Node.js与二进制数据流
认识二进制数据

二进制数据就像上图一样,由0和1来存储数据。普通的十进制数转化成二进制数一般采用"除2取余,逆序排列"法,用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。例如,数字10转成二进制就是1010,那么数字10在计算机中就以1010的形式存储。
而字母和一些符号则需要通过 ASCII 码来对应,例如,字母a对应的 ACSII 码是 97,二进制表示就是0110 0001。JavaScript 中可以使用 charCodeAt 方法获取字符对应的 ASCII:

除了ASCII外,还有一些其他的编码方式来映射不同字符,比如我们使用的汉字,通过 JavaScript 的 charCodeAt 方法得到的是其 UTF-16 的编码。

Node 处理二进制数据
JavaScript 在诞生初期主要用于表单信息的处理,所以 JavaScript 天生擅长对字符串进行处理,可以看到 String 的原型提供特别多便利的字符串操作方式。

但是,在服务端如果只能操作字符是远远不够的,特别是网络和文件的一些 IO 操作上,还需要支持二进制数据流的操作,而 Node.js 的 Buffer 就是为了支持这些而存在的。好在 ES6 发布后,引入了类型数组(TypedArray)的概念,又逐步补充了二进制数据处理的能力,现在在 Node.js 中也可以直接使用,但是在 Node.js 中,还是 Buffer 更加适合二进制数据的处理,而且拥有更优的性能,当然 Buffer 也可以直接看做 TypedArray 中的 Uint8Array。除了 Buffer,Node.js 中还提供了 stream 接口,主要用于处理大文件的 IO 操作,相对于将文件分批分片进行处理。
认识 Buffer
Buffer 直译成中文是『缓冲区』的意思,顾名思义,在 Node.js 中实例化的 Buffer 也是专门用来存放二进制数据的缓冲区。一个 Buffer 可以理解成开辟的一块内存区域,Buffer 的大小就是开辟的内存区域的大小。下面来看看Buffer 的基本使用方法。
API 简介
早期的 Buffer 通过构造函数进行创建,通过不同的参数分配不同的 Buffer。
new Buffer(size)
创建大小为 size(number) 的 Buffer。
new Buffer(5)// <Buffer 00 00 00 00 00>
new Buffer(array)
使用八位字节数组 array 分配一个新的 Buffer。
const buf = new Buffer([0x74, 0x65, 0x73, 0x74])// <Buffer 74 65 73 74>
// 对应 ASCII 码,这几个16进制数分别对应 t e s t
// 将 Buffer 实例转为字符串得到如下结果
buf.toString() // 'test'
new Buffer(buffer)
拷贝 buffer 的数据到新建的 Buffer 实例。
const buf1 = new Buffer('test')const buf2 = new Buffer(buf1)
new Buffer(string[, encoding])
创建内容为 string 的 Buffer,指定编码方式为 encoding。
const buf = new Buffer('test')// <Buffer 74 65 73 74>
// 可以看到结果与 new Buffer([0x74, 0x65, 0x73, 0x74]) 一致
buf.toString() // 'test'
更安全的 Buffer
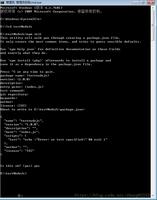
由于 Buffer 实例因第一个参数类型而执行不同的结果,如果开发者不对参数进行校验,很容易导致一些安全问题。例如,我要创建一个内容为字符串 "20" 的 Buffer,而错误的传入了数字 20,结果创建了一个长度为 20 的Buffer 实例。

可以看到上图,Node.js 8 之前,为了高性能的考虑,Buffer 开辟的内存空间并未释放之前已存在的数据,直接将这个 Buffer 返回可能导致敏感信息的泄露。因此,Buffer 类在 Node.js 8 前后有一次大调整,不再推荐使用 Buffer 构造函数实例 Buffer,而是改用Buffer.from()、Buffer.alloc() 与 Buffer.allocUnsafe() 来替代 new Buffer()。
Buffer.from()
该方法用于替代 new Buffer(string)、new Buffer(array)、new Buffer(buffer)。
Buffer.alloc(size[, fill[, encoding]])
该方法用于替代 new Buffer(size),其创建的 Buffer 实例默认会使用 0 填充内存,也就是会将内存之前的数据全部覆盖掉,比之前的 new Buffer(size) 更加安全,因为要覆盖之前的内存空间,也意味着更低的性能。
同时,size 参数如果不是一个数字,会抛出 TypeError。

Buffer.allocUnsafe(size)
该方法与之前的 new Buffer(size) 保持一致,虽然该方法不安全,但是相比起 alloc 具有明显的性能优势。

