Nodejs探秘之深入理解单线程实现高并发原理
前言
从Node.js进入我们的视野时,我们所知道的它就由这些关键字组成 事件驱动、非阻塞I/O、高效、轻量,它在官网中也是这么描述自己的。
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient.
于是在我们刚接触Nodejs时,会有所疑问:
1、为什么在浏览器中运行的Javascript能与操作系统进行如此底层的交互?
2、nodejs 真的是单线程吗?
3、如果是单线程,他是如何处理高并发请求的?
4、nodejs 事件驱动是如何实现的?
看到这些问题,是否有点头大,别急,带着这些问题我们来慢慢看这篇文章。
架构一览
上面的问题,都挺底层的,所以我们从 Node.js 本身入手,先来看看 Node.js 的结构。
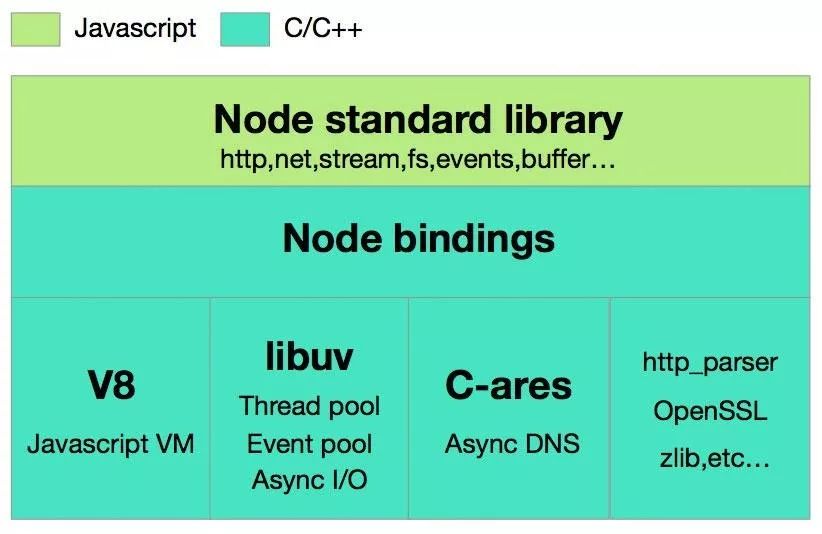
Node.js 标准库,这部分是由 Javascript编写的,即我们使用过程中直接能调用的 API。在源码中的 lib 目录下可以看到。
Node bindings,这一层是 Javascript与底层 C/C++ 能够沟通的关键,前者通过 bindings 调用后者,相互交换数据。实现在 node.cc
这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。
V8:Google 推出的 Javascript VM,也是 Node.js 为什么使用的是 Javascript的关键,它为 Javascript提供了在非浏览器端运行的环境,它的高效是 Node.js 之所以高效的原因之一。
Libuv:它为 Node.js 提供了跨平台,线程池,事件池,异步 I/O 等能力,是 Node.js 如此强大的关键。
C-ares:提供了异步处理 DNS 相关的能力。
http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、数据压缩等其他的能力。
与操作系统交互
举个简单的例子,我们想要打开一个文件,并进行一些操作,可以写下面这样一段代码:
var fs = require('fs');fs.open('./test.txt', "w", function(err, fd) { //..do something});
这段代码的调用过程大致可描述为:lib/fs.js → src/node_file.cc → uv_fs
lib/fs.js
async function open(path, flags, mode) { mode = modeNum(mode, 0o666); path = getPathFromURL(path);
validatePath(path);
validateUint32(mode, 'mode');
return new FileHandle(
await binding.openFileHandle(pathModule.toNamespacedPath(path),
stringToFlags(flags), mode, kUsePromises));
}
src/node_file.cc
static void Open(const FunctionCallbackInfo& args) { Environment* env = Environment::GetCurrent(args); const int argc = args.Length(); if (req_wrap_async != nullptr) { // open(path, flags, mode, req) AsyncCall(env, req_wrap_async, args, "open", UTF8, AfterInteger,
uv_fs_open, *path, flags, mode);
