【mysql】SQL查询唯一字段时加上LIMIT 1会不会更快?
比如,用户的username是无重复的,如果查询某个username,可能他会把整个表都搜一遍。
如果我加入了LIMIT 1,他会不会在搜到这个username后立即停止搜索并返回呢?
这种情况下速度是不是就会快一点啊?
回答
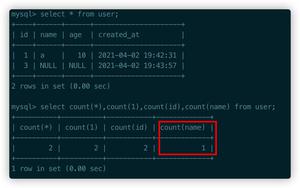
where 和 limit 都具有 避免全表扫描 的功能 (mysql),区别在于:where能够充分利用 索引,而limit 能够限制查询行数
limit的存在主要是为了防止 全表扫描,如果一个语句本身可以得出不用全表扫描,有没有limit 那么性能的差别是不大的,比如唯一索引,主键 [没试验过,NND]
对于偏移量offset较大的查询,建议用好where语句,来避免全表扫描;因为limit本身没有利用索引的缩小范围能力
对于任何一个查询,首先应该想到的是如何利用 where 语句来 缩小范围,然后利用limit来限制返回行数
如果没有加索引,加了limit反而更慢。刚才试了一下
如果username字段建立了unique索引,加limit就没有意义。因为对于唯一索引数据库的实现是B-Tree查找,精确查询到唯一一个结果
limit只是控制了返回的行数,不控制实际查询的。可以用explain检验
遇到数据量比较大的表用limit会搞死数据库的
以前后到都说加LIMIT 1会加快速度
为什么不利用where的唯一索引(比如username)。limit 只是限制显示的条目吧
以上是 【mysql】SQL查询唯一字段时加上LIMIT 1会不会更快? 的全部内容, 来源链接: utcz.com/a/72104.html