查询分布式表有点慢,感觉有问题,请帮忙分析一下
我导入csv数据到DolphinDB分布式表中,代码如下:
db = database("dfs://kqdb", VALUE, 1970.01M..2020.12M)pt = db.loadTextEx(db, `kq,`time, "/usr/database/kq.csv");
导入后,我查询一年的数据,代码如下:
kq=database("dfs://kqdb").loadTable("kq")select count(*) from kq where temporalFormat(time,"yyyy-MM-dd")>='2019-01-01' and temporalFormat(time,"yyyy-MM-dd")<='2019-12-31' and grade=10 and class=1 group by status
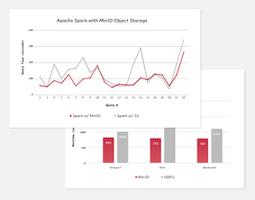
一年的数据约20多万行,查询花了31s多(如下图所示),我感觉有问题,不至于要30多秒吧?

回答
where条件要优化一下,写成如下:
select count(*) from kq where time between 2019.01.01T00:00:00 : 2019.12.31T23:59:59 and grade=10 and class=1 group by statusDolphinDB在解决海量数据的存取时,并不提供行级的索引,而是将分区作为数据库的物理索引。系统在执行分布式查询时,首先根据WHERE条件确定需要的分区。大多数分布式查询只涉及分布式表的部分分区,系统不必全表扫描,从而节省大量时间。但若不能根据where条件确定分区,就会全表扫描,影响查询性能。详情可参阅分区设计教程第7节。
以上是 查询分布式表有点慢,感觉有问题,请帮忙分析一下 的全部内容, 来源链接: utcz.com/a/38464.html