java多线程学习笔记之自定义线程池
当我们使用 线程池的时候,可以使用 newCachedThreadPool()或者 newFixedThreadPool(int)等方法,其实我们深入到这些方法里面,就可以看到它们的是实现方式是这样的。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
包括其他几种不同类型的线程池,其实都是通过 ThreadPoolExecutor这个核心类来创建的,如果我们要自定义线程池,那么也是通过这个类来实现的。

该类有四个构造方法,查看源码可以看到,头三个构造方法,其实都是调用的第四个构造方法,所以我们就解释一下第四个构造方法的参数含义。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:核心线程池的大小,在线程池被创建之后,其实里面是没有线程的。(当然,调用prestartAllCoreThreads()或者prestartCoreThread()方法会预创建线程,而不用等着任务的到来)。当有任务进来的时候,才会创建线程。当线程池中的线程数量达到corePoolSize之后,就把任务放到 缓存队列当中。(就是 workQueue)。
maximumPoolSize:最大线程数量是多少。它标志着这个线程池的最大线程数量。如果没有最大数量,当创建的线程数量达到了 某个极限值,到最后内存肯定就爆掉了。
keepAliveTime:当线程没有任务时,最多保持的时间,超过这个时间就被终止了。默认情况下,只有 线程池中线程数量 大于 corePoolSize时,keepAliveTime值才会起作用。也就说说,只有在线程池线程数量超出corePoolSize了。我们才会把超时的空闲线程给停止掉。否则就保持线程池中有 corePoolSize 个线程就可以了。
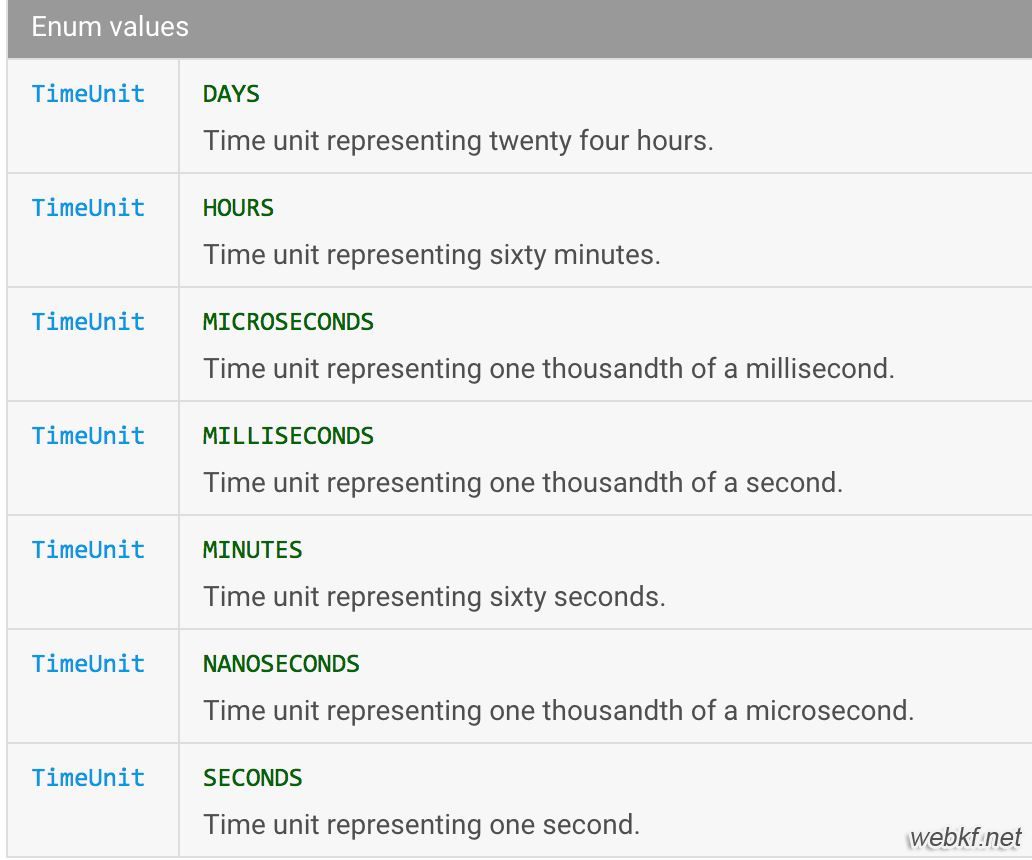
Unit:参数keepAliveTime的时间单位,就是 TimeUnit类当中的几个属性。
如下图:
workQueue:用来存储待执行任务的队列,不同的线程池它的队列实现方式不同(因为这关系到排队策略的问题)比如有以下几种
ArrayBlockingQueue:基于数组的队列,创建时需要指定大小。
LinkedBlockingQueue:基于链表的队列,如果没有指定大小,则默认值是 Integer.MAX_VALUE。(newFixedThreadPool和newSingleThreadExecutor使用的就是这种队列)。
SynchronousQueue:这种队列比较特殊,因为不排队就直接创建新线程把任务提交了。(newCachedThreadPool使用的就是这种队列)。
