基于java下载中getContentLength()一直为-1的一些思路
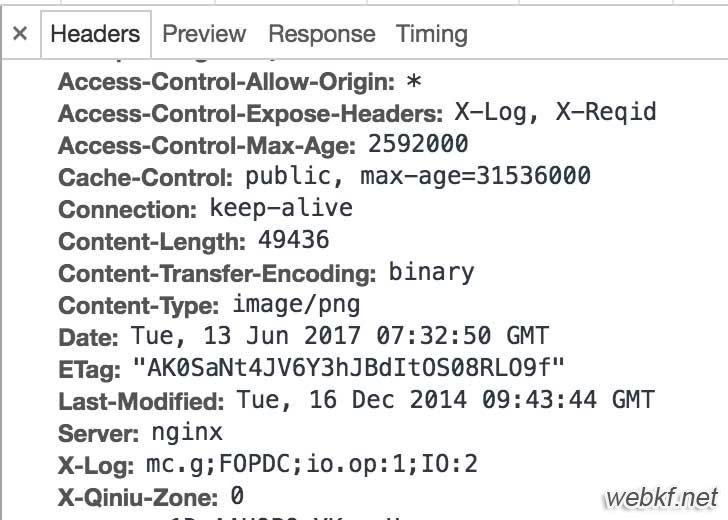
如果Content Length 在头文件中没有描述

暂时还没有解决方案
如果Content Long在头文件中有描述
方案一:
伪装成浏览器
conn.setRequestProperty("User-Agent", " Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
代码中加入代理
String host = "127.0.0.1";
String port = "8888";
setProxy(host, port);
public static void setProxy(String host, String port) {
System.setProperty("proxySet", "true");
System.setProperty("proxyHost", host);
System.setProperty("proxyPort", port);
}
方案二:
加入以下属性,让服务器不要gzip方式压缩:
Java Doc 有对此的描述:
By default, this implementation of HttpURLConnection requests that servers use gzip compression. Since getContentLength() returns the number of bytes transmitted, you cannot use that method to predict how many bytes can be read from getInputStream(). Instead, read that stream until it is exhausted: whenread() returns -1.
conn.setRequestProperty("Accept-Encoding", "identity");
以上这篇基于java下载中getContentLength()一直为-1的一些思路就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
以上是 基于java下载中getContentLength()一直为-1的一些思路 的全部内容, 来源链接: utcz.com/p/212913.html