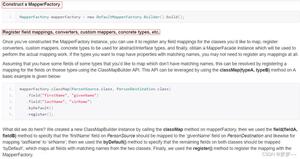
使用webmagic爬取标题
我现在有个项目需要用到webmagic进行爬取标题,但是这个网站的标题有两种格式的样式
 因为第一次写爬虫,也是第一次用这个框架,所以不是很懂怎么去写他的xpath
因为第一次写爬虫,也是第一次用这个框架,所以不是很懂怎么去写他的xpath
如果只是设置xpath("//div[@class="title"]/text()"),只能得到第二中的标题文本
第一种样式的有的标题甚至有3个<span>标签,所以我只能一个个写出来在拼接,但是这种明显不使用,
还试过使用css("div.title")会得到整个<div>标签的内容 ,但是还要在外面重新获取文本在拼接,很麻烦,而且还会得到首页大标题,
,但是还要在外面重新获取文本在拼接,很麻烦,而且还会得到首页大标题, 这不是我需要的
这不是我需要的
不知道有没有办法,在设置一个xpath或者使用css和正则表达式来完成爬取全部的标题
各位大佬帮帮忙,因为第一次接触爬虫有很多不懂,感谢感谢
回答:
只需要将xpath("//div[@class="title"]/text()")改为xpath("//div[@class="title"]/allText()")就好了
以上是 使用webmagic爬取标题 的全部内容, 来源链接: utcz.com/p/169480.html