
将机器学习模型转换为Python中的API
本文概述
- 实现机器学习模型的选项
- 什么是API?
- Flask-Python中的Web服务框架
- 带Flask的Scikit学习模型
- 保存模型:序列化和反序列化
- 使用Flask从机器学习模型创建API
- 在Postman中测试你的API
- 更进一步
请考虑以下情况:
你已经建立了一个超酷的机器学习模型, 该模型可以预测特定交易是否为欺诈行为。现在, 你的一个朋友正在开发用于一般银行业务的android应用程序, 并希望将其机器学习模型集成到其应用程序中以实现其超级目标。
但是你的朋友发现, 当你的朋友使用Java构建应用程序时, 你已经用Python编码了模型。所以?是否可以将你的机器学习模型集成到你朋友的应用程序中?
幸运的是, 你拥有API的强大功能。以上情况是将机器学习模型转换为API的极为重要的众多情况之一。现在, 许多行业正在寻找可以做到这一点的数据科学家。现在, 将机器学习模型包装到API中并不是很困难, 而这正是你在本教程中将要做的-将你的机器学习模型转换为API。
具体来说, 你将涵盖以下内容:
- 实现机器学习模型的选项
- 什么是API?
- Flask基础
- 创建机器学习模型
- 保存机器学习模型:序列化和反序列化
- 使用Flask从机器学习模型创建API
- 在Postman中测试你的API
实现机器学习模型的选项
在大多数情况下, 真正使用机器学习模型是智能产品的核心-它可能是推荐系统或智能聊天机器人的一小部分。在这些时候, 似乎很难克服这些障碍。
例如, 大多数ML练习者使用R / Python进行实验。但是那些ML模型的使用者将是使用完全不同的技术堆栈的软件工程师。有两种方法可以解决此问题:
- 用软件工程人员可用的语言重写整个代码。上面的方法似乎是一个好主意, 但是完全无法获得复制那些复杂模型所需的时间和精力。大多数语言(例如JavaScript)都没有强大的库来执行ML。远离它是明智的。
- API优先方法– Web API使跨语言应用程序易于正常运行。如果前端开发人员需要使用你的ML模型来创建基于ML的Web应用程序, 则只需从提供API的位置获取URL端点。
现在, 在进一步研究之前, 让我们研究一下什么是真正的API。
什么是API?
“简单来说, API是2个软件之间的(假设)合同, 表示如果用户软件以预定格式提供输入, 则后者会扩展其功能并将结果提供给用户软件。” -分析Vidhya
你可以阅读以下文章, 以了解为什么API在开发人员中很受欢迎:
- API的历史
- API简介
从本质上讲, API非常类似于Web应用程序, 但是API并没有给你提供样式精美的HTML页面, 而是倾向于以标准的数据交换格式(例如JSON, XML等)返回数据。开发人员一旦获得所需的输出, 它们就会可以随心所欲地设置样式。例如, 也有许多流行的ML API-IBM Watson的ML API, 它具有以下功能:
- 机器翻译-帮助翻译不同语言对的文本。
- 信息共鸣–了解短语或单词在预定听众中的受欢迎程度。
- 问题与解答-此服务为由主文档源触发的查询提供直接答案。
- 用户建模–根据给定的文本预测某人的社会特征。
Google Vision API也是一个出色的示例, 它为Computer Vision任务提供了专用服务。点击此处了解使用Google Vision API可以完成的操作。
基本上会发生的是大多数云提供商, 而规模较小的专注于机器学习的公司则提供了现成的API。它们满足了不具备ML专业知识的开发人员/企业的需求, 他们希望在其流程或产品套件中实现ML。
明确适用于Web开发的机器学习API的流行示例是DialogFlow, Microsoft的Cognitive Toolkit, TensorFlow.js等。
既然你对API是什么有了一个清晰的认识, 让我们看看如何将机器学习模型(用Python开发)包装到Python的API中。
Flask-Python中的Web服务框架
现在, 你可能会认为什么是Web服务? Web服务只是API的一种形式, 它假定API托管在服务器上并且可以使用。 Web API, Web Service-这些术语通常可以互换使用。
来到Flask, 它是Python中的Web服务开发框架。它不是Python中唯一的一个, 还有其他几个, 例如Django, Falcon, Hug等。但是你将在本教程中使用Flask。要了解Flask, 可以参考这些教程。
如果你下载了Anaconda发行版, 则已经安装了Flask。否则, 你将必须使用以下方法自行安装:
pip install flaskFlask非常小。 Flask受到Python开发人员的青睐有很多原因。 Flask框架带有一个内置的轻量级Web服务器, 该服务器需要最少的配置, 并且可以通过Python代码进行控制。这是它如此受欢迎的原因之一。
以下代码以一种不错的方式演示了Flask的最小化。该代码用于创建简单的Web-API, 该Web-API在接收到特定URL时会产生特定输出。
from flask import Flaskapp = Flask(__name__)
@app.route("/")
def hello():
return "Welcome to machine learning model APIs!"