threadFactory:线程工厂,用来创建线程。
Handler:拒绝执行任务时的策略,一般来讲有以下四种策略,
(1) ThreadPoolExecutor.AbortPolicy 丢弃任务,并抛出 RejectedExecutionException 异常。
(2) ThreadPoolExecutor.CallerRunsPolicy:该任务被线程池拒绝,由调用 execute方法的线程执行该任务。
(3) ThreadPoolExecutor.DiscardOldestPolicy : 抛弃队列最前面的任务,然后重新尝试执行任务。
(4) ThreadPoolExecutor.DiscardPolicy,丢弃任务,不过也不抛出异常。
看一个demo ,示例代码地址:src/thread_runnable/CustomThreadPool.java
class CustomTask implements Runnable{
private int id;
public CustomTask(int id) {
this.id = id;
}
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println("#" + id + " threadId=" + Thread.currentThread().getName() );
try {
TimeUnit.MILLISECONDS.sleep(100);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
public class CustomThreadPool {
public static void main(String[] args) {
// TODO Auto-generated method stub
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(10);
ThreadPoolExecutor pool = new ThreadPoolExecutor(3, 5, 60, TimeUnit.MICROSECONDS, queue);
for (int i=0; i<7; i++){
Runnable task = new CustomTask(i);
pool.execute(task);
}
pool.shutdown();
}
}
输出结果:

从这个例子,可以看出,虽然我们有7个任务,但是实际上,只有三个线程在运行。
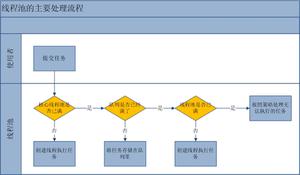
那么当我们提交任务给线程池之后,它的处理策略是什么呢?
