Redis动态字符串SDS源码学习
参考
redis数据结构:sds动态字符串
redis源码解读(一):基础数据结构之SDS
1. 用Simple Dynamic String 取代 C 默认的 char* 类型
Redis没有直接使用c语言的字符串,而是自己定义了一个字符串数据结构,SDS作为默认的字符串,我们设置的所有键值基本都是SDS
C语言字符串特点:
- 每次计算字符串长度
strlen(s)的时间复杂度为O(n) - 使用
终止符判定一个字符串的结尾,这种规则使得C语言的字符串是二进制不安全的 - 对字符串进行N次追加,必定需要对字符串进行N次内存重分配
那么从性能考虑,上面三个问题可以这么解决:
- 如何实现
O(1)时间复杂度的长度查询:- 使得字符串数据结构中含有自身长度属性 => 自定义字符串数据结构
- 如何实现二进制安全:
- 因为实现了
length属性,不再需要以某种特殊格式()解析数据,所以二进制安全了
- 因为实现了
- 如何减少内存重分配的次数:
- 按照一定的机制来决定拓展内存的大小,然后再执行追加操作,拓展后多余的空间不释放,方便下次再追加数组,这样的代价就是浪费了一点内存,但是实现了用空间换时间的效果
2. Redis SDS的数据结构
github 源码src/sds.h,结构体声明代码如下:
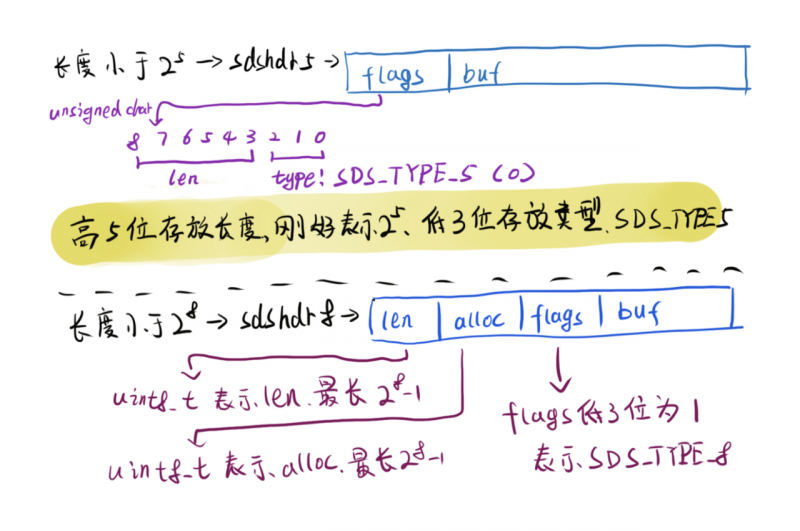
struct __attribute__ ((__packed__)) sdshdr5 {unsignedchar flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsignedchar flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsignedchar flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsignedchar flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsignedchar flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
// 通过buf获取头指针
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
上方虽然声明了sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64五种类型,但都可以概括为:
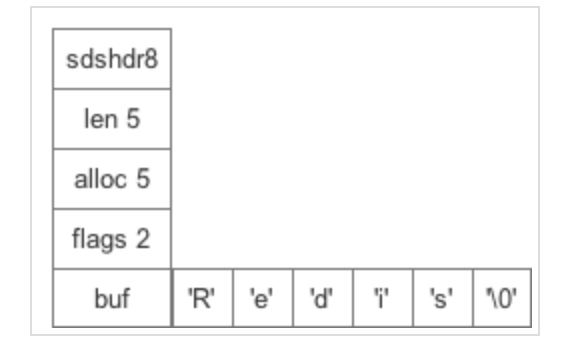
len记录当前字节数组的长度不包括alloc记录了当前字节数组总共分配的内存大小,不包括flags记录了当前字节数组的SDS_TYPEbuf保存了字符串真正的值以及末尾的一个
看看一个sdshdr8的实例, 整个SDS的内存是连续的,统一开辟的,通过这样的方式就能通过buf头指针进行寻址,拿到整个struct的指针
2.1 attribute ((packed))的作用:勤俭持家省内存
编译器内存对齐的优化策略:struct的分配的内存是内部最大元素的整数倍
其中__attribute__ ((__packed__))的作用为:告诉编译器不要对这个结构体进行优化对齐,让结构体内部的字段与字段之间紧挨在一起
printf("%ldn", sizeof(struct sdshdr8)); // 3printf("%ldn", sizeof(struct sdshdr16)); // 5
printf("%ldn", sizeof(struct sdshdr32)); // 9
printf("%ldn", sizeof(struct sdshdr64)); // 17
以sdshdr32为例,其内部最大元素为4(uint32_t占4字节),不进行内存对齐,节省了4*3 - 9 = 3字节,同理,sdshdr64节省了8*3 - 17 = 7字节。
2.2 为什么会有sdshdr5、sdshdr8等区分:勤俭持家省内存
在绝大多数场景下,没有开发者会给key取一个特别长的名字,将这些key变成sds字符串,就要在sdshdr.len中存放这些字符串的长度,如何选择len的类型?