if __name__ == '__main__':
app.run(debug=True)
执行后, 你可以导航到终端上显示的网址(在Web浏览器上输入该地址), 并观察结果。
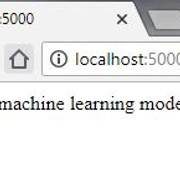
一些要点:
- Jupyter笔记本非常适合与降价促销, R和Python相关的任何事情。但是, 当涉及到构建Web服务器时, 它可能表现出不一致的行为。因此, 最好在Sublime之类的文本编辑器中编写Flask代码, 然后从终端/命令提示符下运行代码。
- 确保你未将文件命名为flask.py。
- Flask默认在端口号5000上运行。有时, Flask服务器会成功在此端口号上启动, 但是当你在Web浏览器或任何API客户端(如Postman)中点击URL(服务器在终端上返回)时, 你可能不会得到输出。请考虑以下情况:
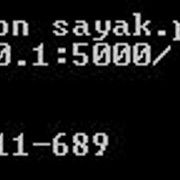
根据Flask的说法, 其服务器已在端口5000上成功启动, 但是在浏览器中触发URL时, 它未返回任何内容。因此, 这可能是端口号冲突的可能情况。在这种情况下, 将默认端口5000更改为所需的端口号将是一个不错的选择。你只需执行以下操作即可:
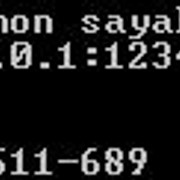
app.run(调试= True, 端口= 12345)
- 在这种情况下, Flask服务器将如下所示:
现在, 让我们逐步介绍你编写的代码:
- 你创建了Flask类的实例, 并传入了” name”变量(由Python本身填充)。如果此文件直接作为脚本通过Python运行, 则此变量将为” main”。如果改为导入文件, 则”名称”的值将是你导入的文件的名称。例如, 如果你有test.py和run.py, 并且将test.py导入run.py, 则test.py的”名称”值将为test(app = Flask(test))。
- 在hello()方法定义上方, 有@ app.route(” /”)。 route()是一个装饰器, 它告诉Flask哪个URL应该触发定义为hello()的函数。
- 每当你的API被正确点击(或使用)时, hello()方法负责产生输出(欢迎使用机器学习模型API!)。在这种情况下, 使用localhost:5000 /来访问Web浏览器将产生预期的输出(前提是flask服务器在端口5000上运行)。
现在, 你将学习将机器学习模型(使用scikit-learn构建)转换为Flask API时需要牢记的一些因素。
带Flask的Scikit学习模型
使用scikit-learn在Python中创建从简单到非常复杂的机器学习模型从未如此简单。但是, 关于scikit-learn, 你需要记住一些要点:
- Scikit-learn是一个Python库, 它为数据挖掘和数据分析提供了简单有效的工具。 Scikit-learn具有以下主要模块:
- 聚类
- 回归
- 分类
- 降维
- 选型
- 前处理
(请务必检查由scikit-learn的核心开发人员AndreasMüller教授的srcmini的scikit-learn的监督学习课程)
- Scikit-learn支持使用scikit-learn训练的模型的序列化和反序列化。这样可以节省你重新训练模型的时间。使用scikit-learn创建的模型的序列化副本, 你可以编写Flask API。
- Scikit学习模型要求数据为数字格式。这就是为什么如果数据集包含非数字的分类特征, 将它们转换为数字特征很重要。对于此转换, scikit-learn提供了诸如LabelEncoder, OneHotEncoder等实用程序。可以在sklearn.preprocessing模块中找到这些实用程序。
- Scikit学习模型无法隐式处理缺失值。你需要自己处理数据集中的缺失值, 然后才能将其输入模型。为了处理缺失值, scikit-learn提供了广泛的实用程序, 可以从sklearn.preprocessing模块中找到它们。
标签编码和缺失值是重要的数据预处理步骤, 对于构建良好的机器学习模型非常重要。如果你想了解更多有关此的信息, 请确保检查srcmini提供的以下课程:
- 用Python进行机器学习的预处理
在本教程中, 由于许多原因, 你将使用Titanic数据集, 它是最受欢迎的数据集之一, 例如-数据集包含非常不同类型的变量, 数据集包含缺失值等。此srcmini教程涵盖了分析数据集, 然后可以从此处下载数据集。
该数据集处理了一个分类问题, 即预测乘客是否可以幸存下来, 而没有给出有关他/她的一些信息。
注意:变量和功能这些术语在本教程中多次互换使用。
为了进一步简化操作, 你将只使用四个变量:年龄, 性别, 出发和生存时间, 其中生存时间是类标签。
# Import dependenciesimport pandas as pd
import numpy as np
# Load the dataset in a dataframe object and include only four features as mentionedurl = "http://s3.amazonaws.com/assets.srcmini.com/course/Kaggle/train.csv"
df = pd.read_csv(url)
include = ['Age', 'Sex', 'Embarked', 'Survived'] # Only four features
