Chakra 引擎中 JIT 编译优化过程中的数组类型混淆漏洞分析
作者:启明星辰ADLab
1. 研究背景
Chakra是一个由微软为Microsoft Edge浏览器开发的JavaScript引擎。它在一个独立的CPU核心上即时编译脚本,与浏览器并行。本文主要对Chakra引擎中JIT编译优化过程中的数组类型混淆漏洞进行分析。
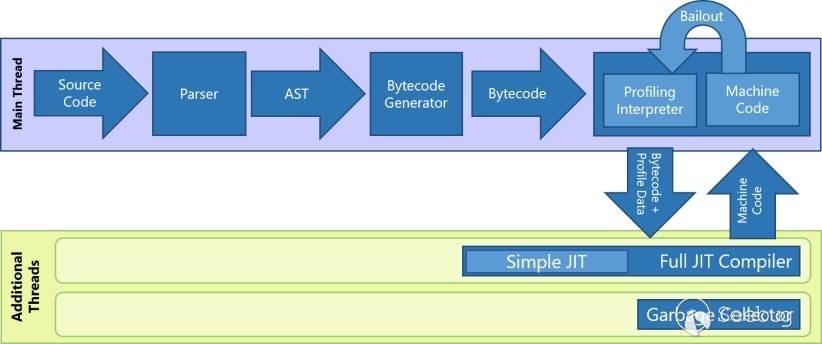
JavaScript引擎的性能对整个浏览器的影响至关重要, JIT编译优化是为了提高Chakra引擎性能。当在循环语句中反复执行同一段脚本代码时,如果解释器反复执行相关的字节码,效率会很低。JIT可以将源代码直接生成机器指令,在下一次执行时直接执行机器指令。在Chakra中只有当目标函数或者循环语句被频繁调用时才会启用JIT编译,JIT编译后生成了相应的机器指令,下一次调用到这个语句或是函数时就会直接执行机器指令。
一旦JIT生成完成,程序就可以直接调用JIT生成的机器指令。因为JIT是直接编译为机器指令的,所以需要预先假定操作目标的类型。如果不满足JIT的假设的话,此JIT代码就不能执行,否则就会发生类型混淆的错误。因此JIT代码中设计了bailout功能,一旦发现不满足假设就进行bailout,bailout会放弃执行JIT代码转回使用解释器继续执行字节码。
2. 数组类型混淆思路
Chakra数组可以分为三类,分别是NativeIntArray、NativeFloatArray和VarArray。NativeIntArray和NativeFloatArray数组转化成VarArray数组过程中会将数组中的原数据通过异或0xfffc000000000000转化为VarArray中的数据。也就是说VarArray会通过数组中元素的高位来判断数组中的元素是数据还是对象。
NativeIntArray和NativeFloatArray之间混淆一般不能带来安全问题,但是当这二者和VarArray混淆之后就会出现数据和对象无法区分的问题。
先看一段简单代码。

这段代码在JIT优化后的表现形式是这样的。

如果在xxx操作过程中将NativeArray的类型改变成了VarArray,并且JIT的优化过程并没有检测到这种变化的话,2.3023e-320就会被当作float数据存放进入VarArray的元素中,由于这个过程中数组的变化是始料未及的,所以2.3023e-320并没有通过与0xfffc000000000000异或而变成一个可以被VarArray识别的float,所以VarArray对象在读取该元素时会将其当成一个对象来处理。
为了实现数组的类型混淆,xxx操作主流的思路有两种,一种是通过没有检测的回调来修改数组的类型,第二种是通过合理的函数来修改数组的类型。下面通过一些实例进行简要分析。
2.1. 思路一:通过回调修改数组类型
先来看一个简单的例子,通过回调修改数组类型。
 func的JIT主要片段如下:
func的JIT主要片段如下:

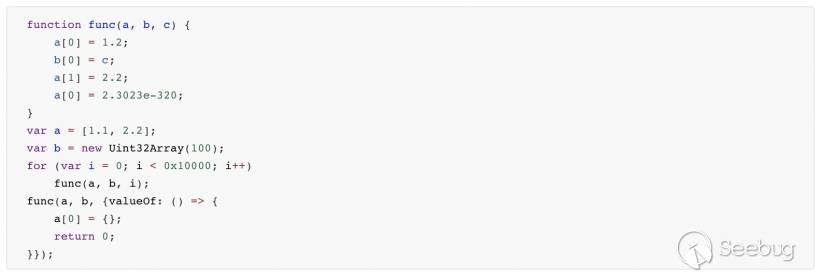
根据上述代码,可以看到call rax之后并没有验证数组a是否合法就直接进行了赋值。那么如何改变数组a的类型呢?我们来看最后一次对func的调用。

漏洞脚本将一个对象直接赋值给了参数c,并且在这个对象上挂了一个valueOf回调,c要赋值给typed数组b,而b中的元素只能是Uint32类型,所以JIT会对参数c进行一个转换(用到ToInt32),这会触发c的valueOf回调,在回调函数中通过a[0]={}给数组a赋值,这会将a由NativeFloatArray变成VarArray,而后续代码因为没有检查a数组改变所以继续将其当作NativeFloatArray赋值造成了类型混淆。
补丁后代码如下。
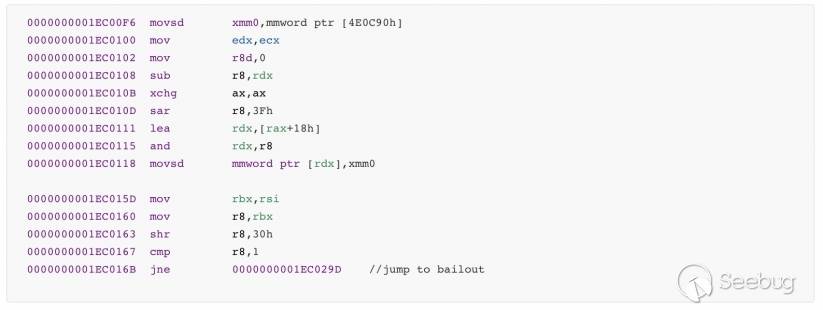
一般来说,Chakra引擎在对JIT中的回调进行优化时会考虑一个叫做ImplicitCallFlags的标志位,通过这个标志位,就可以检测用户函数是否可能被调用,如果是的话就会启动bailout或进行相关检测。但是这种机制存在一些问题,比如ImplicitCallFlags标志位到底在什么位置会被置位,它是否能保护所有存在回调函数的位置?
一个典型的例子:CVE-2017-11802

这个漏洞比较简单,存在于RegexHelper::StringReplace函数中,regexp的replace方法,可以定义一个回调函数,但是在其实现中并没有对回调函数进行保护,也就是说可以直接在regexp的replace方法中修改数组类型而不被JIT检测到。

该漏洞的补丁也比较简单,通过对两处调用回调的位置添加ExecuteImplicitCall验证,就可以修补该漏洞。这个补丁同时修补了一处位于JavascriptArray::ArraySpeciesCreate中的由于创建新对象而导致的回调。
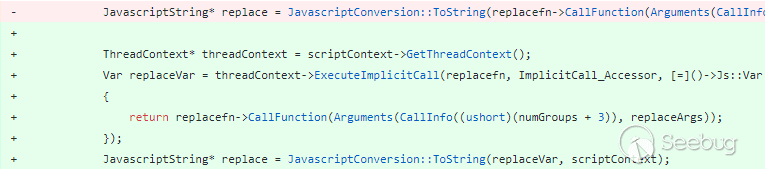
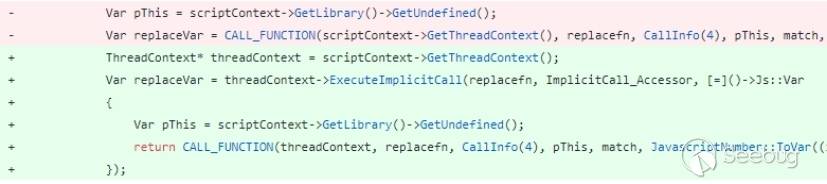
这种机制在实现和优化过程中有没有瑕疵呢?下面来看另一个例子CVE-2018-0840。

