java中使用sax解析xml的解决方法
在java中,原生解析xml文档的方式有两种,分别是:Dom解析和Sax解析
Dom解析功能强大,可增删改查,操作时会将xml文档以文档对象的方式读取到内存中,因此适用于小文档
Sax解析是从头到尾逐行逐个元素读取内容,修改较为不便,但适用于只读的大文档
本文主要讲解Sax解析,其余放在后面
Sax采用事件驱动的方式解析文档。简单点说,如同在电影院看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取)
在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或处理这些信息
同样,在Sax的解析过程中,读取到文档开头、结尾,元素的开头和结尾都会触发一些回调方法,你可以在这些回调方法中进行相应事件处理
这四个方法是:startDocument() 、 endDocument()、 startElement()、 endElement
此外,光读取到节点处是不够的,我们还需要characters()方法来仔细处理元素内包含的内容
将这些回调方法集合起来,便形成了一个类,这个类也就是我们需要的触发器
一般从Main方法中读取文档,却在触发器中处理文档,这就是所谓的事件驱动解析方法
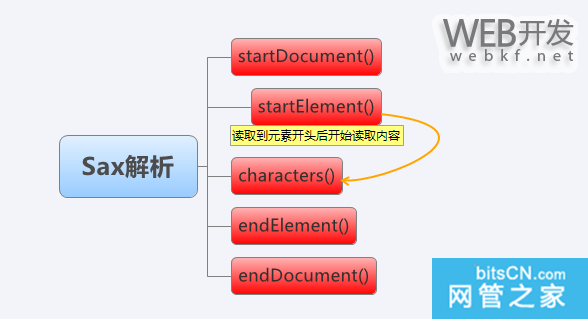
如上图,在触发器中,首先开始读取文档,然后开始逐个解析元素,每个元素中的内容会返回到characters()方法
接着结束元素读取,所有元素读取完后,结束文档解析
现在我们开始创建触发器这个类,要创建这个类首先需要继承DefaultHandler
创建SaxHandler,并覆写相应方法:
代码如下:
import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SaxHandler extends DefaultHandler { /* 此方法有三个参数 arg0是传回来的字符数组,其包含元素内容 arg1和arg2分别是数组的开始位置和结束位置 */ @Override public void characters(char[] arg0, int arg1, int arg2) throws SAXException { String content = new String(arg0, arg1, arg2); System.out.println(content); super.characters(arg0, arg1, arg2); } @Override public void endDocument() throws SAXException { System.out.println("\n…………结束解析文档…………"); super.endDocument(); } /* arg0是名称空间 arg1是包含名称空间的标签,如果没有名称空间,则为空 arg2是不包含名称空间的标签 */ @Override public void endElement(String arg0, String arg1, String arg2) throws SAXException { System.out.println("结束解析元素 " + arg2); super.endElement(arg0, arg1, arg2); } @Override public void startDocument() throws SAXException { System.out.println("…………开始解析文档…………\n"); super.startDocument(); } /*arg0是名称空间 arg1是包含名称空间的标签,如果没有名称空间,则为空 arg2是不包含名称空间的标签 arg3很明显是属性的集合 */ @Override public void startElement(String arg0, String arg1, String arg2, Attributes arg3) throws SAXException { System.out.println("开始解析元素 " + arg2); if (arg3 != null) { for (int i = 0; i < arg3.getLength(); i++) { // getQName()是获取属性名称, System.out.print(arg3.getQName(i) + "=\"" + arg3.getValue(i) + "\""); } } System.out.print(arg2 + ":"); super.startElement(arg0, arg1, arg2, arg3); } }
XML文档: 代码如下:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="001"> <title>Harry Potter</title> <author>J K. Rowling</author> </book> <book id="002"> <title>Learning XML</title> <author>Erik T. Ray</author> </book> </books>
TestDemo测试类: 代码如下:
import java.io.File; import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; public class TestDemo { public static void main(String[] args) throws Exception { // 1.实例化SAXParserFactory对象 SAXParserFactory factory = SAXParserFactory.newInstance(); // 2.创建解析器 SAXParser parser = factory.newSAXParser(); // 3.获取需要解析的文档,生成解析器,最后解析文档 File f = new File("books.xml"); SaxHandler dh = new SaxHandler(); parser.parse(f, dh); } }
输出结果: 代码如下:
…………开始解析文档………… 开始解析元素 books books: 开始解析元素 book id="001"book: 开始解析元素 title title:Harry Potter 结束解析元素 title 开始解析元素 author author:J K. Rowling 结束解析元素 author 结束解析元素 book 开始解析元素 book id="002"book: 开始解析元素 title title:Learning XML 结束解析元素 title 开始解析元素 author author:Erik T. Ray 结束解析元素 author 结束解析元素 book 结束解析元素 books …………结束解析文档…………
上面的虽然正确显示了执行流程,但是输出却很乱为了更加清晰的执行此流程,我们还可以重写SaxHandler,使其将原先的xml文档还原一遍
重写的SaxHandler类:
代码如下:
import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SaxHandler extends DefaultHandler { @Override public void characters(char[] arg0, int arg1, int arg2) throws SAXException { System.out.print(new String(arg0, arg1, arg2)); super.characters(arg0, arg1, arg2); } @Override public void endDocument() throws SAXException { System.out.println("\n结束解析"); super.endDocument(); } @Override public void endElement(String arg0, String arg1, String arg2) throws SAXException { System.out.print("</"); System.out.print(arg2); System.out.print(">"); super.endElement(arg0, arg1, arg2); } @Override public void startDocument() throws SAXException { System.out.println("开始解析"); String s = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>"; System.out.println(s); super.startDocument(); } @Override public void startElement(String arg0, String arg1, String arg2, Attributes arg3) throws SAXException { System.out.print("<"); System.out.print(arg2); if (arg3 != null) { for (int i = 0; i < arg3.getLength(); i++) { System.out.print(" " + arg3.getQName(i) + "=\"" + arg3.getValue(i) + "\""); } } System.out.print(">"); super.startElement(arg0, arg1, arg2, arg3); } }
执行结果:
现在看起来好多了,将其还原更能充分说明其解析流程
以上是 java中使用sax解析xml的解决方法 的全部内容,
来源链接:
utcz.com/p/207205.html