df_ = df[include]
“性别”和”禁止”是具有非数字值的分类特征, 因此它们需要进行一些数字转换。 “年龄”功能缺少值。可以使用汇总统计数据(例如中位数或均值)来估算这些值。缺失的值可能非常有意义, 值得研究它们在实际应用中的含义。
Scikit-learn将不包含任何内容的单元格值视为NaN。在这里, 你仅将NaN替换为0, 并为此编写一个辅助函数。
categoricals = []for col, col_type in df_.dtypes.iteritems():
if col_type == 'O':
categoricals.append(col)
else:
df_[col].fillna(0, inplace=True)
上面的代码行执行以下操作:
- 遍历数据帧df中的所有列, 并将这些列(具有非数字值)附加到分类列表中。
如果列中没有非数字值(在这种情况下, 该值仅是Age), 则它将检查其是否缺少值, 并用0填充它们。
用单个值填充NaN可能会产生意想不到的后果, 尤其是如果你要替换的NaN的数量在数字变量的观察范围内。由于零不是可观察到的合法年龄值, 因此你不会引入偏见, 因此, 如果使用” 36″, 你将拥有零偏! – 资源
现在, 你已经处理了缺失值并分隔了非数字列, 你可以将它们转换为数字列了。你将使用”一次热编码”来完成此操作。熊猫提供了一种简单的get_dummies()方法, 用于为给定的数据帧创建OHE变量。
df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)使用OHE时, 将以column_value格式为每个列/值组合创建一个新列。例如, 对于” Embarked”变量, OHE将生成” Embarked_C”, ” Embarked_Q”, ” Embarked_S”和” Embarked_nan”。
现在, 你已经成功地预处理了数据集, 现在可以训练机器学习模型了。你将为此使用Logistic回归分类器。
from sklearn.linear_model import LogisticRegressiondependent_variable = 'Survived'
x = df_ohe[df_ohe.columns.difference([dependent_variable])]
y = df_ohe[dependent_variable]
lr = LogisticRegression()
lr.fit(x, y)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)你已经建立了机器学习模型。现在, 你将保存该模型。从技术上讲, 你将序列化此模型。在Python中, 你将此称为酸洗。
保存模型:序列化和反序列化
你将为此使用sklearn的joblib。
from sklearn.externals import joblibjoblib.dump(lr, 'model.pkl')
['model.pkl']Logistic回归模型现已保留。你可以使用单行代码将此模型加载到内存中。将模型重新加载到工作空间中被称为反序列化。
lr = joblib.load('model.pkl')现在, 你可以使用Flask服务持久模型了。你已经了解了Flask如何入门。
使用Flask从机器学习模型创建API
为了使用Flask服务于模型, 你需要做以下两件事:
- 应用程序启动时, 将已经持久化的模型加载到内存中,
- 创建一个API端点, 该端点接受输入变量, 将其转换为适当的格式, 然后返回预测。
更具体地说, 你对API的示例输入如下所示:
[ {"Age": 85, "Sex": "male", "Embarked": "S"}, {"Age": 24, "Sex": '"female"', "Embarked": "C"}, {"Age": 3, "Sex": "male", "Embarked": "C"}, {"Age": 21, "Sex": "male", "Embarked": "S"}
]
(这是输入的JSON列表)
并且你的API将输出如下所示:
{"prediction": [0, 1, 1, 0]}预测表示生存状态, 其中0表示否, 1表示是。
JSON代表JavaScript Object Notation, 它是使用最广泛的数据交换格式之一。如果你需要对其进行快速介绍, 请按照以下教程进行操作。
让我们编写一个函数predict(), 它将执行以下操作:
- 应用程序启动时将持久化模型加载到内存中,
- 创建一个API端点, 该端点接受输入变量, 将其转换为适当的格式, 然后返回预测。
你已经了解了如何加载持久化模型。现在, 你将专注于如何在接收到输入后使用它来预测生存状态。
from flask import Flask, jsonifyapp = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
json_ = request.json
query_df = pd.DataFrame(json_)
query = pd.get_dummies(query_df)
prediction = lr.predict(query)
return jsonify({'prediction': list(prediction)})
太棒了!但是你这里有一个小问题。
