【Java】五分钟让你彻底理解二叉树的非递归遍历
什么是二叉树
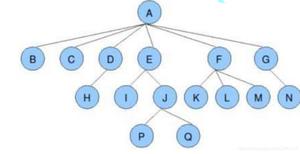
在计算机科学中二叉树,binary tree,是一种数据结构,在该数据结构中每个节点最多有两个子节点,如图所示:

二叉树的定义就是这样简单,但这种看起来很简单的数据结构遍历起来一点都不简单。
如何遍历二叉树
所谓遍历简单的讲就好比在迷宫中寻宝,宝物就藏在某一个树节点当中,但我们并不知道具体在哪个节点上,因此要找到宝物就需要将全部的树节点系统性的搜索一遍。
那么该怎么系统性的搜索一遍二叉树呢?
给定一个单链表你几乎不需要思考就能知道该如何遍历,很简单,拿到头节点后处理当前节点,然后拿到头节点的下一个节点(next)重复上述过程直到节点为空。
你会看到遍历链表的规则很简单,原因就在于链表本身足够简单,就是一条线,但是二叉树不一样,二叉树不是一条简单的"线",而是一张三角形的"网"。
那么给定一棵二叉树,你该如何遍历呢?以上图为例,你该如何系统性的搜索一遍所有的节点呢(1,2,3,4,5,6)?
有的同学可能已经看出来了,我们可以一层一层的搜索,依次从左到右遍历每一层节点,直到当前层没有节点为止,这是二叉树的一种遍历方法。树的这种层级遍历方法利用了树的深度这一信息(相对于根节点来说),同一层的节点其深度相同,那么我们是不是可以利用树有左右子树这一特点来进行遍历呢?答案是肯定的。
如上图所示1的左子树是2,2的左子树是3,2的右子树是4。。。
假设我们首先遍历根节点1,然后呢,你可能会想然后遍历2的左子树吧,也就是2,当我们到了2这个节点之后再怎么办呢?要遍历2的右子树吗?显然我们不应该去遍历2的右子树,为什么?原因很简单,因为从节点1到节点2我们是沿着左子树的方向来遍历的,我们没有理由到节点2的时候改变这一规则,接下来我们继续沿用这一规则,也就是首先遍历左子树。
我们来到了节点3,节点3的左子树为空,因此无需遍历,然后呢?显然我们应该遍历节点3的右子树,但是3的右子树也为空,这时以3为根节点的树全部遍历完毕。
当遍历完节点3后该怎么办呢?如果你在迷宫中位于节点3,此时节点3已经是死胡同了,因此你需要做的就是沿着来时的路原路返回,回退到上一个节点也就是3的父节点2,这在计算机算法中被称为回溯,这是系统性搜索过程中常见的操作,回到2后我们发现2的左子树已经搜索完毕,因此接下来需要搜索的就是2的右子树也就是节点4,因为节点4还没有被搜索过,当来到节点4后我们可以继续使用上述规则直到这颗树种所有的节点搜索完毕为止,为什么到节点4的时候可以继续沿用之前的规则,原因很简单,因为以4为根节点的子树本身也是一棵树,因此上述规则同样适用。
因此总结一下该规则就是:
处理当前节点;搜索当前节点的左子树;
左子树搜索完毕后搜索当前节点的右子树;
复制代码
这种先处理当前节点,然后再处理当前节点的左子树和右子树的遍历方式被称为先序遍历(pre_order);当然我们也可以先遍历左子树,然后处理当前节点再遍历右子树,这种遍历顺序被称为中序遍历(in_order);也可以先遍历左子树再遍历右子树,最后处理当前节点,这种遍历顺序被称为后序遍历(post_order)。
递归实现遍历二叉树
在讲解递归遍历二叉树前我们首先用代码表示一下二叉树的结构:
struct tree {struct tree* left;
struct tree* right;
int value;
};
复制代码
从定义上我们可以看出树本身就是递归定义的,二叉树的左子树是二叉树(struct tree left),二叉树的右子树也是二叉树(struct tree right)。假设给定一颗二叉树t,我们该如何遍历这颗二叉树呢?
struct tree* t; // 给定一颗二叉树复制代码
有的同学可能会觉得二叉树的遍历是一个非常复杂的过程,真的是这样的吗?