这是一个直接对ExecuteImplicitCall函数进行对抗的漏洞,其问题本身在于ExecuteImplicitCall函数的实现,其代码片段如下。

函数首先会执行implicitCall然后才会更新ImplicitCallFlags,单纯从函数本身来考虑好像没什么问题,但是这里面忽略了一个可能就是回调在执行过程中如果出现了一个异常该怎么处理,POC中的typeof实现位于JavascriptOperators::TypeofElem函数中,和漏洞有关的代码如下。

回调会通过ExecuteImplicitCall函数进行调用,但是回调函数会触发一个异常,该异常会被TypeofElem捕获,也就是说ExecuteImplicitCall函数中更新ImplicitCallFlags的操作被跳过了,由于标志位没有被更新,所以优化过程中的相应排错机制也就没有被生成,最终导致了漏洞的产生。
另外一个问题是CVE-2018-8556,通过补丁信息可以知道漏洞存在于GlobOptBailOut.cpp的MayNeedBailOnImplicitCall函数中,从名字可以推测,这个函数主要负责判断JIT优化过程中是否对ImplicitCall生成bailout代码。
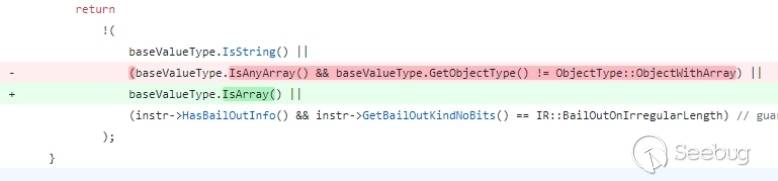
在该函数对对象的length属性进行获取的操作中,判断返回值的逻辑出现了问题。
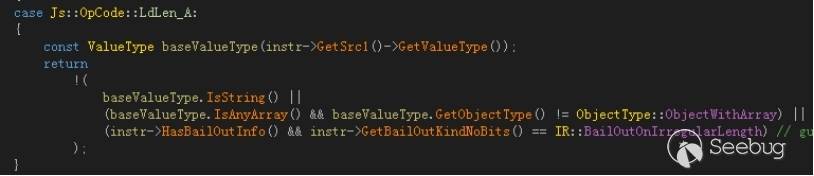
从逻辑上看,string和满足IsAnyArray并且不等于ObjectWithArray的对象都是可以通过验证的,也就是说typedarray也是满足条件的。

如果要给对象获取length的操作加回调或者过滤操作,对象的length属性的configurable特性必须为true,string和array的length都符合这个假定,但是typedarray却是个例外,所以可以通过给typedarray的length属性加回调的操作,去执行用户定义的代码来触发类型混淆漏洞。
2.2. 思路二:通过合理的函数调用修改数组类型
接下来看第二种思路,通过合理函数调用来触发数组类型改变。在一些函数处理中,由于功能原因会调用ToVarArray函数对数组类型进行改变。
下面举例说明。

opt函数的JIT优化代码如下:

可以看到,在call rax之后并没有进行数组类型的检测就直接赋值了,那么这个call中到底发生了什么呢?这个call调用了JavascriptOperators::OP_InitProto函数来初始化proto,在最后一次opt调用时,将array当作proto给了属性链,在对属性链赋值时,如果赋值参数是一个Native数组的话会将其转换为VarArray(调用了ToVarArray函数)。其调用函数栈如下。

此时数组的类型已经发生了改变而JIT并没有检查到这一点所以产生了漏洞。
再来看一个较为复杂点的例子CVE-2018-0835。

该漏洞存在于JavascriptArray::ReverseHelper函数中,函数会调用JavascriptArray::FillFromPrototypes,该函数通过遍历prototype来填充array。