你编写的函数仅在传入请求包含分类变量的所有可能值(实时情况可能会或可能不实时)的条件下起作用。如果传入的请求未包含所有类别变量的可能值, 则按照当前方法的dict()的定义, get_dummies()将生成一个数据帧, 该数据帧的列数比分类器少, 但会导致运行时错误。
要解决此问题, 你还将在模型训练期间保留列列表。你可以将任何Python对象序列化为.pkl文件。你将以与以前相同的方式使用joblib。
(请记住, 如前所述, 总是最好在文本编辑器中进行所有服务器级别的编码, 然后从终端运行它)
model_columns = list(x.columns)joblib.dump(model_columns, 'model_columns.pkl')
['model_columns.pkl']由于已经保留了列列表, 因此可以在预测时处理缺失值。应用程序启动时, 你将必须加载模型列。
@app.route('/predict', methods=['POST']) # Your API endpoint URL would consist /predictdef predict():
if lr:
try:
json_ = request.json
query = pd.get_dummies(pd.DataFrame(json_))
query = query.reindex(columns=model_columns, fill_value=0)
prediction = list(lr.predict(query))
return jsonify({'prediction': prediction})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')
你已在” / predict” API中包含了所有必需的元素, 现在你只需要编写主类。
if __name__ == '__main__': try:
port = int(sys.argv[1]) # This is for a command-line argument
except:
port = 12345 # If you don't provide any port then the port will be set to 12345
lr = joblib.load(model_file_name) # Load "model.pkl"
print ('Model loaded')
model_columns = joblib.load(model_columns_file_name) # Load "model_columns.pkl"
print ('Model columns loaded')
app.run(port=port, debug=True)
你的API现在可以托管了。但是在继续之前, 让我们回顾一下到目前为止所做的一切:
放在一起:
- 你加载了Titanic数据集并选择了四个要素。
- 你进行了必要的数据预处理。
- 你构建了Logistic回归分类器并对其进行了序列化。
- 你还序列化了培训中的所有列, 以解决少于预期数量的列的问题, 即保留培训中的列列表。
- 然后, 你使用Flask写了一个简单的API, 该API可以根据年龄, 性别和登船信息来预测某人是否在沉船中幸存下来。
让我们将所有代码放在一个地方, 这样你就不会错过任何内容。另外, 如果将Logistic回归模型代码和Flask API代码分开到单独的.py文件中, 则是一种很好的编程习惯。
因此, 你的model.py应该如下所示:
# Import dependenciesimport pandas as pd
import numpy as np
# Load the dataset in a dataframe object and include only four features as mentioned
url = "http://s3.amazonaws.com/assets.srcmini.com/course/Kaggle/train.csv"
df = pd.read_csv(url)
include = ['Age', 'Sex', 'Embarked', 'Survived'] # Only four features
df_ = df[include]
# Data Preprocessing
categoricals = []
for col, col_type in df_.dtypes.iteritems():
if col_type == 'O':
categoricals.append(col)
else:
df_[col].fillna(0, inplace=True)
df_ohe = pd.get_dummies(df_, columns=categoricals, dummy_na=True)
# Logistic Regression classifier
from sklearn.linear_model import LogisticRegression
dependent_variable = 'Survived'
x = df_ohe[df_ohe.columns.difference([dependent_variable])]
y = df_ohe[dependent_variable]
lr = LogisticRegression()
lr.fit(x, y)
# Save your model
from sklearn.externals import joblib
joblib.dump(lr, 'model.pkl')
print("Model dumped!")