我们再来看一下上一节中遍历二叉树的规则:
处理当前节点;搜索当前节点的左子树;
左子树搜索完毕后搜索当前节点的右子树;
复制代码
假设我们已经实现了树的遍历函数,这个函数是这样定义的:
void search_tree(struct tree* t);复制代码
只要调用search_tree函数我们就能把一棵树的所有节点打印出来:
struct tree* t; // 给定一颗二叉树search_tree(t); // 打印二叉树所有节点
复制代码
要是真的有这样一个函数实际上我们的任务就完成了,如果我问你用这个函数把树t的左子树节点都打印出来该怎么写代码你肯定会觉得侮辱智商,很简单啊,不就是把树t的左子树传给search_tree这个函数吗?
seartch_tree(t->left); // 打印树t的左子树复制代码
那么打印树t的右子树呢?同样easy啊
search_tree(t->right); // 打印树t的右子树复制代码
是不是很简单,那么打印当前节点的值呢?你肯定已经懒得搭理我了 :)
printf("%d ", t->value); // 打印根节点的值复制代码
至此我们可以打印出根节点的值,也可以打印出树t的左子树节点,也可以打印出树t的右子树节点,如果我问你既然这些问题都解决了,那么该如何实现search_tree()这个函数?
如果你不知道,那么就该我说这句话了:很简单啊有没有,不就是把上面几行代码写在一起嘛
void search_tree(struct tree* t) {printf("%d ", t->value); // 打印根节点的值
seartch_tree(t->left); // 打印树t的左子树
search_tree(t->right); // 打印树t的右子树
}
复制代码
是不是很简单,是不是很easy,惊喜不惊喜,意外不意外,我们在仅仅只靠给出函数定义并凭借丰富想象的情况下就把这个函数给实现了 :)
上述代码完美符合之前定义的规则。
当然我们需要对特殊情况进行处理,如果给定的一棵树为空,那么直接返回,最终代码就是:
void search_tree(struct tree* t) {if (t == NULL) // 如果是一颗空树则直接返回
return;
printf("%d ", t->value); // 打印根节点的值
seartch_tree(t->left); // 打印树t的左子树
search_tree(t->right); // 打印树t的右子树
}
复制代码
有的同学可能会一脸懵逼,这个函数就这样实现了?正确吗,不用怀疑,这段代码无比正确,你可以自己构造一棵树并试着运行一下这段代码。
上述代码就是树的递归遍历。
我知道这些一脸懵逼的同学心里的怎么想的,这段代码看上去确实正确,运行起来也正确,那么这段代码的运行过程是什么样的呢?
递归调用过程
假设有这样一段代码:
void C() {}
void A() {
B();
}
void main() {
A();
}
复制代码
A()会调用B(),B()会调用C(),那么函数调用过程如图所示:

实际上每一个函数被调用时都有对应的一段内存,这段内存中保存了调用该函数时传入的参数以及函数中定义的局部变量,这段内存被称为函数帧,函数的调用过程具有数据结构中栈的性质,也就是先进后出,比如当函数C()执行完毕后该函数对应的函数帧释放并回到函数B,函数B执行完毕后对应的函数帧被释放并回到函数A。
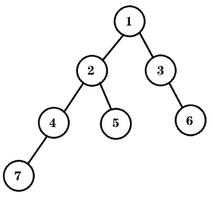
有了上述知识我们就可以看一下树的递归调用函数是如何执行的了。为简单起见,我们给定一颗比较简单的树:

当在该树上调用search_tree函数时整个递归调用过程是怎样的呢,如图所示:

首先在根节点1上调用search_tree(),当打印完当前节点的值后在1的左子树节点上调用search_tree,这时第二个函数帧入栈;打印完当前节点的值(2)后在2的左子树上调用search_tree,这样第三个函数帧入栈;同样是打印完当前节点的值后(3)在3的左子树上调用search_tree,第四个函数帧入栈;由于3的左子树为空,因此第四个函数帧执行第一句时就会退出,因此我们又来到了第三个函数帧,此时节点3的左子树遍历完毕,因此开始在3的右子树节点上调用search_tree,接下来的过程如图所示:

这个过程会一直持续直到节点1的右子树也遍历完毕后整个递归调用过程运行完毕。注意,函数帧中实际上不会包含代码,这里为方便观察search_tree的递归调用过程才加上去的。上图中没有将整个调用过程全部展示出来,大家可以自行推导节点5和节点6是如何遍历的。
从这个过程中我们可以看到,函数的递归调用其实没什么神秘的,和普通函数调用其实是一样的,只不过递归函数的特殊之处在于调用的不是其它函数而是本身。
从上面的函数调用过程可以得出一个重要的结论,那就是递归函数不会一直调用下去,否则就是栈溢出了,即著名的Stack Overflow,那么递归函数调用栈在什么情况下就不再增长了呢,在这个例子中就是当给定的树已经为空时递归函数调用栈将不再增长,因此对于递归函数我们必须指明在什么情况下递归函数将直接返回,也就是常说的递归函数的出口。
递归实现树的三种遍历方法
到目前为止,我们已经知道了该如何遍历树、如何用代码实现以及代码的调用过程,注意打印语句的位置:
printf("%d ", t->value); // 打印根节点的值seartch_tree(t->left); // 打印树t的左子树
search_tree(t->right); // 打印树t的右子树
复制代码
中序和后序遍历都可以很容易的用递归遍历方法来实现,如下为中序遍历:
void search_in_order(struct tree* t) {if (t == NULL) // 如果是一颗空树则直接返回
return;
search_in_order(t->left); // 打印树t的左子树
printf("%d ", t->value); // 打印根节点的值
search_in_order(t->right); // 打印树t的右子树
}
复制代码
后序遍历则为:
void search_post_order(struct tree* t) {if (t == NULL) // 如果是一颗空树则直接返回
return;
search_in_order(t->left); // 打印树t的左子树
search_in_order(t->right); // 打印树t的右子树
printf("%d ", t->value); // 打印根节点的值
}
复制代码
至此,有的同学可能会觉得树的遍历简直是太简单了,那么如果让你用非递归的方式来实现树的遍历你该怎么实现呢?
_在阅读下面的内容之前请确保你已经真正理解了前几节的内容_。
如果你还是不能彻底理解请再多仔细阅读几遍。
如何将递归转为非递归
虽然递归实现简单,但是递归函数有自己特定的问题,比如递归调用会耗费很多的栈空间,也就是内存,同时该过程较为耗时,因此其性能通常不及非递归版本。
那么我们该如何实现非递归的遍历树呢?
要解决这个问题,我们必须清楚的理解递归函数的调用过程。
从递归函数的调用过程可以看出,递归调用无非就是函数帧入栈出栈的过程,因此我们可以直接使用栈来模拟这个过程,只不过栈中保存的不是函数而是树节点。
确定用栈来模拟递归调用这一点后,接下来我们就必须明确两件事:
- 什么情况下入栈
- 什么情况下出栈
我们还是以先序遍历为例来说明。
仔细观察递归调用的过程,我们会发现这样的规律:
- 不管三七二十一先把从根节点开始的所有左子树节点放入栈中
- 查看栈顶元素,如果栈顶元素有右子树那么右子树入栈并以右子树为新的根节点重复过程1直到栈空为止
现在我们可以回答这两个问题了。
什么情况下入栈?
最开始时先把从根节点开始的所有左子树节点放入栈中,第二步中如果栈顶有右子树那么重复过程1,这两种情况下会入栈。
那么什么情况下出栈呢?