在程序中,函数确保prototype中的array不能是NativeArray。
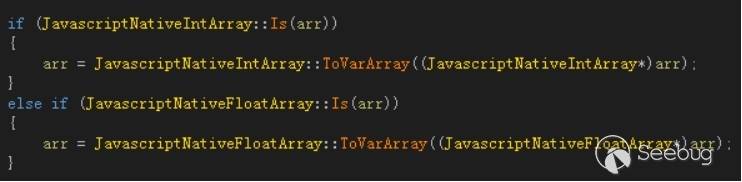
也就是说,如果prototype是NativeArray数组则会被程序转换为VarArray,如果能够使一个数组的prototype为NativeArray,就可以通过数组的Reverse方法将其prototype的NativeArray转换为VarArray。不过这里还有一个问题就是如何确保prototype是NativeArray,一般情况下如果一个数组被当作prototype,则它会被转化为VarArray。
在JavascriptArray::EntrySort中存在如下代码。

如果arr是一个NativeArray,它首先会变成一个VarArray执行sort回调,再变回NativeArray,如果能够在回调中将这个arr赋给prototype,之后它的类型又会变回来,这样就可以得到一个类型混淆漏洞。
2.3. 思路三:MissingItem
CVE-2018-0953同样也是通过函数调用修改数组类型,这个漏洞特别之处在于引出了另一个关注点,即数组的MissingItem。MissingItem是一个数值,在64位程序上等于0x8000000280000002。Chakra引擎在数组创建的时候会使用这个值对数组元素进行初始化,表示数组中该元素还未进行赋值,另外数组还会保留一个标志位(NoMissingValues)来标志此数组是否有未被赋值的元素。
先看看下面这段代码。

当执行数组的赋值操作,调用了NativeArray的SetItem函数,SetItem函数实现如下。
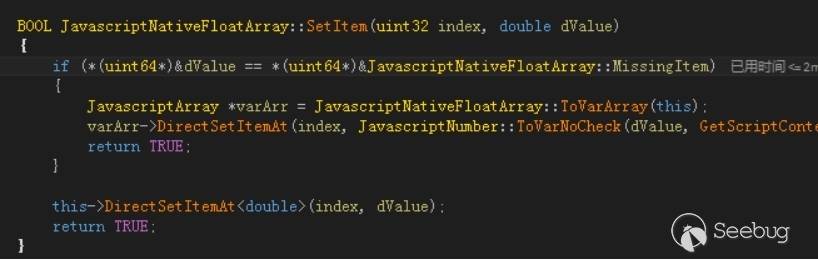
当给NativeArray赋值时,如果这个值等于MissingItem,可以将NativeArray转化为VarArray。优化逻辑假设对数组进行赋值是一个很安全的操作,只要传入参数不是一个对象那么就不会改变数组类型,但是并没有考虑到如果赋值的值等于MissingItem的话会引起数组类型的变化,正是这种疏忽导致了漏洞的发生。
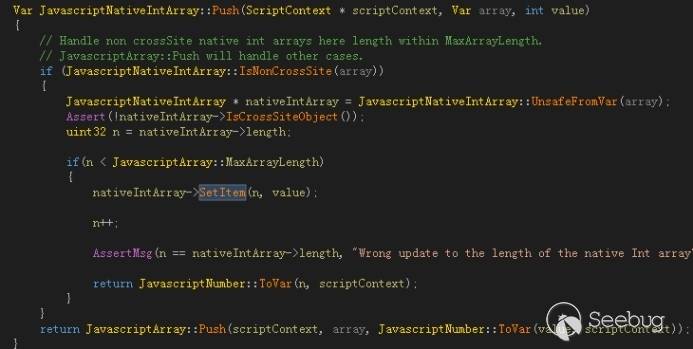
这个漏洞本身非常好理解,但是MissingItem本身又引出了一连串的问题。该漏洞的补丁程序修补了通过OP_SetElementI来调用SetItem的情况,但是这样修补远远不够,因为对该函数调用的位置其实非常多,于是找漏洞的思路变成了寻找为NativeArray赋值的各种路径的问题。
CVE-2018-0953的漏洞发现者lokihardt在补丁修补后又提出两种思路来绕过补丁,第一个是通过arraypush来调用SetItem。
触发漏洞代码如下:
 因为通过push对数组进行插入的操作会调用SetItem,所以数组改变的情况仍旧会存在。
因为通过push对数组进行插入的操作会调用SetItem,所以数组改变的情况仍旧会存在。
第二个思路是先直接修改数组的元素,再通过cancat来修改数组类型。漏洞触发代码如下:
 POC首先通过set修改了数组中元素的值。
POC首先通过set修改了数组中元素的值。
 对应的JIT代码是这样的。
对应的JIT代码是这样的。
 在修改了数组元素后,创造了一个有MissingItem但是HasNoMissingValues的array。
在修改了数组元素后,创造了一个有MissingItem但是HasNoMissingValues的array。
接着脚本调用了trigger函数,由于数组的HasNoMissingValues标志位为真,下图代码中的条件是满足的。
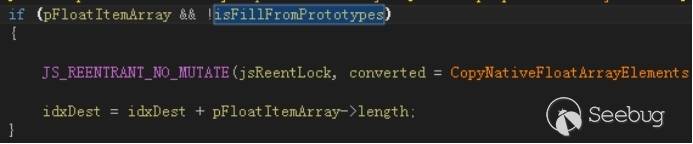
因为数组有了MissingItem,所以可以进行到如下分支。

