换服务器后scrapy项目运行不了,yield不能发起第三层链接的Request, 报错StopIteration
- 我的一个爬虫项目在阿里服务器上Win2012系统运行了半年了,但换了腾讯服务器后换了Win10系统版本不一样,代码就运行不了。
- 我把代码缩减到最简单的形式
class WefspiderSpider(scrapy.Spider):name = 'wefunderspider'
start_urls = ['https://wefunder.com/explore']
def parse(self, response):
campain_list_url = 'https://wefunder.com/explore_render_cards?'
yield scrapy.FormRequest(
url = campain_list_url,
#meta = meta,
formdata = {"type":'fundraising',"page":'1',"first_offset":'0'},
callback = self.parse_campainlist_page)
def parse_campainlist_page(self,response):
campain_list = response.xpath("//div[contains(@class,'card effect__click ')]").extract()
campain_num = len(campain_list)
print(campain_num) #调试通过
print('roempost可行')
campain_name = response.xpath("//div[contains(@class,'card effect__click')][%s]/a/@href"%1).extract()[0].split('/')[-1]
campain_url = 'https://wefunder.com/' + campain_name +'/about'
yield scrapy.Request(url = campain_url,callback = self.parse_campain_page,dont_filter=True)#meta = meta,
def parse_campain_page(self,response):
print('可访问')
我把代码一点点增加地跑,以上代码是能跑通的,但再加一层yield Request就不行,也就是爬取两层链接是可以的,但第三层就不行,继续添加以下代码
yield scrapy.Request(url = campain_url,callback = self.parse_campain_page,dont_filter=True)#meta = meta,def parse_campain_page(self,response):
print('可访问')
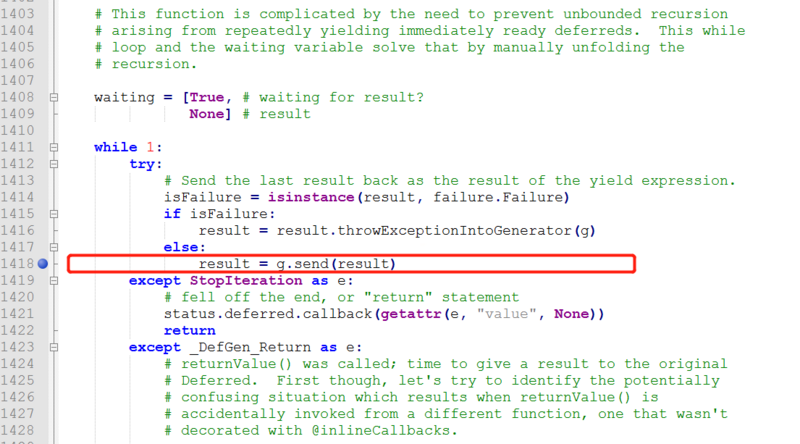
报错StopIteration,并且伴随有奇怪的IndentationError。但代码本身没有对齐错误

以下是错误中对应的defer.py报错的代码行
找了好久没有类似的问题,不是请求被过滤了,而是不能解析,请大神拯救,
回答
大神们快来帮我看看吧~感恩
如果是同一套代码,那可能是 python 版本的问题?比如 python3.5 和 python3.6 就是一个大的版本,很多库是不兼容的。
以上是 换服务器后scrapy项目运行不了,yield不能发起第三层链接的Request, 报错StopIteration 的全部内容, 来源链接: utcz.com/a/40273.html