} else { // open(path, flags, mode, undefined, ctx) CHECK_EQ(argc, 5); FSReqWrapSync req_wrap_sync; FS_SYNC_TRACE_BEGIN(open); int result = SyncCall(env, args[4], &req_wrap_sync, "open",
uv_fs_open, *path, flags, mode); FS_SYNC_TRACE_END(open);
args.GetReturnValue().Set(result);
}
}
uv_fs
/* Open the destination file. */
dstfd = uv_fs_open(NULL, &fs_req,
req->new_path,
dst_flags,
statsbuf.st_mode, NULL);
uv_fs_req_cleanup(&fs_req);
Node.js 深入浅出上的一幅图:
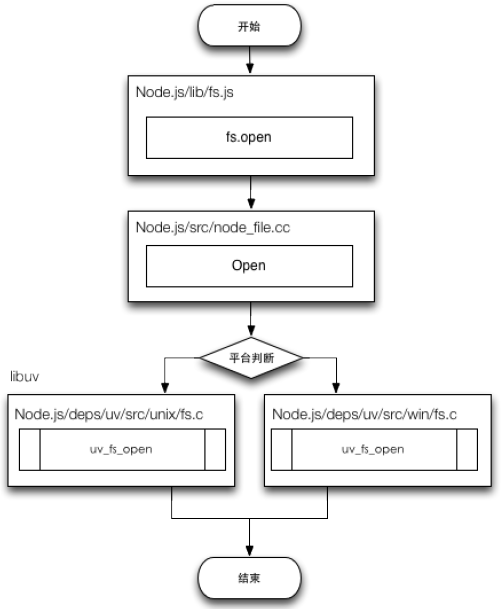
具体来说,当我们调用 fs.open 时,Node.js 通过 process.binding 调用 C/C++ 层面的 Open 函数,然后通过它调用 Libuv 中的具体方法 uv_fs_open,最后执行的结果通过回调的方式传回,完成流程。
我们在 Javascript中调用的方法,最终都会通过 process.binding 传递到 C/C++ 层面,最终由他们来执行真正的操作。Node.js 即这样与操作系统进行互动。
单线程
在传统web 服务模型中,大多都使用多线程来解决并发的问题,因为I/O 是阻塞的,单线程就意味着用户要等待,显然这是不合理的,所以创建多个线程来响应用户的请求。
Node.js 对http 服务的模型:
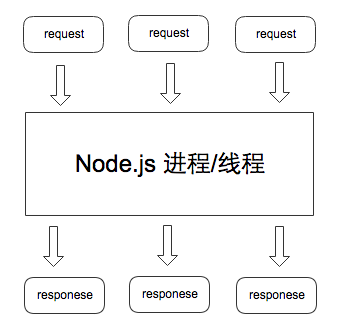
Node.js的单线程指的是主线程是“单线程”,由主要线程去按照编码顺序一步步执行程序代码,假如遇到同步代码阻塞,主线程被占用,后续的程序代码执行就会被卡住。实践一个测试代码:
var http = require('http');function sleep(time) { var _exit = Date.now() + time * 1000; while( Date.now() < _exit ) {} return ;
}var server = http.createServer(function(req, res){
sleep(10);
res.end('server sleep 10s');
});
server.listen(8080);
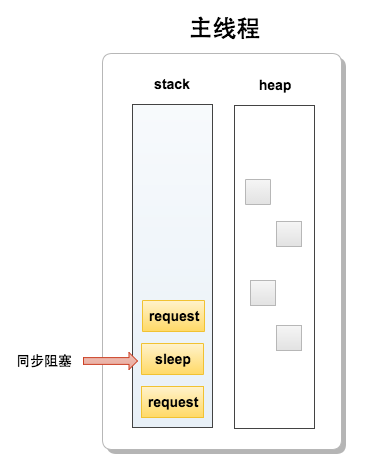
下面为代码块的堆栈图:
先将index.js的代码改成这样,然后打开浏览器,你会发现浏览器在10秒之后才做出反应,打出Hello Node.js。
JavaScript是解析性语言,代码按照编码顺序一行一行被压进stack里面执行,执行完成后移除然后继续压下一行代码块进去执行。上面代码块的堆栈图,当主线程接受了request后,程序被压进同步执行的sleep执行块(我们假设这里就是程序的业务处理),如果在这10s内有第二个request进来就会被压进stack里面等待10s执行完成后再进一步处理下一个请求,后面的请求都会被挂起等待前面的同步执行完成后再执行。
那么我们会疑问:为什么一个单线程的效率可以这么高,同时处理数万级的并发而不会造成阻塞呢?就是我们下面所说的--------事件驱动。
事件驱动/事件循环
Event Loop is a programming construct that waits for and dispatches events or messages in a program.
