简明数据结构源码阅读(二)-- LinkedList
推荐阅读时间:20min+
##目录:
回顾
- ArrayList中的JDK bug的由来以及Java中的逆变和协变
LinkedList源码分析- 关键字
问题提出
- 为什么
ArrayList和LinkedList中很多的成员变量都是transient的? LinkedList如何同时实现栈和队列的功能?ArrayList中的经典的CME异常会不会也在LinkedList中重现?
- 为什么
源码分析
LinkedList源码分析
LinkedList的继承关系和文档中的关键字信息
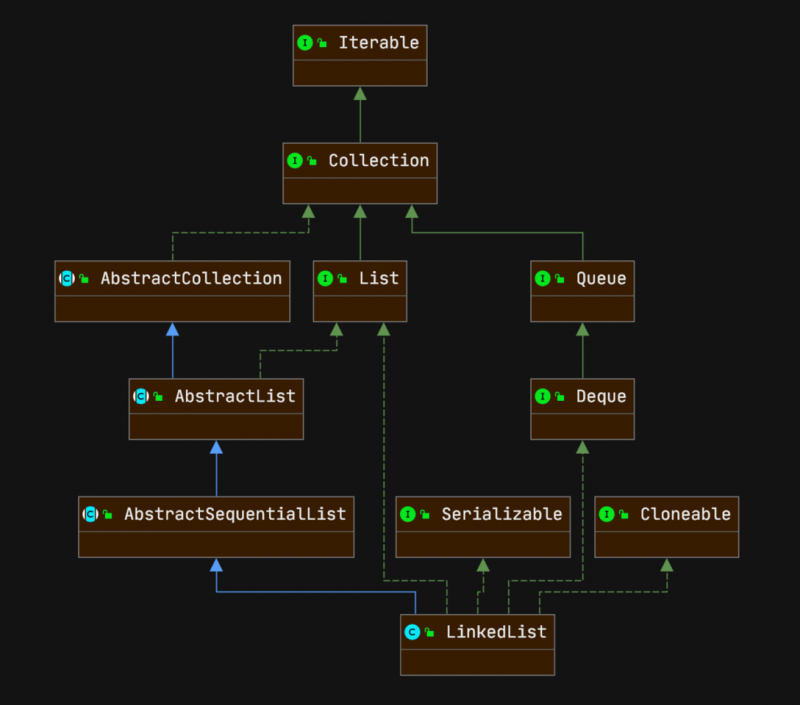
如图可以明显的看出LinkedList主要实现了Queue 接口和Deque(读作deck)接口。
通过阅读LinkedList文档和Deque的文档可以通过如下的关键字获取到这一个数据结构的信息:
- two forms
- Doubly-linked list
- not synchronized / structural modification
总结一下LinkedList和Deque文档的大意:Deque是一种支持从两端进行插入和删除的线性结构,Deque被设计为可以作为队列(Queue)和栈(Stack),而且文档中特别注明了,如果需要使用和栈相关的操作,最好使用Deque的实现,而不是legacy的Stack类。LinkedList是List和Queue的双链表实现,而且这个数据结构的所有操作都不是同步的,LinkedList的两种迭代器iterator 和 listIterator都是fail-fast的。
two forms
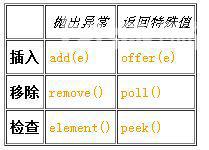
关键字中的two-form指的是insert,remove, examine 一个元素这些操作,这些操作都有两种实现,一种实现是当函数出现错误时抛出异常,另外一种实现再出现错误时会返回false或者null。

举例来说,addFirst 和offerFirst方法的区别一目了然:
void addFirst(E e);boolean offerFirst(E e);
同时Deque还列出了它实现的方法和Queue接口中的方法还有作为Stack的一种等效实现的方法的比较:

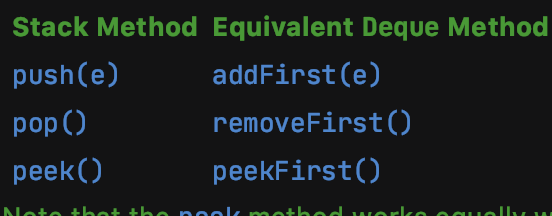
Doubly-linked list
双链表的结构如下:
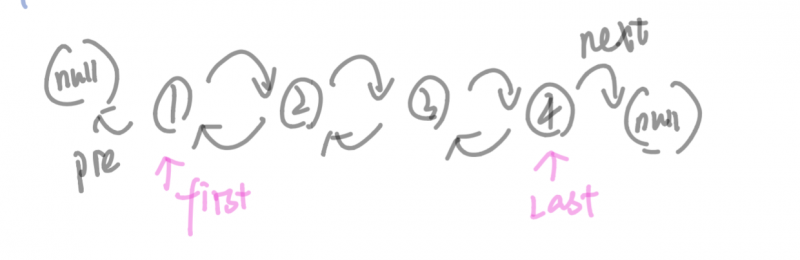
LinkedList的关键内部类Node:
private static class Node<E> {E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
