请帮我根据需求设计一个数据库,和查询语句
需求是这样的:
一个公司去的一群人吃饭,AA制的。人数不确定,哪个人付钱也不确定,一个月后结算。查询:谁要付钱,付多少钱,谁要拿钱,拿多少钱?
我现在是这样设计的
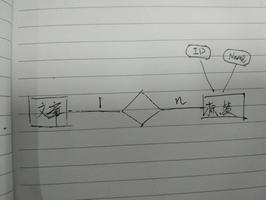
比如差小明要付多少钱,日期就不说了
先从左边表中查出所有payed_by是小明的(小明共付了多少钱)
select payed_by,sum(money) from t1 where payed_by = "小明" group by payed_by 然后从右边表中查出小明欠的钱
select eaten_by,sum(part_money) from t2 where eaten_by = "小明" and is_pay = "N"group by eaten_by
然后两个值减一减
但是如果说把所有的人都找出来,不止小明的,sql语句也要写一起,不能再java里计算,该怎么写呢?最好能设计出一个更好的表哈哈。
回答:
之前有一个人问了你一样的问题,你们参加了同一家的面试么。。里面有我的回答:
https://segmentfault.com/q/10...
回答:
这种“历史数据”,基于“事实”建立模型,很容易理解。针对这个场景,你只要记录好“吃饭”这个事实,所有数据就很容易算了。
吃饭这个事实,无非就是:
| 字段code | 解释 |
|---|---|
| user | 谁 |
| gmt_create | 在什么时候 |
| dinner | 吃了什么饭 |
| pay | 付了多少钱 |
| volumn | 在哪个结算期 |
数据大概看起来像:
| gmt_date | user | gmt_create | dinner | pay | volumn |
|---|---|---|---|---|---|
| 2017-01-01 | 黄忠 | 2017-01-01 00:00:00 | 2017-01-01 | 21 | 2017-1 |
| 2017-01-02 | 铠 | 2017-01-02 00:00:00 | 2017-01-02 | 0 | 2017-1 |
| 2017-01-02 | 东皇太一 | 2017-01-02 00:00:00 | 2017-01-02 | 616 | 2017-1 |
| 2017-01-02 | 诸葛亮 | 2017-01-02 00:00:00 | 2017-01-02 | 0 | 2017-1 |
| 2017-01-02 | 干将莫邪 | 2017-01-02 00:00:00 | 2017-01-02 | 0 | 2017-1 |
这里说明几点:
gmt_date是我使用的系统中需要的一个日期索引,跟题目无关,不用管它。dinner这里就用日期表示了,因为假设 1 天吃 1 次,真实场景,这里应该用某次饭局的 id 。pay是当时付钱的情况,假设 1 个人付了所有钱,其它人付的钱都是 0 了。volumn是结算期,这里假设每月 1 次,所有就用“年-月”来表示了,真实场景,这里可以用结算期 id 。
好了,后面会传上生成这些测试数据的代码。
事实数据有了,接下来计算就简单了。
第一步,计算每次饭局,平均每个应该给多少钱:
SELECT dinner,
sum(pay) / count(user)
FROM demo
GROUP BY dinner
LIMIT 10
结果大概是:
| dinner | dinner_avg |
|---|---|
| 2017-02-15 | 4 |
| 2018-04-29 | 79 |
| 2017-06-28 | 167 |
| 2017-11-04 | 138.28571428571428 |
| 2017-11-26 | 468 |
| 2018-03-15 | 119.75 |
| 2017-01-14 | 118.85714285714286 |
第二步,计算每个人,在每次饭局中,钱的差额(是应该补钱还是拿钱):
SELECT user,
dinner,
dinner_avg - pay AS to_pay
FROM demo
ANY LEFT JOIN
(
SELECT
dinner,
sum(pay) / count(user) AS dinner_avg
FROM demo
GROUP BY dinner
) USING (dinner)
LIMIT 10
( MySQL 中的 sql 语法可能与这里的不同,但是 left join 意思是一样的)
结果大概是:
| user | dinner | to_pay |
|---|---|---|
| 东皇太一 | 2017-01-02 | -462 |
| 东皇太一 | 2017-01-03 | 42.5 |
| 东皇太一 | 2017-01-06 | 108.5 |
| 东皇太一 | 2017-01-07 | 13.8 |
| 东皇太一 | 2017-01-10 | -677.25 |
| 东皇太一 | 2017-01-12 | 134.33333333333334 |
| 东皇太一 | 2017-01-13 | 162.5 |
| 东皇太一 | 2017-01-14 | 118.85714285714286 |
| 东皇太一 | 2017-01-17 | 10.25 |
| 东皇太一 | 2017-01-18 | 8.4 |
第三步,根据 volumn 聚合每个人,每次 volumn 的,差额的 sum :
SELECT user,
volumn,
sum(to_pay)
FROM
(
SELECT
*,
dinner_avg - pay AS to_pay
FROM demo
ANY LEFT JOIN
(
SELECT
dinner,
sum(pay) / count(user) AS dinner_avg
FROM demo
GROUP BY dinner
ORDER BY dinner ASC
) USING (dinner)
)
GROUP BY
user,
volumn
ORDER BY volumn ASC
LIMIT 20
结果大概就是:
| user | volumn | sum(to_pay) |
|---|---|---|
| 鬼谷子 | 2017-1 | 1059.5500000000002 |
| 诸葛亮 | 2017-1 | -1540.6238095238093 |
| 黄忠 | 2017-1 | 333.48333333333335 |
| 大乔 | 2017-1 | -395.26190476190465 |
| 东皇太一 | 2017-1 | -655.7833333333332 |
| 哪吒 | 2017-1 | 1250.8833333333332 |
| 铠 | 2017-1 | 533.0666666666668 |
| 干将莫邪 | 2017-1 | -585.3142857142856 |
| 黄忠 | 2017-10 | 497.72619047619054 |
就这样,上面的过程不是在 MySQL 中执行的,但是道理是一样的。
附,生成测试数据的代码:
# -*- coding: utf-8 -*-'有这些人可能会去吃饭'
USER_SET = [u'铠', u'鬼谷子', u'干将莫邪', u'东皇太一', u'大乔', u'黄忠', u'诸葛亮', u'哪吒']
'每次呢, 大家都随机'
def get_user_once():
import random
random.shuffle(USER_SET)
return USER_SET[0:random.randint(1, len(USER_SET) + 1)]