Buffer 的编码
前面介绍过二进制数据与字符对应需要指定编码,同理将字符串转化为 Buffer、Buffer 转化为字符串都是需要指定编码的。
Node.js 目前支持的编码方式如下:
hex:将每个字节编码成两个十六进制的字符。ascii:仅适用于 7 位 ASCII 数据。此编码速度很快,如果设置则会剥离高位。utf8:多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8。utf16le:2 或 4 个字节,小端序编码的 Unicode 字符。ucs2:utf16le的别名。base64:Base64 编码。latin1:一种将Buffer编码成单字节编码字符串的方法。binary:latin1的别名。
比较常用的就是 UTF-8、UTF-16、ASCII,前面说过 JavaScript 的 charCodeAt 使用的是 UTF-16 编码方式,或者说 JavaScript 中的字符串都是通过 UTF-16 存储的,不过 Buffer 默认的编码是 UTF-8。

可以看到一个汉字在 UTF-8 下需要占用 3 个字节,而 UTF-16 只需要 2 个字节。主要原因是 UTF-8 是一种可变长的字符编码,大部分字符使用 1 个字节表示更加节省空间,而某些超出一个字节的字符,则需要用到 2 个或 3 个字节表示,大部分汉字在 UTF-8 中都需要用到 3 个字节来表示。UTF-16 则全部使用 2 个字节来表示,对于一下超出了 2 字节的字符,需要用到 4 个字节表示。 2 个字节表示的 UTF-16 编码与 Unicode 完全一致,通过汉字Unicode编码表可以找到大部分中文所对应的 Unicode 编码。前面提到的 『汉』,通过 Unicode 表示为 6C49。

这里提到的 Unicode 编码又被称为统一码、万国码、单一码,它为每种语言都设定了统一且唯一的二进制编码,而上面说的 UTF-8、UTF-16 都是他的一种实现方式。更多关于编码的细节不再赘述,也不是本文的重点,如果想了解更多可自行搜索。
乱码的原因
我们经常会出现一些乱码的情况,就是因为在字符串与 Buffer 的转化过程中,使用了不同编码导致的。
我们先新建一个文本文件,然后通过 utf16 编码保存,然后通过 Node.js 读取改文件。

const fs = require('fs')const buffer = fs.readFileSync('./1.txt')
console.log(buffer.toString())

由于 Buffer 在调用 toString 方法时,默认使用的是 utf8 编码,所以输出了乱码,这里我们将 toString 的编码方式改成 utf16 就可以正常输出了。
const fs = require('fs')const buffer = fs.readFileSync('./1.txt')
console.log(buffer.toString('utf16le'))

认识 Stream
前面我们说过,在 Node.js 中可以利用 Buffer 来存放一段二进制数据,但是如果这个数据量非常的大使用 Buffer 就会消耗相当大的内存,这个时候就需要用到 Node.js 中的 Stream(流)。要理解流,就必须知道管道的概念。
我们经常在 Linux 命令行使用管道,将一个命令的结果传输给另一个命令,例如,用来搜索文件。
ls | grep code这里使用 ls 列出当前目录的文件,然后交由 grep 查找包含 code 关键词的文件。
在前端的构建工具 gulp 中也用到了管道的概念,因为使用了管道的方式来进行构建,大大简化了工作流,用户量一下子就超越了 grunt。
// 使用 gulp 编译 scssconst gulp = require('gulp')
const sass = require('gulp-sass')
const csso = require('gulp-csso')
gulp.task('sass', function () {
return gulp.src('./**/*.scss')
.pipe(sass()) // scss 转 css
.pipe(csso()) // 压缩 css
.pipe(gulp.dest('./css'))
})
前面说了这么多管道,那管道和流直接应该怎么联系呢。流可以理解为水流,水要流向哪里,就是由管道来决定的,如果没有管道,水也就不能形成水流了,所以流必须要依附管道。在 Node.js 中所有的 IO 操作都可以通过流来完成,因为 IO 操作的本质就是从一个地方流向另一个地方。例如,一次网络请求,就是将服务端的数据流向客户端。
const fs = require('fs')const http = require('http')
const server = http.createServer((request, response) => {
// 创建数据流
const stream = fs.createReadStream('./data.json')
// 将数据流通过管道传输给响应流
stream.pipe(response)
})
server.listen(8100)
// data.json{ "name": "data" }

使用 Stream 会一边读取 data.json 一边将数据写入响应流,而不是像 Buffer 一样,先将整个 data.json 读取到内存,然后一次性输出到响应中,所以使用 Stream 的时候会更加节约内存。
其实 Stream 在内部依然是运作在 Buffer 上。如果我们把一段二进制数据比做一桶水,那么通过 Buffer 进行文件传输就是直接将一桶水倒入到另一个桶里面,而使用 Stream,就是将桶里面的水通过管道一点点的抽取过去。
Stream 与 Buffer 内存消耗对比
这里如果只是口头说说可能感知不明显,现在分别通过 Stream 和 Buffer 来复制一个 2G 大小的文件,看看 node 进程的内存消耗。
Stream 复制文件
// Stream 复制文件const fs = require('fs');
const file = './file.mp4';
fs.createReadStream(file)
.pipe(fs.createWriteStream('./file.copy.mp4'))
.on('finish', () => {
console.log('file successfully copy');
})