静态内部类嘛,懂得都懂,就是在实例化Node的时候不会实例化一个外部类的引用,减小内存开销。
not synchronized / structural modification
说明链表时非同步的结构,但是和ArrayList区别在哪里,下面的分析会详细谈到。
本篇源码分析除了让读者能够弄清楚代码之间的调用关系之外,还主要为了解决这样几个问题:
- 为什么
ArrayList和LinkedList中很多的成员变量都是transient的? LinkedList如何同时实现栈和队列的功能?ArrayList中的经典的CME异常会不会也在LinkedList中重现?
下面会列出代码和函数的调用关系图,同时也会注重对比ArrayList和LinkedList之间的关系。
重要的常量
//初始化size为0transient int size = 0;
//first和last初始化为null 因为没有内容
transient Node<E> first;
transient Node<E> last;
设置这些成员为transient原因如下:
在序列化和反序列化过程中会反射调用readObject 和 writeObject两种方法:
private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
size被写进了输出流,同时比LinkedList这些节点本身更重要的是这些节点中的item信息。所以保存节点本身和节点和前后节点信息是没有必要的。
构造函数
LinkedList有两种构造函数:
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
//将一个Collection的内容直接存放到这个链表结尾
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 越界检查
checkPositionIndex(index);
//在ArrayList中见过的操作
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
returnfalse;
//主要目的是为了找到前驱和后继节点
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
//right-shift 连接
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
returntrue;
}
//通过一个二分的方法省去了一半的查找时间
