TKEH算法
未完待续...
写在前面:本篇记录对APIN-TKEN文献上翻译的个人理解,如有错误还望指正。
Top-k高效用项集挖掘
样本
定义
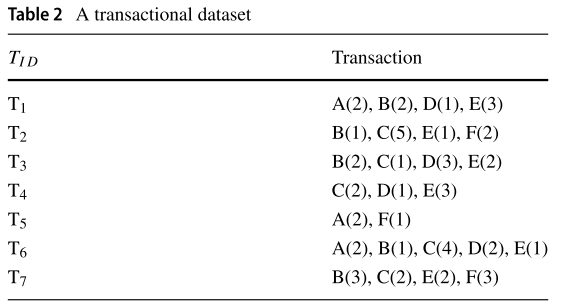
交易数据集(Transaction Dataset):设
是许多不同项的集合,项集
,其中交易项
,交易数据集
内部效用值(Internal Utility):也可以看作数量,设
,
意味着在交易项
中,项 x 的出现次数,可以参考 Table 2
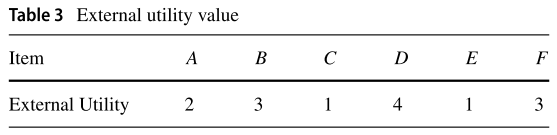
外部效用值(External Utility):也可以看作利润,设
,
意味着该项的利润值,可以参考 Table 3
Utility of an item in a transaction:是某个项在某个交易项中的效用值,计算公式如下:
Utility of an itemset in a transaction:是某个项集在某个交易项中的效用值,上一条的plus版,计算公式如下:
例如
Utility of an itemset in a dataset:是某个项集在整个交易数据集中的效用值,上一条的plus版,计算公式如下:
例如
交易项效用值(Transaction Utility):是某个交易项里所有项的效用值之和,计算公式如下:
例如
交易项权重效用值(Transaction Weighted Utility):是包含某个项集 X 的所有交易项效用值和,计算公式如下:
例如
Ps. TWU的作用在整个算法中还是很重要的,因为它具备反单调性(目的与频繁项集挖掘一致),对整个项集和交易项的排序、裁剪有很大作用,有以下性质:
- 基于估值计算TWU:当 TWU(X) >= U(X) 时,可以认为这个项集 X 的效用值被高估了【这里暂时没想到比较好的表达】
- 基于剪枝计算TWU:当 TWU(X) < minUtil 时,可以认为这个项集和它的扩展集不可能是高效用项集
剩余效用值(Remaining Utility):在某个交易项
例如 设各项排序为 A < B < C < D < E < F,
这部分与后面的交易项投影归并结合起来计算,其中各项的顺序至关重要,会直接影响到结果
效用列表结构(Utility-List Structure):这是所有single-phase的高效用模式挖掘里常见的一种结构,它可以在线性时间内完成对TWU、Secondary(α)和Primary(α)等值的计算。它包含三个部分:TID、iutil、rutil。其中 TID 就是包含项集 X 交易项的标识,iutil 是 U(X),rutil 是 RU(X, T_j)
对任意的项集 X,若 REU(X) = U(X) + RU(X) < minUtil(
),那么这个项集和它的扩展集都不是高效用项集,反之则是
Top-k high utility itemset:对于项集 X,如果有少于 k 个项的效用值大于项集 X 的效用值,那么该项集就是 top-k HUIs
TKEH算法
1.The Search Space
和其它算法一样,也采用枚举树结构来操作,使用深度遍历方法,根节点为空,对所有的项以TUW值的大小进行升序排列
补充定义
- 项扩展(Extension of an item):设 α 是一个项集,可用于扩展项集 α 的项组成的集合我们称为项扩展
(翻译一下就是在一个交易项中大于项集 α 的项组成的项集)