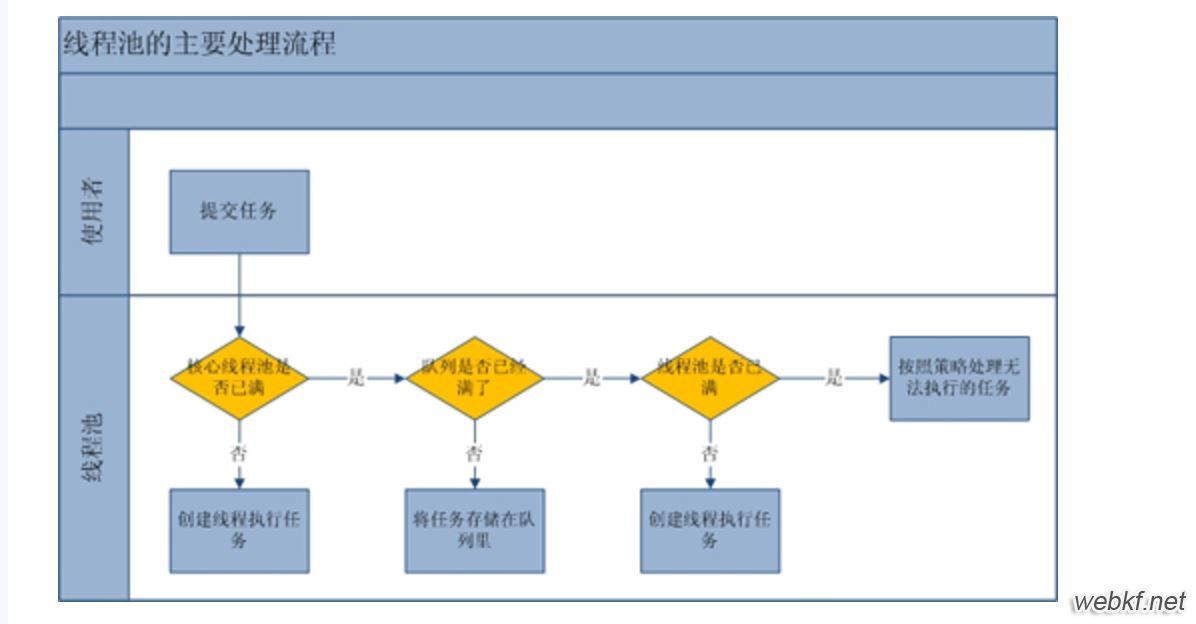
(1),如果当前线程池线程数目小于 corePoolSize(核心池还没满呢),那么就创建一个新线程去处理任务。
(2),如果核心池已经满了,来了一个新的任务后,会尝试将其添加到任务队列中,如果成功,则等待空闲线程将其从队列中取出并且执行,如果队列已经满了,则继续下一步。
(3),此时,如果线程池线程数量 小于 maximumPoolSize,则创建一个新线程执行任务,否则,那就说明线程池到了最大饱和能力了,没办法再处理了,此时就按照拒绝策略来处理。(就是构造函数当中的Handler对象)。
(4),如果线程池的线程数量大于corePoolSize,则当某个线程的空闲时间超过了keepAliveTime,那么这个线程就要被销毁了,直到线程池中线程数量不大于corePoolSize为止。
举个通俗易懂的例子,公司要设立一个项目组来处理某些任务,hr部门给的人员编制是10个人(corePoolSize)。同时给他们专门设置了一间有15个座位(maximumPoolSize)的办公室。最开始的时候来了一个任务,就招聘一个人。就这样,一个一个的招聘,招满了十个人,不断有新的任务安排给这个项目组,每个人也在不停的接任务干活。不过后来任务越来越多,十个人无法处理完了。其他的任务就只能在走廊外面排队了。后来任务越来越多,走廊的排队队伍也挤不下。然后只好找找一些临时工来帮助完成任务。因为办公室只有15个座位,所以它们最多也就只能找5个临时工。可是任务依旧越来越多,根本处理不完,那没办法,这个项目组只好拒绝再接新任务。(拒绝的方式就是 Handler),最后任务渐渐的少了,大家都比较清闲了。所以就决定看大家表现,谁表现不好,谁就被清理出这个办公室(空闲时间超过 keepAliveTime),直到 办公室只剩下10个人(corePoolSize),维持固定的人员编制为止。
关于线程池,ThreadPoolExecutor还提供了一些需要注意的方法:
(1) shutdown(),平滑的关闭线程池。(如果还有未执行完的任务,就等待它们执行完)。
(2) shutdownNow()。简单粗暴的关闭线程池。(没有执行完的任务也直接关闭)。
(3) setCorePoolSize()。设置/更改核心池的大小。
(4) setMaximumPoolSize(),设置/更改线程池中最大线程的数量限制。
以上是 java多线程学习笔记之自定义线程池 的全部内容, 来源链接: utcz.com/p/215899.html