当查看栈顶元素时实际上我们就可以直接pop掉栈顶元素了,这是和递归调用不同的一点,为什么呢?因为查看栈顶节点时我们可以确定一点事,那就是当前节点的左子树一定已经处理完毕了,因此对于栈顶元素来说我们需要的仅仅是其右子树的信息,拿到右子树信息后栈顶节点就可以pop掉了。
因此上面的描述用代码来表示就是:
void search(tree* root) {if(root == NULL)
return ;
stack<tree*>s;
// 不管三七二十一先把从根节点开始的所有左子树节点放入栈中
while(root){
s.push(root);
root=root->left;
}
while(!s.empty()){
// 查看栈顶元素,如果栈顶元素有右子树那么右子树入栈并重复过程1直到栈空为止
tree* top = s.top();
tree* t = top->right;
s.pop();
while(t){
s.push(t);
t = t->left;
}
}
return r;
}
复制代码
上述代码是实现树的三种非递归遍历的基础,请务必理解。
接下来就可以实现树的三种非递归遍历了。
实现二叉树的非递归遍历
有的同学可能已经注意到了,上一节中的代码中没有printf语句,如果让你利用上面的代码以先序遍历方式打印节点该怎么实现呢?如果你真的已经理解了上述代码那么就非常简单了,对于先序遍历来说,我们只需要在节点入栈之前打印出来就可以了:
void search_pre_order(tree* root) {if(root == NULL)
return ;
stack<tree*>s;
// 不管三七二十一先把从根节点开始的所有左子树节点放入栈中
while(root){
printf("%d ", root->value); // 节点入栈前打印
s.push(root);
root=root->left;
}
while(!s.empty()){
// 查看栈顶元素,如果栈顶元素有右子树那么右子树入栈并重复过程1直到栈空为止
tree* top = s.top();
tree* t = top->right;
s.pop();
while(t){
printf("%d ", root->value); // 节点入栈前打印
s.push(t);
t = t->left;
}
}
return r;
}
复制代码
那么对于中序遍历呢?实际上也非常简单,我们只需要在节点pop时打印就可以了:
void search_in_order(tree* root) {if(root == NULL)
return ;
stack<tree*>s;
// 不管三七二十一先把从根节点开始的所有左子树节点放入栈中
while(root){
s.push(root);
root=root->left;
}
while(!s.empty()){
// 查看栈顶元素,如果栈顶元素有右子树那么右子树入栈并重复过程1直到栈空为止
tree* top = s.top();
printf("%d ", top->value); // 节点pop时打印
tree* t = top->right;
s.pop();
while(t){
s.push(t);
t = t->left;
}
}
return r;
}
复制代码
对于后续遍历呢?
后续遍历相对复杂,原因就在于出栈的情况不一样了。
在先序和中序遍历过程中,只要左子树处理完毕实际上栈顶元素就可以出栈了,但是后续遍历情况不同,什么是后续遍历?只有左子树和右子树都遍历完毕才可以处理当前节点,这是后续遍历,那么我们该如何知道当前节点的左子树和右子树都处理完了呢?
显然我们需要某种方法记录下遍历的过程,实际上我们只需要记录下遍历的前一个节点就足够了。
如果我们知道了遍历过程中的前一个节点,那么我们就可以做如下判断了:
- 如果前一个节点是当前节点的右子树,那么说明右子树遍历完毕可以pop了
- 如果前一个节点是当前节点的左子树而且当前节点右子树为空,那么说明可以pop了
- 如果当前节点的左子树和右子树都为空,也就是叶子节点那么说明可以pop了
这样什么情况下出栈的问题就解决了,如果不符合这些情况就不能出栈。
只需要根据以上分析对代码稍加修改就可以了:
void search_post_order(tree* root) {if(root == NULL)
return ;
stack<tree*>s;
TreeNode* last=NULL; // 记录遍历的前一个节点
// 不管三七二十一先把从根节点开始的所有左子树节点放入栈中
while(root){
s.push(root);
root=root->left;
}
while(!s.empty()){
tree* top = s.top();
if (top->left ==NULL && top->right == NULL || // 当前节点为叶子节点
last==top->right || // 前一个节点为当前节点的右子树
top->right==NULL && last==top->left){ // 前一个节点为当前节点左子树且右子树为空
printf("%d ", top->value); // 节点pop时打印
last = top; // 记录下前一个节点
s.pop();
} else {
tree* t = top->right;
while(t){
s.push(t);
t = t->left;
}
}
}
return r;
}
复制代码
《2020最新Java基础精讲视频教程和学习路线!》
总结
树的递归遍历相对简单且容易理解,但是递归调用实际上隐藏了相对复杂的遍历过程,要想以非递归的方式来遍历二叉树就需要仔细理解递归调用过程。
链接:https://juejin.cn/post/691119...
以上是 【Java】五分钟让你彻底理解二叉树的非递归遍历 的全部内容, 来源链接: utcz.com/a/90197.html