- 项集扩展(Extension of an itemset):设 α 是一个项集,Z 是 α 的扩展(出现在 α 的子枚举树中),当
时,Z 是 α 的一元扩展项,出现在 α 的子枚举树中;当 Z = α ∪ {z},z ∈ E(α) 时,Z 是 α 的多元扩展项
2.Concept of co-occurrence structure
在 top-k-HUIs mining 算法中最关键的就是如何让 minUtil 高效地自动增长,文中设计了一种叫 EUCST(Estimated Utility Co-occurrence Pruning Strategy with Threshold)的方法,可以同时达到增长 minUtil 和检索空间剪枝的效果
定义
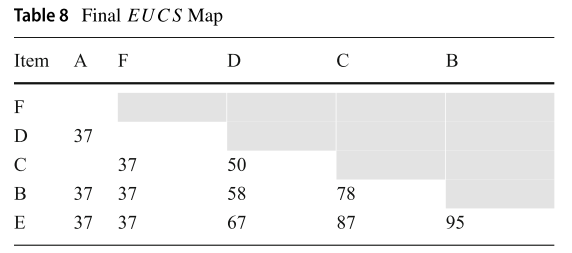
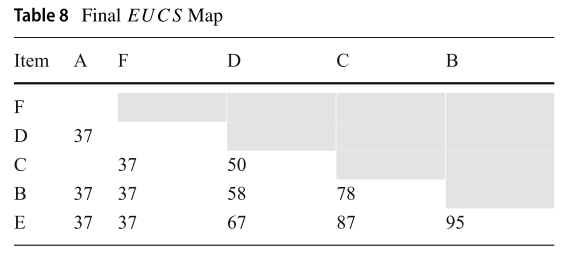
EUCS structure:是一系列元组结构,形如
,同时 (x, y, z) 定义为 TWU({x, y}) = z
例如查看Table 8 中的 第一个交易项, TWU({A, D}) = 37、TWU({D, B}) = 58
设 X 是项集,当 TWU(X) < minUtil 时,对于项集 X 的任何扩展 y∈Y,都有 U({Y, X}) < minUtil
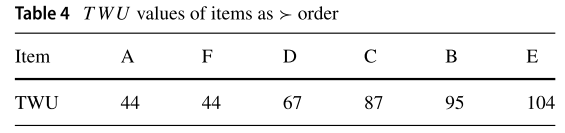
从上图来看 EUCS 结构是一种三角矩阵,但在代码实现中使用的时 hashMap,EUCS 结构只存储 TWU ≠ 0 的值。本算法第一次扫描数据集的时候计算出所有一元项的 TWU,然后进行升序排序,如Table 4:
第二次扫描构建 EUCS 结构,表格中的每个单元表示该项集的 TWU 值,如Table 5,6:
【以下几张表中的交易项和 Table 2 冲突了,那么 Table 3 在这也不适用】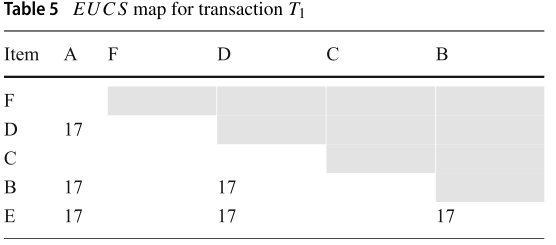
Ps. T1=(A, 4), (D, 4), (B, 6), (E, 3),在这个表中可以得到以下元组:(A,D, 17), (A, B, 17), (A, E, 17), (D, B, 17), (D, E, 17), (B, E, 17)
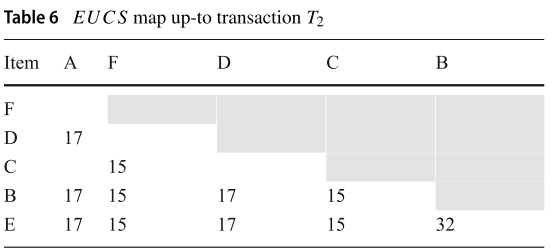
Ps. T2 = (F, 6), (C, 5), (B, 3), (E, 1),同样可以得到以下元组(F, C, 15), (F, B, 15), (F, E, 15), (C, B, 15), (C, E, 15), (B, E, 15),很明显(B, E, 15)已经存在,那我们只要把值叠加即可
经过不断叠加至所有交易项都算完,可得 Table 7:
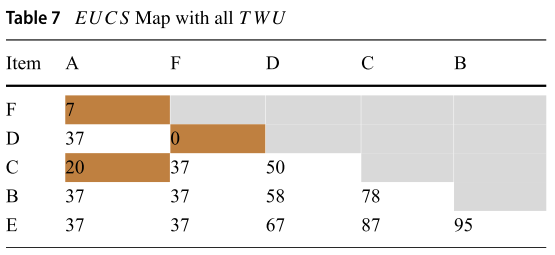
最后删除那些小于minUtil的值,得到最终结果 Table 8:
3.Dataset scanning techniques
基于 EUCS结构 的剪枝被称为 EUCP,本算法也涉及到映射和归并技术
数据集投影
补充定义
- 数据集投影(Projected Dataset):项集 α 在某个交易项上的投影设定为 α-T = {i | i ∈ T 且 i ∈ E(α)};项集 α 在数据集 D 上的投影设定为 α-D = {α-T | T ∈ D 且 α-T ≠ null}