# Load the model that you just saved
lr = joblib.load('model.pkl')
# Saving the data columns from training
model_columns = list(x.columns)
joblib.dump(model_columns, 'model_columns.pkl')
print("Models columns dumped!")
你的api.py应该如下所示:
# Dependenciesfrom flask import Flask, request, jsonify
from sklearn.externals import joblib
import traceback
import pandas as pd
import numpy as np
# Your API definition
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
if lr:
try:
json_ = request.json
print(json_)
query = pd.get_dummies(pd.DataFrame(json_))
query = query.reindex(columns=model_columns, fill_value=0)
prediction = list(lr.predict(query))
return jsonify({'prediction': str(prediction)})
except:
return jsonify({'trace': traceback.format_exc()})
else:
print ('Train the model first')
return ('No model here to use')
if __name__ == '__main__':
try:
port = int(sys.argv[1]) # This is for a command-line input
except:
port = 12345 # If you don't provide any port the port will be set to 12345
lr = joblib.load("model.pkl") # Load "model.pkl"
print ('Model loaded')
model_columns = joblib.load("model_columns.pkl") # Load "model_columns.pkl"
print ('Model columns loaded')
app.run(port=port, debug=True)
漂亮整齐!现在, 你将在名为Postman的API客户端中测试此API。只需确保将model.py和api.py放在同一目录中, 并确保在测试之前已对它们进行了编译。请参考以下终端快照, 这两个.py文件均已成功编译。
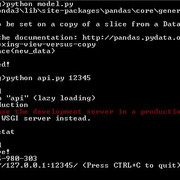
如果所有文件都已成功编译, 则目录结构应为:
注意:IPYNB文件是可选的。
在Postman中测试你的API
为了测试你的API, 你将需要某种API客户端。邮递员无疑是最好的邮递员之一。你可以从上面的链接轻松下载Postman。
如果你下载了最新的邮递员界面, 则其外观如下所示:
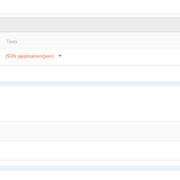
成功启动Flask服务器后, 然后需要在Postman中输入正确的URL和正确的端口号。它看起来应该类似于以下内容:
恭喜你!你刚刚构建了第一个机器学习API。
你的API可以根据年龄, 性别和登船信息来预测乘客是否在泰坦尼克号沉船事故中幸存下来。现在, 你的朋友可以从那里的前端代码调用它, 并将API的输出处理成令人着迷的东西。
更进一步
在本教程中, 你介绍了全数据科学家最重要的行业要求技能之一, 即从机器学习模型构建API。尽管该API很简单, 但最好还是从最简单的事情开始, 这样你才能了解细节中的专有技术。
你可以做更多的事情来改善这一点。你可能要考虑的可能选项:
- 编写一个” / train” API, 该API将使用数据训练Logistic回归分类器。
- 使用keras编写神经网络模型并从中构建API。
- 将你的API托管在云上, 以便可以使用它。
- 为了使事情更高级, 你可以参考这个机器学习精通博客, 该博客讨论了几种行业分级的方法。
这里的可能性和机遇是巨大的。你只需要仔细选择最适合你的那些。
如果你想了解有关Python机器学习的更多信息, 请参加srcmini的Python机器学习预处理课程。
参考文献:
以下是撰写此博客时参考的内容:
- Flask:构建Python Web服务
- 有关该主题的Quora主题
以上是 将机器学习模型转换为Python中的API 的全部内容, 来源链接: utcz.com/p/204067.html








