
| 内存使用 | 低 | 低 | 中等 | 高 |
| 批量插入的速度 | 高 | 高 | 高 | 低 |
| 支持外键 | 支持 |
查看和配置存储引擎的操作
1.用show engines; 命令可以显示当前数据库支持的存储引擎情况;
2.要查看表的定义结构等信息可以使用以下几种命令:
Desc[ribe] tablename; //查看数据表的结构
Show create table tablename; //显示表的创建语句,可以查看创建表时指定的ENGINE
show table status like ‘tablename'\G显示表的当前状态值
3.设置或修改表的存储引擎
创建数据库表时设置存储存储引擎的基本语法是:
Create table tableName(
columnName(列名1) type(数据类型) attri(属性设置),
columnName(列名2) type(数据类型) attri(属性设置),
……..) engine = engineName
修改存储引擎,可以用命令
Alter table tableName engine =engineName
对于整个服务器或方案,你并不一定要使用相同的存储引擎,可以为方案中的每个表使用不同的存储引擎。
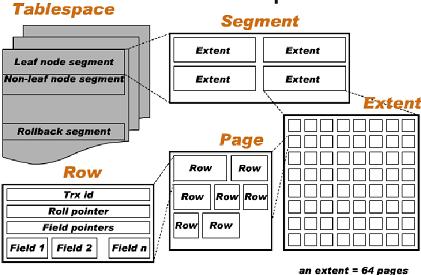
InnoDB的存储结构
InnoDB使用页面存储结构,下面是InnoDB的表空间结构图:
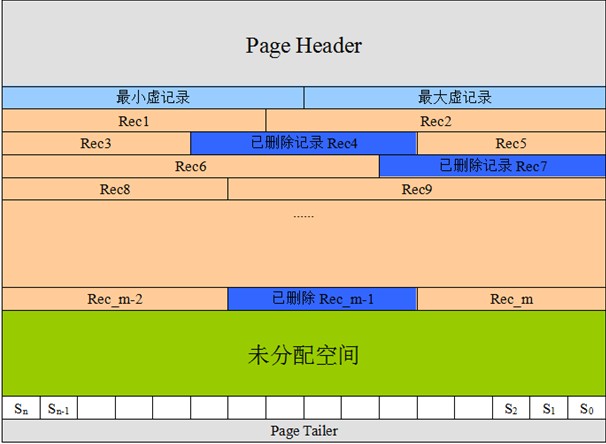
Page页面存储格式如下图所示:
一个页面的存储由以下几部分组成:
- 页头(Page Header):记录页面的控制信息,共占150字节,包括页的左右兄弟页面指针、页面空间使用情况等,页头的详细说明会在下一篇中描述。
- 最小虚记录、最大虚记录:两个固定位置存储的虚记录,本身并不存储数据。最小虚记录比任何记录都小,而最大虚记录比任何记录都大。
- 记录堆(record heap):指上图的橙黄色部分。表示页面已分配的记录空间,也是索引数据的真正存储区域。记录堆分为两种,即有效记录和已删除记录。有效记录就是索引正常使用的记录,而已删除记录表示索引已经删除,不在使用的记录,如上图的深蓝色部分。随着记录的更新和删除越来越频繁,记录堆中已删除记录将会越多,即会出现越来越多的空洞(碎片)。这些已删除记录连接起来,就会成为页面的自由空间链表。
- 未分配空间:指页面未使用的存储空间,随着页面不断使用,未分配空间将会越来越小。当新插入一条记录时,首先尝试从自由空间链表中获得合适的存储位置(空间足够),如果没有满足的,就会在未分配空间中申请。
- slot区:slot是一些页面有效记录的指针,每个slot占两个字节,存储了记录相对页面首地址的偏移。如果页面有n条有效记录,那么slot的数量就在n/8+2~n/4+2之间。下一节详细介绍slot区,它是记录页面有序和二分查找的关键。
- 页尾(Page Tailer):页面最后部分,占8个字节,主要存储页面的校验信息。
页面中的页头,最大/最小虚记录以及页尾都是页面中有固定的存储位置。
InnoDB的索引结构
InnoDB使用B+Tree的方式存储索引。
Innodb的一个表可能包含多个索引,每个索引都使用B+树来存储。而索引包括聚集索引和二级索引,聚集索引使用表的主键作为索引键,包含表的所有字段。二级索引只包含索引键和聚集索引键(主键)的内容,不包括其他字段。每一个索引都是一棵B+树,每棵B+树由很多页面组成,而每个页面大小一般为16K。从B+树的组织结构来看,B树的页面可分为:
叶子节点:B树层次为0的页面,存储记录的所有内容。
非叶子节点:B树层次大于0的页面,只存储索引键和页面指针。
一棵典型的B+树结构:
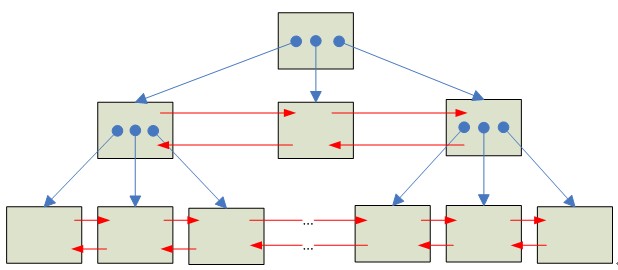
从上图可知,相同层次的页面是用一个双向链表连接起来的。
一般情况下,从B+树的最左边叶子节点开始,一直向右扫描,就可以得到B+树的从小到大的所有数据。因此,对于叶子节点,有如下特征:
页内数据是按索引键排序的。
页面的任一记录的索引键值不小于其左兄弟页面的任何记录。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
以上是 Mysql InnoDB引擎的索引与存储结构详解 的全部内容, 来源链接: utcz.com/p/229329.html