uint8: 肯定会有字符串的长度超过2^8 - 1uint16: 肯定会有字符串的长度超过2^16 - 1uint32: 肯定会有字符串的长度超过2^32 - 1uint64: 99%的情况下字符串长度都是非常简短的,用8个字节来存长度,极端浪费
因此在创建时,先计算出字符串的长度,根据长度,把sdshdr分为几种类型,达到节省内存的效果,可以看到另一个小细节:sdshdr5直接省掉了len字段,
用高5位存放长度,低3位存放类型,所以后面的结构有/* 3 lsb of type, 5 unused bits */这样的注释
3. 创建SDS
调用:
mysds = sdsnewlan("abc", 3);解析见注释
sds sdsnewlen(constvoid *init, size_t initlen){void *sh;
sds s;
// 根据内容长度`initlen`,确定`SDS_TYPE
char type = sdsReqType(initlen);
// 空字符串使用SDS_TYPE_8类型,因为空字符串通常用于追加操作,SDS_TYPE_5不适合
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
// 获取结构体大小
int hdrlen = sdsHdrSize(type);
// flags pointer
unsignedchar *fp;
// 分配内存:结构体大小+字符串大小+1(``)
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) returnNULL;
if (init==SDS_NOINIT)
init = NULL;
elseif (!init)
// 空字符串初始化内存为0
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen;
// 获得flags指针
fp = ((unsignedchar*)s)-1;
switch(type) {
case SDS_TYPE_5: {
// SDS_TYPE_5的flags字段前5位保存长度后3位保存type
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 获得sdshdr的指针
sh->len = initlen; // 设置len
sh->alloc = initlen; // 设置alloc
*fp = type; // 设置type
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // 内存拷贝
s[initlen] = ''; // 字符数组最后一位设置为
return s;
}
4. 拼接SDS
sds sdscatlen(sds s, constvoid *t, size_t len){size_t curlen = sdslen(s); // 获取当前字符串的长度
s = sdsMakeRoomFor(s,len); // 扩容
if (s == NULL) returnNULL;
memcpy(s+curlen, t, len); // 内存拷贝
sdssetlen(s, curlen+len); // 更新len属性
s[curlen+len] = ''; // 末尾追加一个
return s;
}
重点在于sdsMakeRoomFor, 通过策略,减少拼接操作的内存分配次数
sds sdsMakeRoomFor(sds s, size_t addlen){void *sh, *newsh;
// 获取可用长度,即sh->alloc - sh->len;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 剩余空间足够,无需扩容,返回
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
// 分配策略:小于1mb,内存翻倍,否则多分配1m
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// 对于SDS_TYPE_5有一句注释:sdshdr5 is never used
type = sdsReqType(newlen);
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
// 对比扩容前后类型是否改变,做对应的处理,不重要
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) returnNULL;
s = (char*)newsh+hdrlen;
} else {
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) returnNULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
SDS总结:
- 通过
sds->len将获取字符串长度的时间复杂度降低到了O(1),进而使得字符串不受限于C字符串的终止符,实现二进制安全 - 通过内存预分配策略(小于1mb翻倍,否则增加1mb)减少拼接操作的内存重分配次数:空间换时间
- 总会在
sds->buf的末尾追加一个,在部分场景下和C语言字符串保持同样的行为 - 对于内部来说:整个SDS的内存是连续的,可以通过寻址方式定位到任意一个值
以上是 Redis动态字符串SDS源码学习 的全部内容, 来源链接: utcz.com/a/30036.html