InternalFillFromPrototype函数会对buggy数组prototype链上所有对象调用EnsureNonNativeArray,也就是说会对arr调用EnsureNonNativeArray,这样就可以修改其数组类型,但是JIT引擎并不知道arr类型已经改变,所以会导致类型混淆。
针对此问题,Chakra的工作人员开始大规模的检查NativeArray的input,在LowerStElemC、GenerateProfiledNewScObjArrayFastPath、GenerateHelperToArrayPopFastPath等诸多函数上添加了MissItem的检测(由于修补函数较多,这里就不一一列举了,详情请参考地址https://github.com/Microsoft/ChakraCore/commit/91bb6d68bfe0455cde08aaa5fbc3f2e4f6cc9d04)。
但是,通过如下代码调用的OP_Memset函数并没有对value进行检查,仍旧可以用来构造拥有MissingItem但是HasNoMissingValues的array,并通过concat来得到一个类型混淆漏洞。

值得一提的是,在11月的补丁中Chakra直接对concat方法做了严格的处理,从情况上推测应该是找到了新的方法来将MissingItem写入array,但由于网上没找到相应的信息,再加上补丁并没有对将值写入array的代码进行修补,反而限制了concat,所以也无法判断具体情况。
2.4. 思路四:将数组伪装成对象
最后一种思路,通过迷惑Chakra引擎,使其在生成JIT代码过程中错误的将NativeArray当作其他对象,以至于没有在恰当的位置添加检查代码。
公开的例子是CVE-2018-8466。