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这个构造函数的调用过程如下。这里要注意的是LinkedList的插入过程是一个right-shift的,index后面的内容移动到右边。
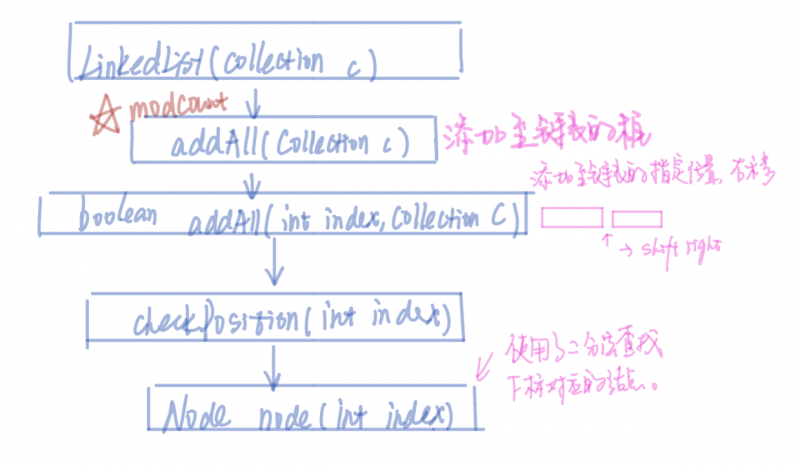
第二个addAll(int index, Collection c)修改了modCount,这里图画错了。
增
add 系列
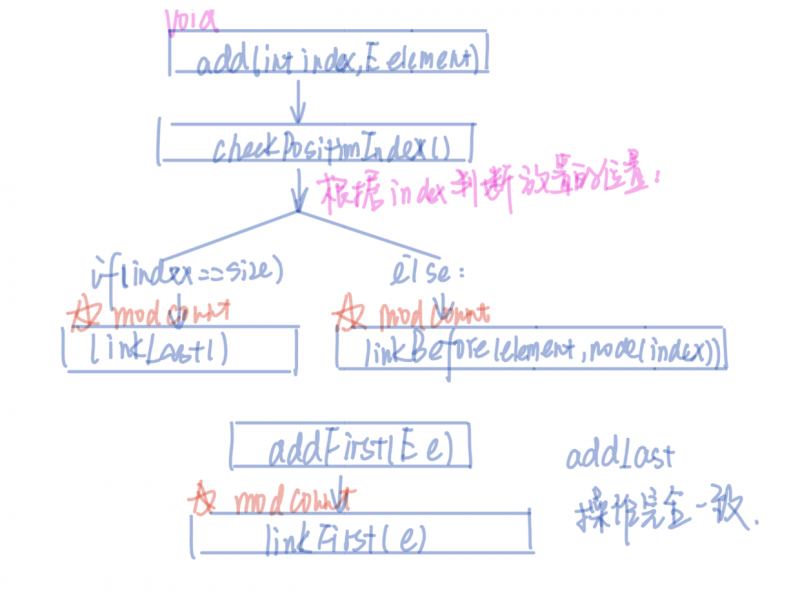
add函数家族有很多函数,addAll函数已经分析过了,它的重载函数的逻辑也没有什么特别的,直接看一下这个函数:
public void add(int index, E element) {checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
可以看出add函数是基于linkLast和linkBefore两个函数的,这两个函数帮助链表连接节点,同时根据情况是否进行right-shift操作,同时也进行modCount的计算。
public void addFirst(E e) {linkFirst(e);
}
同理addLast也是调用linkLast()这里不再赘述了。
但是因为LinkedList还实现了队列和栈的功能,所以『增』相关的操作还包括offer系列的函数和push函数:
offer系列
public boolean offer(E e) {return add(e);
}
offer函数表现的是一个将一个元素放置在链表尾部的过程(即一个队列排队到尾部的操作,由于LinkedList是一个双向链表,所以必然有两端的操作:
public boolean offerFirst(E e) {addFirst(e);
returntrue;
}
public boolean offerLast(E e) {
addLast(e);
returntrue;
}
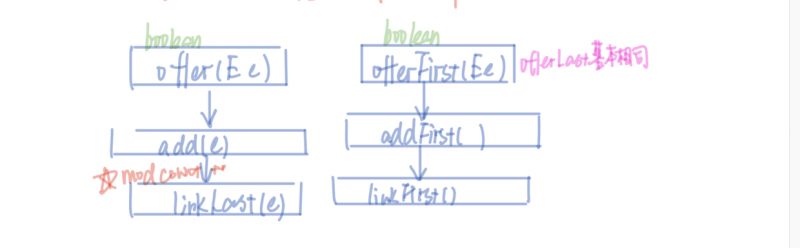
public void push(E e) {addFirst(e);
}
push操作也比较简单,这里要注意可能和大家想象的不一样的是新加入的节点放入的是链表的头部。
删
clear 函数
clear函数,clear函数除了要删除头尾节点让整个链表销毁之外更需要删除中间节点的相关属性,避免内存泄漏。
public void clear() {// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
remove 系列
remove 系列函数,这里直接看一下方法调用链上的核心remove(Object o)方法和方法调用链上的『孤儿』removeLastOccurence(Object o)方法