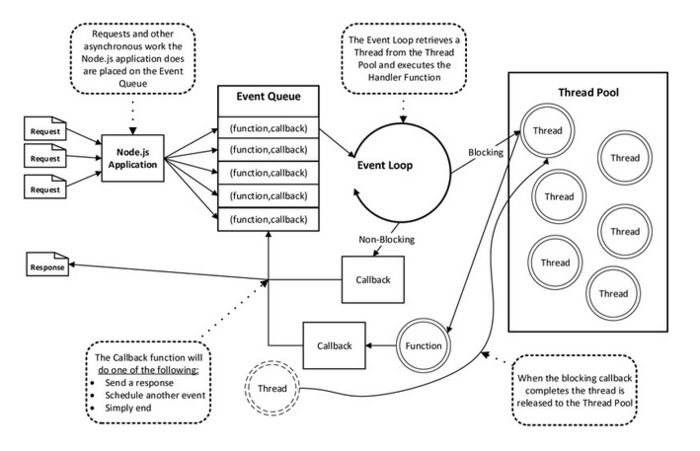
1、每个Node.js进程只有一个主线程在执行程序代码,形成一个执行栈(execution context stack)。
2、主线程之外,还维护了一个"事件队列"(Event queue)。当用户的网络请求或者其它的异步操作到来时,node都会把它放到Event Queue之中,此时并不会立即执行它,代码也不会被阻塞,继续往下走,直到主线程代码执行完毕。
3、主线程代码执行完毕完成后,然后通过Event Loop,也就是事件循环机制,开始到Event Queue的开头取出第一个事件,从线程池中分配一个线程去执行这个事件,接下来继续取出第二个事件,再从线程池中分配一个线程去执行,然后第三个,第四个。主线程不断的检查事件队列中是否有未执行的事件,直到事件队列中所有事件都执行完了,此后每当有新的事件加入到事件队列中,都会通知主线程按顺序取出交EventLoop处理。当有事件执行完毕后,会通知主线程,主线程执行回调,线程归还给线程池。
4、主线程不断重复上面的第三步。
我们所看到的node.js单线程只是一个js主线程,本质上的异步操作还是由线程池完成的,node将所有的阻塞操作都交给了内部的线程池去实现,本身只负责不断的往返调度,并没有进行真正的I/O操作,从而实现异步非阻塞I/O,这便是node单线程和事件驱动的精髓之处了。
Node.js 中的事件循环**的实现:**
Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现。 在src/node.cc中:
Environment* CreateEnvironment(IsolateData* isolate_data,
Local context, int argc, const char* const* argv, int exec_argc, const char* const* exec_argv) {
Isolate* isolate = context->GetIsolate(); HandleScope handle_scope(isolate);
Context::Scope context_scope(context); auto env = new Environment(isolate_data, context,
v8_platform.GetTracingAgent());
env->Start(argc, argv, exec_argc, exec_argv, v8_is_profiling); return env;
}
这段代码建立了一个node执行环境,可以看到第三行的uv_default_loop(),这是libuv库中的一个函数,它会初始化uv库本身以及其中的default_loop_struct,并返回一个指向它的指针default_loop_ptr。 之后,Node会载入执行环境并完成一些设置操作,然后启动event loop
{
SealHandleScope seal(isolate);
bool more;
env.performance_state()->Mark(
node::performance::NODE_PERFORMANCE_MILESTONE_LOOP_START);
do {
uv_run(env.event_loop(), UV_RUN_DEFAULT);
v8_platform.DrainVMTasks(isolate);
more = uv_loop_alive(env.event_loop()); if (more)
continue;
RunBeforeExit(&env); // Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env.event_loop());
} while (more == true);
env.performance_state()->Mark(