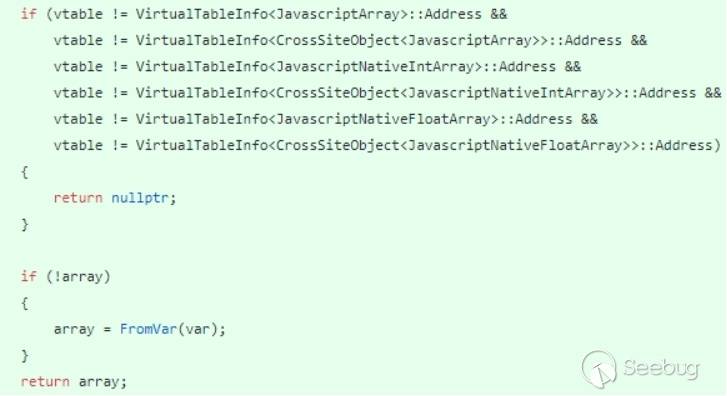
Chakra使用JavascriptArray::GetArrayForArrayOrObjectWithArray来判断对象是否是array,其逻辑如下所示。
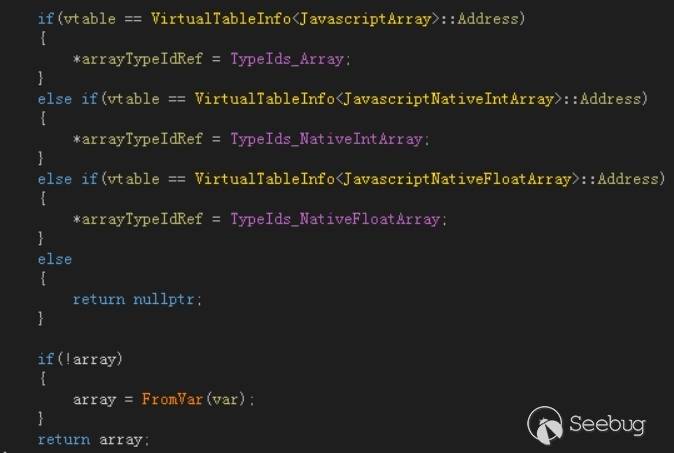
通过CrossSite class来wrap一个对象的时候会替换该对象的虚表,所以被wrapping的数组将不会被识别为数组,这将导致无法在正确的地方生成对数组类型的检查并产生类型混淆漏洞。
补丁除了验证虚表是否是array对象之外,还检查了对象是否是被CrossSite wrap的数组。
另一个例子是CVE-2018-8542,其补丁在ValueType::MergeWithObject中。
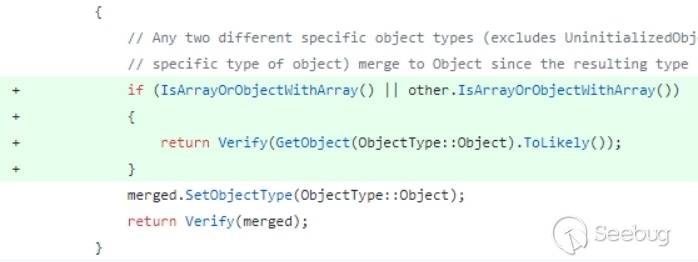
该函数主要用于合并两个对象,可以看到补丁添加了验证,用于确定两个对象中是否有数组,再观察一下没打过补丁的问题代码,如果两个对象都不是UninitializedObject,则合并为Object对象,大致可以获知漏洞产生的原因,在执行到这句的时候如果两个对象中有一个是数组,在合并时数组会被当作对象来处理,优化过程中引擎把合并的数组当作了对象,那么对数组类型是否改变的检测当然就不被需要,于是最终导致了类型混淆。

3. 总结
在过去一年左右,JIT编译优化过程中的类型混淆是Chakra漏洞挖掘方面的一个主要关注点。从早期的利用未被保护的回调和正常函数来修改数组类型,再到寻找验证过程中的逻辑问题,利用数组的MissingItem特性,将数组伪装成其他类型对象思路,我们可以看到随着研究者对Chakra引擎的深入研究,漏洞产生的位置已经从简单的对象方法慢慢向JIT优化代码生成过程中产生的各种逻辑和判断问题靠拢,漏洞挖掘的门槛也有了显著的提升。
启明星辰积极防御实验室(ADLab)
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员。截止目前,ADLab通过CVE发布Windows、Linux、Unix等操作系统安全或软件漏洞近400个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。

以上是 Chakra 引擎中 JIT 编译优化过程中的数组类型混淆漏洞分析 的全部内容, 来源链接: utcz.com/p/199183.html