交易项归并
在投影结束后,可能会产生某些不同的交易项投影出来的项一致(项的IU可能不一样),为此本文将这些相同地交易项合并成一条,减少扫描次数
补充定义
- 交易项归并(Transaction Merging):设存在多个交易项
,则用
来统一表示这些交易项,有
4.Threshold raising strategies
RIU strategy

该方法是由 REPT算法 提出的,全称是 Real item utilities。在第一轮扫描数据集的时候,计算 的同时也把值存入 RIU(x) 中,以列表的形式存储这些值,并对其做升序排列。然后,RIU方法将minUtil提高到排序后的RIU列表中的第k个最大值,这个值就是现在设定的阈值,直到有其它方法提高了阈值
CUD strategy

该方法是由 kHMC算法提出的,通过利用 EUCS结构 里的二元项集效用值来增加minUtil,EUCS结构包含一对TWU值大于 minUtil 的项,因此可能是一个高效用项集。为此,可以考虑再度提高阈值(使用CUD方法)用于存储这对项效用值的结构称为 CUD效用矩阵(CUDM),CUD方法是在RIU方法之后执行的。
COV strategy

该方法全称是 Coverage strategy,该方法使用COVL(coverage list)结构来成对存储项的效用值
5.Pruning strategies
基于EFIM算法的sub-tree utility剪枝策略改进版,命名为 EUCP
定义
Pruning using EUC (EUCP):设项集 X,若 TWU(X) < minUtil,那么对于任意项集 X 的扩展项 Y,有 U(XY) < minUtil
Sub-tree Utility(SU):设项集 α,且有项 x ∈ E(α) 在深度遍历项集过程中能够成为其子树,有
设项集 α,且有项 x ∈ E(α) ,其中
设项集 z = x ∪ y,则有关系
成立
Secondary(α):最开始由TWU(α)【 α 是一元项】值组成,计算公式为
Primary(α):最开始由SU(α)【 α 是一元项】值组成,计算公式为
因为有
,所以
成立
6.Calculate upper bounds using utility array
同EFIM一样,本文也使用了Utility Array结构,对每个交易项的每个项进行同层、上下累加计算,算完最后一个交易项时,有 ,计算公式分别为:
7.Main procedure of TKEH
以下是算法的核心部分伪代码:


参考
- Kuldeep Singh、Shashank Sheshar Singh、Ajay Kumar、Bhaskar Biswas: Efficient Algorithms for Mining Top-K High Utility Itemsets-
xueshu.baidu.com/s?wd=paperu…
- Top-k高效用项集挖掘_学习笔记(一) 基础概念: Erpim-blog.csdn.net/qq_35414569…
- Top-k高效用项集挖掘_学习笔记(二) TKU: Erpim-blog.csdn.net/qq_35414569…
- Top-k高效用项集挖掘_学习笔记(三) TKO: Erpim-blog.csdn.net/qq_35414569…
以上是 TKEH算法 的全部内容, 来源链接: utcz.com/a/29907.html