node::performance::NODE_PERFORMANCE_MILESTONE_LOOP_EXIT);
}
env.set_trace_sync_io(false);
const int exit_code = EmitExit(&env);
RunAtExit(&env);
more用来标识是否进行下一轮循环。 env->event_loop()会返回之前保存在env中的default_loop_ptr,uv_run函数将以指定的UV_RUN_DEFAULT模式启动libuv的event loop。如果当前没有I/O事件也没有定时器事件,则uv_loop_alive返回false。
Event Loop的执行顺序
根据Node.js官方介绍,每次事件循环都包含了6个阶段,对应到 libuv 源码中的实现,如下图所示:
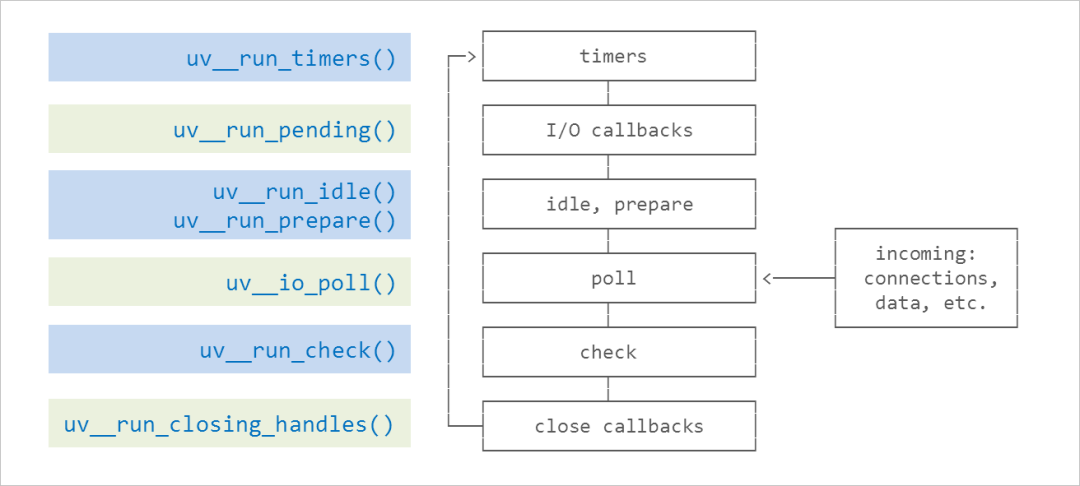
- timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调
- I/O callbacks 阶段:执行一些系统调用错误,比如网络通信的错误回调
- idle, prepare 阶段:仅node内部使用
- poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里
- check 阶段:执行setImmediate()的回调
- close callbacks 阶段:执行socket的close事件回调。
核心函数uv_run:源码 核心源码
int uv_run(uv_loop_t* loop, uv_run_mode mode) { int timeout; int r; int ran_pending;//首先检查我们的loop还是否活着//活着的意思代表loop中是否有异步任务//如果没有直接就结束
r = uv__loop_alive(loop); if (!r)
uv__update_time(loop);//传说中的事件循环,你没看错了啊!就是一个大while
while (r != 0 && loop->stop_flag == 0) { //更新事件阶段
uv__update_time(loop); //处理timer回调
uv__run_timers(loop); //处理异步任务回调
ran_pending = uv__run_pending(loop);//没什么用的阶段
uv__run_idle(loop);
uv__run_prepare(loop); //这里值得注意了
//从这里到后面的uv__io_poll都是非常的不好懂的
//先记住timeout是一个时间
//uv_backend_timeout计算完毕后,传递给uv__io_poll
//如果timeout = 0,则uv__io_poll会直接跳过
timeout = 0; if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
timeout = uv_backend_timeout(loop);
uv__io_poll(loop, timeout); //就是跑setImmediate
uv__run_check(loop); //关闭文件描述符等操作
uv__run_closing_handles(loop); if (mode == UV_RUN_ONCE) { /* UV_RUN_ONCE implies forward progress: at least one callback must have
* been invoked when it returns. uv__io_poll() can return without doing
* I/O (meaning: no callbacks) when its timeout expires - which means we
* have pending timers that satisfy the forward progress constraint.