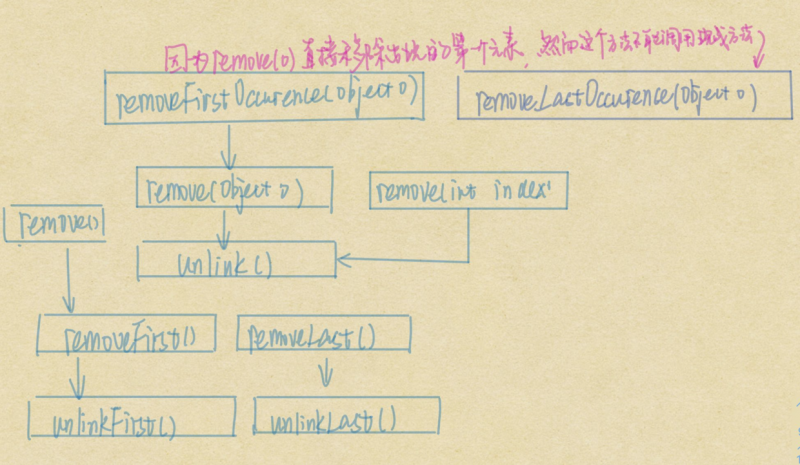
//实际上是删除第一个碰到的元素public boolean remove(Object o) {
//LinkedList可以放入空元素
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
returntrue;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
returntrue;
}
}
}
returnfalse;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//是不是第一个元素
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//是不是最后一个元素
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
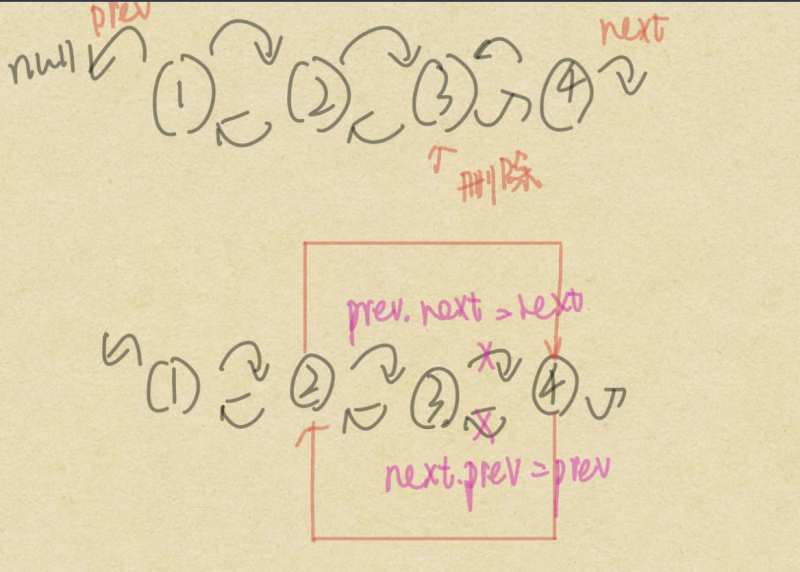
//模仿remove(Object o )过程倒序遍历删除public boolean removeLastOccurrence(Object o) {
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
if (x.item == null) {
unlink(x);
returntrue;
}
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
if (o.equals(x.item)) {
unlink(x);
returntrue;
}
}
}
returnfalse;
}
poll系列
除了List自带的remove 等等函数,LinkedList还有pollq系列函数:
public E poll() {final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E pollFirst() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
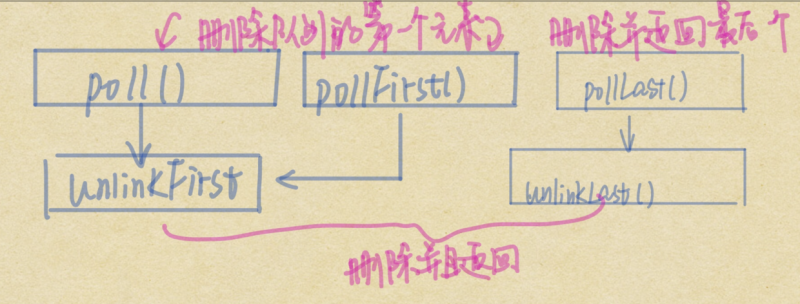
果不其然poll和pollFirst的代码是相同的,因为都是删除队列头节点。pollLast就是使用了unlinkLast而已,这里不列举了。
pop 函数
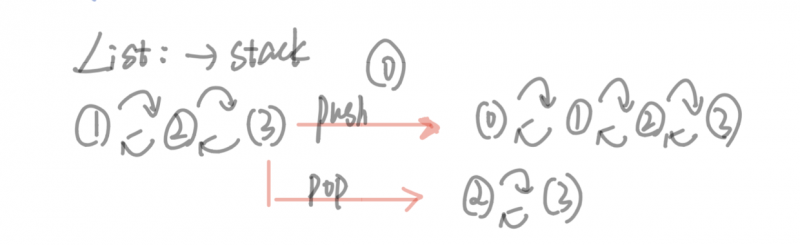
pop函数。毕竟LinkedList实现了Deque(双端队列),而不是什么双端栈的操作,所以增加元素和删除元素的操作只在一侧进行。