'看看效果'
print get_user_once()
print get_user_once()
print get_user_once()
print get_user_once()
'时间上, 假设2年吧, 从2017-1-1开始, 到2018-12-31为止, 每天吃1次'
import datetime
class DateIter(object):
def __init__(self):
self.current = datetime.datetime(2017, 1, 1) - datetime.timedelta(days=1)
self.stop_date = datetime.datetime(2018, 12, 31)
def __iter__(self):
return self
def next(self):
self.current = self.current + datetime.timedelta(days=1)
if self.current > self.stop_date:
raise StopIteration()
return self.current
'试一下日期'
o = DateIter()
for i in o:
#print i
continue
'按每天生成吃饭的事实, dinner 就用日期代替, volumn 就用年月代替'
class Dinner(DateIter):
def next(self):
self.current = self.current + datetime.timedelta(days=1)
if self.current > self.stop_date:
raise StopIteration()
user_set = get_user_once()
sql = 'insert into demo(gmt_date, user, gmt_create, dinner, pay, volumn) values %s;'
value_list = []
import random
'假设第一个人付所有钱'
for i, u in enumerate(user_set):
dt_str = self.current.isoformat() #2017-08-06T23:06:14.346078
value_list.append([dt_str.split('T', 1)[0], #gmt_date 2017-08-06
u, #user
dt_str.replace('T', ' ').split('.', 1)[0], #gmt_create 2017-08-06 23:06:14
dt_str.split('T', 1)[0], #dinner 2017-08-06
random.randint(1, 1000) if i == 0 else 0, #pay 289
str(self.current.year) + '-' + str(self.current.month), #volumn 2017-8
])
'生成 sql'
sql_value_list = []
for p in value_list:
sql_value_list.append('(' + ', '.join(("'%s'" if not isinstance(x, int) else '%s') % x for x in p) + ')' )
return sql % (','.join(sql_value_list))
'试一下'
o = Dinner()
for i in o:
print i
break
'输出到文件'
o = Dinner()
for i in o:
#print >> open('demo.sql', 'a'), i.encode('utf8')
continue
'写库'
o = Dinner()
for i in o:
sql = i.encode('utf8')
url = 'http://172.17.0.2:8123/'
import urllib
res = urllib.urlopen(url, data=sql)
print res.code
回答:
不改变表,尝试一哈SQL的存储过程,定时计算每个人应该付的钱。
回答:
==============================我的答案=============================
我还是更倾向于建三张表,一张是用来存用户信息的,一张用来存订单的,一张用来存订单详细信息的
CREATE TABLE `usr` ( `uid` int(11) NOT NULL,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `meal_order` (
`id` int(11) NOT NULL,
`money` decimal(10,0) DEFAULT NULL,
`paied_by` varchar(10) DEFAULT NULL,
`create_time` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `part_order` (
`id` int(11) NOT NULL,
`father_id` int(11) NOT NULL,
`eat_by` varchar(10) DEFAULT NULL,
`part_money` decimal(10,0) DEFAULT NULL,
`is_paied` varchar(1) DEFAULT 'N'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
**meal_order和part_order设计的时候为了偷懒,没用用户的id,直接用名字了:D**
usr: 
meal_order:
part_order:
part1:
查询出所有的用户付钱的情况
SELECT usr.`name` name,SUM(CASE WHEN f.money IS NULL THEN 0 ELSE f.money END) payFROM usr LEFT JOIN
meal_order f ON usr.`name` = f.paied_by
GROUP BY usr.`name`
part2:
查询出所有用户欠钱的情况
SELECT eat_by,SUM(part_money) oweFROM part_order
WHERE is_paied = 'N'
GROUP BY eat_by
part3:
合并
SELECT pay.`name`,(pay.pay - (CASE WHEN owe.owe IS NULL THEN 0 ELSE owe.owe END)) accountFROM
(SELECT usr.`name` name,SUM(CASE WHEN f.money IS NULL THEN 0 ELSE f.money END) pay
FROM usr LEFT JOIN
meal_order f ON usr.`name` = f.paied_by
GROUP BY usr.`name`) pay
LEFT JOIN
(SELECT eat_by,SUM(part_money) owe
FROM part_order
WHERE is_paied = 'N'
GROUP BY eat_by) owe
ON pay.name = owe.eat_by
时间的话在part1里加上条件就好了
以上是 请帮我根据需求设计一个数据库,和查询语句 的全部内容, 来源链接: utcz.com/p/177087.html