重学前端五---浏览器是如何工作的(2)
一、解析代码
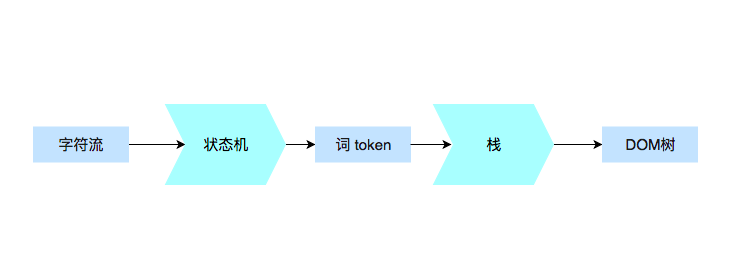
HTML 的结构不算太复杂,日常开发需要的 90% 的“词”(指编译原理的术语 token,表示最小的有意义的单元),种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种。
1、词(token)是如何被拆分的
例如:
<p class="a">text text text</p>- <p“标签开始”的开始;
- class=“a” 属性;
- >“标签开始”的结束;
- text text text 文本;
标签结束
类似

在接受第一个字符之前,我们完全无法判断这是哪一个词(token),不过,随着我们接受的字符越来越多,拼出其他的内容可能性就越来越少。
比如,假设我们接受了一个字符“ < ” 我们一下子就知道这不是一个文本节点。
之后我们再读一个字符,比如就是 x,那么就知道这不是注释和 CDATA ,接下来就一直读,直到遇到“>”或者空格,这样就得到了一个完整的词(token)。
实际上,每读入一个字符,其实都要做一次决策,而且这些决定是跟“当前状态”有关的。在这样的条件下,浏览器工程师要想实现把字符流解析成词(token),最常见的方案就是使用状态机。
2、状态机
绝大多数语言的词法部分都是用状态机实现的。那么把部分词(token)的解析画成一个状态机:
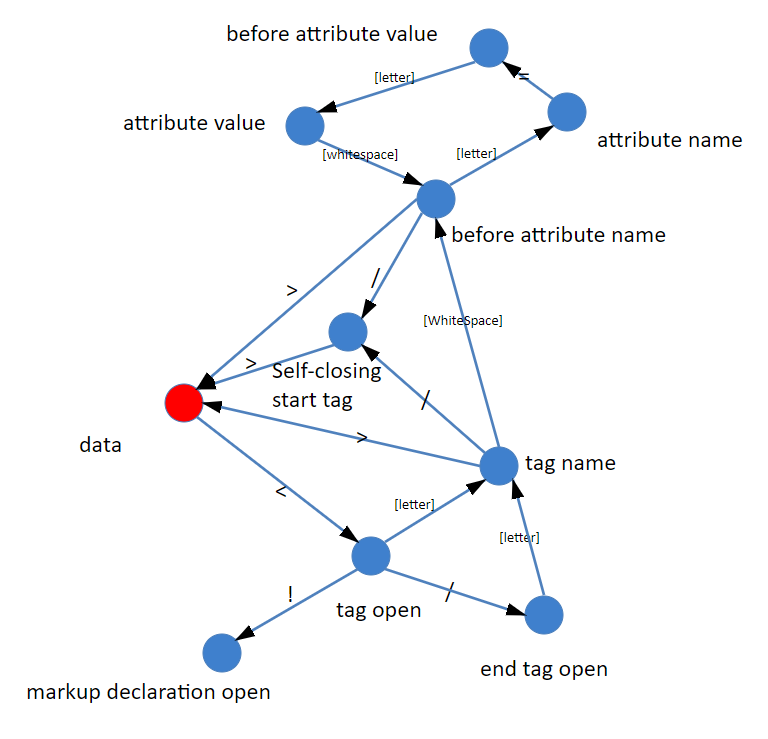
HTML 官方文档规定了 80 个状态
html.spec.whatwg.org/multipage/p…
状态机的初始状态,我们仅仅区分 “< ”和 “非 <”:
- 如果获得的是一个非 < 字符,那么可以认为进入了一个文本节点;
- 如果获得的是一个 < 字符,那么进入一个标签状态。
不过在标签状态时,则会面临着一些可能性。
- 比如下一个字符是“ ! ” ,那么很可能是进入了注释节点或者 CDATA 节点。
- 如果下一个字符是 “/ ”,那么可以确定进入了一个结束标签。
- 如果下一个字符是字母,那么可以确定进入了一个开始标签。如果我们要完整处理各种 HTML 标准中定义的东西,那么还要考虑“ ? ”“% ”等内容。
二、构建 DOM 树
- 栈顶元素就是当前节点;
- 遇到属性,就添加到当前节点;
- 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点;
- 遇到注释节点,作为当前节点的子节点;
- 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点;
- 遇到 tag end 就出栈一个节点(还可以检查是否匹配)。
www.w3.org/html/wg/dra…
以上是 重学前端五---浏览器是如何工作的(2) 的全部内容, 来源链接: utcz.com/a/33823.html