public E pop() {return removeFirst();
}
前面说过当使用LinkedList实现栈的时候是将链表的头当做栈顶,这里removeFirst很显然是这样。这些删除函数中poll系列和pop函数会返回节点,而remove系列函数中有些返回了节点,有些是boolean,具体得看文档。
遍历
peek相关函数
peek相关函数有peekFirst ,peekLast,因为peekFirst和peek代码相同,而且peekFirst和peekLast代码逻辑相同,这里就以peek函数为例:
public E peek() {final Node<E> f = first;
//返回第一个节点的内容
return (f == null) ? null : f.item;
}
- 迭代器
谈到线性数据结构的遍历当然要看一下链表中的迭代器的结构
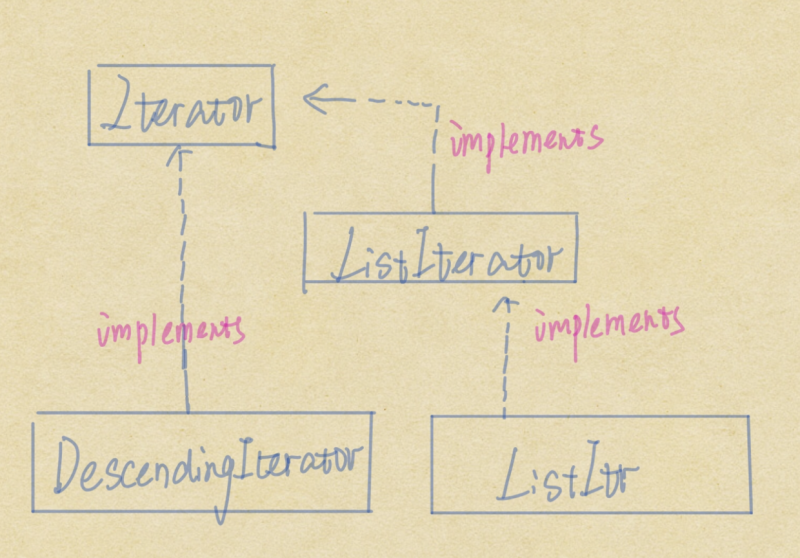
Iterator接口自不必说,ListIterator接口除了继承了Iterator接口的遍历功能之外,他的显著特点是可以从表结构的任意一个方向进行遍历。
由于DescendingIterator中保留了一个ListItr的实例,我们先看看ListItr:
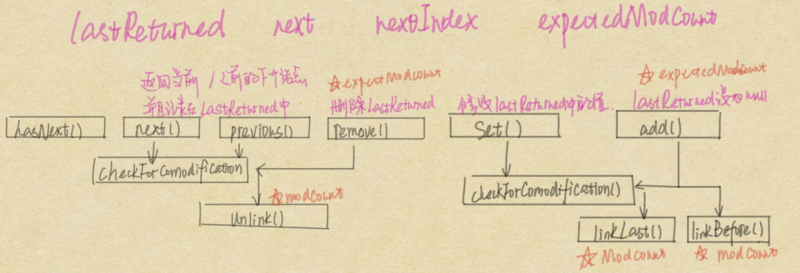
ListIterator的代码本身并不复杂,而且全部列举出来意义不大 而且比较占篇幅,这里通过方法之间的调用情况来简单说明与一下。
ListIterator中的lastReturned变量主要用于说明最近一次变化的结果,举个例子:
public E next() {checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
next操作就是取出链表中的下一个节点的位置,这里就回标记lastReturned。同时previousremove 这些操作都是基于lastReturned的。
可以看到ListIterator中凡是和结构性变化(structural modification)有关的操作都通过expectedModCount和modCount的值保持一致。
DescendingIterator
DescendingIterator就是对于ListItr的一个封装,以便反向遍历链表,代码就这么多:
private class DescendingIterator implements Iterator<E> {private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
LinkedList 中是否也会出现CME异常?
