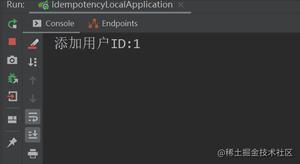
两个数据量很大的集合求差集的高效方法
如题,两个集合如 List<String>,每个集合的数据量可能在 50-100w之间,如何 高效的计算出 list-1 diff list-2 的结果,耗时 以及内存占用 尽可能优
可以使用任何一切手段,如 调用脚本等
回答
public List<String> complement(List<String> l1, List<String> l2) { HashSet<String> s2 = new HashSet<>(l2);
l1.forEach(s2::remove);
return new ArrayList<>(s2);
}
在一楼的基础上 用多线程 对集合分块剔除 最后在合并结果 只要线程够多 快到你无法想象
其次 用底层语言 机器指令最好
硬件方面 如果一台不行 加机器 加内存 加cpu 还不行 考虑大数据方面吧 终极方案 干掉出问题的人
推荐google的guava,Sets.difference(set1,set2)即可,既然是求差集,应该优先排除重复元素
以上是 两个数据量很大的集合求差集的高效方法 的全部内容, 来源链接: utcz.com/a/85526.html