*
* UV_RUN_NOWAIT makes no guarantees about progress so it's omitted from
* the check.
*/
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop); if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT) break;
} /* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0) loop->stop_flag = 0; return r;
}
代码中我已经写得很详细了,相信不熟悉c代码的各位也能轻易搞懂,没错,事件循环就是一个大while而已!神秘的面纱就此揭开。
uv__io_poll阶段
这个阶段设计得非常巧妙,这个函数第二个参数是一个timeout参数,而这个timeOut由来自uv_backend_timeout函数,我们进去一探究竟!
源码
int uv_backend_timeout(const uv_loop_t* loop) { if (loop->stop_flag != 0) return 0; if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop)) return 0; if (!QUEUE_EMPTY(&loop->idle_handles)) return 0; if (!QUEUE_EMPTY(&loop->pending_queue)) return 0; if (loop->closing_handles) return 0; return uv__next_timeout(loop);
}
原来是一个多步if函数,我们一个一个分析
1. stop_flag:这个标记是 0的时候,意味着事件循环跑完这一轮就退出了,返回的时间是0
2. !uv__has_active_handles和!uv__has_active_reqs:看名字都知道,如果没有任何的异步任务(包括timer和异步I/O),那timeOut时间一定就是0了
3. QUEUE_EMPTY(idle_handles)和QUEUE_EMPTY(pending_queue):异步任务是通过注册的方式放进了pending_queue中,无论是否成功,都已经被注册,如果什么都没有,这两个队列就是空,所以没必要等了。
4. closing_handles:我们的循环进入了关闭阶段,没必要等待了
以上所有条件判断来判断去,为的就是等这句话return uv__next_timeout(loop);这句话,告诉了uv__io_poll说:你到底停多久,接下来,我们继续看这个神奇的uv__next_timeout是怎么获取时间的。
int uv__next_timeout(const uv_loop_t* loop) { const struct heap_node* heap_node; const uv_timer_t* handle;
uint64_t diff;
heap_node = heap_min((const struct heap*) &loop->timer_heap); if (heap_node == NULL) return -1; /* block indefinitely */
handle = container_of(heap_node, uv_timer_t, heap_node); if (handle->timeout time) return 0;//这句代码给出了关键性的指导
diff = handle->timeout - loop->time;//不能大于最大的INT_MAX
if (diff > INT_MAX)
diff = INT_MAX; return diff;
}
等待结束以后,就会进入check 阶段.然后进入closing_handles阶段,至此一个事件循环结束。 因为是源码解析,所以具体的我就不多说,大家只可以看官方文档
总结
1、Nodejs与操作系统交互,我们在 Javascript中调用的方法,最终都会通过 process.binding 传递到 C/C++ 层面,最终由他们来执行真正的操作。Node.js 即这样与操作系统进行互动。
2、nodejs所谓的单线程,只是主线程是单线程,所有的网络请求或者异步任务都交给了内部的线程池去实现,本身只负责不断的往返调度,由事件循环不断驱动事件执行。
3、Nodejs之所以单线程可以处理高并发的原因,得益于libuv层的事件循环机制,和底层线程池实现。
4、Event loop就是主线程从主线程的事件队列里面不停循环的读取事件,驱动了所有的异步回调函数的执行,Event loop总共7个阶段,每个阶段都有一个任务队列,当所有阶段被顺序执行一次后,event loop 完成了一个 tick。
以上就是Nodejs探秘之深入理解单线程实现高并发原理的详细内容,更多关于Nodejs的资料请关注其它相关文章!
以上是 Nodejs探秘之深入理解单线程实现高并发原理 的全部内容, 来源链接: utcz.com/p/220118.html