ArrayList<Integer> arrayList = new ArrayList<>();arrayList.add(1); arrayList.add(2);arrayList.add(3);
arrayList.add(4); arrayList.add(5);arrayList.add(6);
for (Integer i : arrayList) {
//java.util.ConcurrentModificationException
if(i ==6) arrayList.remove(i);
}
LinkedList<Integer> linkedList = new LinkedList<>();
linkedList.add(1); linkedList.add(2);linkedList.add(3);
linkedList.add(4); linkedList.add(5);linkedList.add(6);
for (Integer i : linkedList) {
//没有异常
if(i ==6) linkedList.remove(i);
}
按照上一篇文章的内容中可以得出 第一段代码会出现CME,第二段代码只将ArrayList改成为LinkedList,不会出现异常的愿意是JDK有意为之吗?
当然不是,下面通过了一个图示分析这个过程:
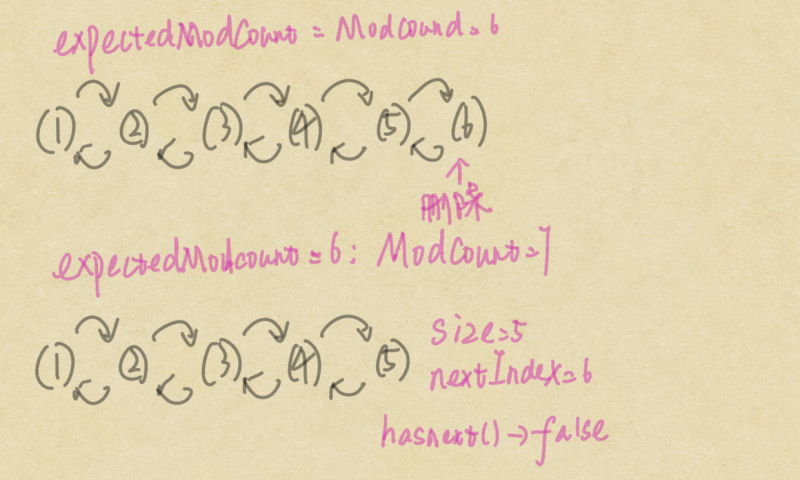
//remove()方法通过unlink()改变modCountpublic boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
returntrue;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
returntrue;
}
}
}
returnfalse;
}
// Java中的foreach语句其实就是一个迭代器的语法糖,使用迭代器时会调用next方法 同时通过 hasNext()检测是否结束
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
//LinkedList中的hasNext
public boolean hasNext() {
return nextIndex < size;
}
//ArrayList中的hasNext
public boolean hasNext() {
return cursor != size;
}
通过分析删除过程可以发现虽然删除了之后,LinkedList持有的modCount 和缓存在ListIterator中的expectedModCount不相等,但是hasNext 会返回false(size 为5 nextIndex为6),如果是ArrayList中的hasNext,这个时候size= 5 cursor = 6,依然返回true,所以不可避免的进入下一轮迭代,并且checkForComodification()出现CME。
当然在LinkedList中不会出现CME的原因是被删除的元素在链表的结尾,checkForComodification函数没有被执行,如果是这样的代码:
LinkedList<Integer> linkedList = new LinkedList<>();linkedList.add(1); linkedList.add(2);linkedList.add(3);
linkedList.add(4); linkedList.add(5);linkedList.add(6);
linkedList.add(7); linkedList.add(8);linkedList.add(9);
for (Integer i : linkedList) {
//error
if(i ==6) linkedList.remove(i);
}
还是会出现异常。
参考资料:
Iterator 和 ListIterator的区别
LinkedList 和 ArrayList 对比问题
JDK9修复的bug(JDK-6260652)是怎么回事
以上是 简明数据结构源码阅读(二)-- LinkedList 的全部内容, 来源链接: utcz.com/a/29881.html