Buffer 复制文件
// Buffer 复制文件const fs = require('fs');
const file = './file.mp4';
// fs.readFile 直接输出的是文件 Buffer
fs.readFile(file, (err, buffer) => {
fs.writeFile('./file.copy.mp4', buffer, (err) => {
console.log('file successfully copy');
});
});

通过上图的结果可以看出,通过 Stream 拷贝时,只占用了我电脑 0.6% 的内存,而使用 Buffer 时,占用了 15.3% 的内存。
API 简介
在 Node.js 中,Steam 一共被分为五种类型。
- 可读流(Readable),可读取数据的流;
- 可写流(Writable),可写入数据的流;
- 双工流(Duplex),可读又可写的流;
- 转化流(Transform),在读写过程中可任意修改和转换数据的流(也是可读写的流);
所有的流都可以通过 .pipe 也就是管道(类似于 linux 中的 |)来进行数据的消费。另外,也可以通过事件来监听数据的流动。不管是文件的读写,还是 http 的请求、响应都会在内部自动创建 Stream,读取文件时,会创建一个可读流,输出文件时,会创建可写流。
可读流(Readable)
虽然叫做可读流,但是可读流也是可写的,只是这个写操作一般是在内部进行的,外部只需要读取就行了。
可读流一般分为两种模式:
- 流动模式:表示正在读取数据,一般通过事件监听来获取流中的数据。
- 暂停模式:此时流中的数据不会被消耗,如果在暂停模式需要读取可读流的数据,需要显式调用
stram.read()。
可读流在创建时,默认为暂停模式,一旦调用了 .pipe,或者监听了 data 事件,就会自动切换到流动模式。
const { Readable } = require('stream')// 创建可读流
const readable = new Readable()
// 绑定 data 事件,将模式变为流动模式
readable.on('data', chunk => {
console.log('chunk:', chunk.toString()) // 输出 chunk
})
// 写入 5 个字母
for (let i = 97; i < 102; i++) {
const str = String.fromCharCode(i);
readable.push(str)
}
// 推入 `null` 表示流已经结束
readable.push(null)

const { Readable } = require('stream')// 创建可读流
const readable = new Readable()
// 写入 5 个字母
for (let i = 97; i < 102; i++) {
const str = String.fromCharCode(i);
readable.push(str)
}
// 推入 `null` 表示流已经结束
readable.push('n')
readable.push(null)
// 通过管道将流的数据输出到控制台
readable.pipe(process.stdout)

上面的代码都是手动创建可读流,然后通过 push 方法往流里面写数据的。前面说过,Node.js 中数据的写入都是内部实现的,下面通过读取文件的 fs 创建的可读流来举例:
const fs = require('fs')// 创建 data.json 文件的可读流
const read = fs.createReadStream('./data.json')
// 监听 data 事件,此时变成流动模式
read.on('data', json => {
console.log('json:', json.toString())
})

#### 可写流(Writable)
可写流对比起可读流,它是真的只能写,属于只进不出的类型,类似于貔貅。
创建可写流的时候,必须手动实现一个 _write() 方法,因为前面有下划线前缀表明这是内部方法,一般不由用户直接实现,所以该方法都是在 Node.js 内部定义,例如,文件可写流会在该方法中将传入的 Buffer 写入到指定文本中。
写入如果结束,一般需要调用可写流的 .end() 方法,表示结束本次写入,此时还会调用 finish 事件。
const { Writable } = require('stream')// 创建可写流
const writable = new Writable()
// 绑定 _write 方法,在控制台输出写入的数据
writable._write = function (chunk) {
console.log(chunk.toString())
}
// 写入数据
writable.write('abc')
// 结束写入
writable.end()
_write 方法也可以在实例可写流的时候,通过传入对象的 write 属性来实现。
const { Writable } = require('stream')// 创建可写流
const writable = new Writable({
// 同,绑定 _write 方法
write(chunk) {
console.log(chunk.toString())
}
})
// 写入数据
writable.write('abc')
// 结束写入
writable.end()

下面看看 Node.js 中内部通过 fs 创建的可写流。
const fs = require('fs')// 创建可写流
const writable = fs.createWriteStream('./data.json')
// 写入数据,与自己手动创建的可写流一致
writable.write(`{
"name": "data"
}`)
// 结束写入
writable.end()
看到这里就能理解,Node.js 在 http 响应时,需要调用 .end() 方法来结束响应,其实内部就是一个可写流。现在再回看前面通过 Stream 来复制文件的代码就更加容易理解了。
const fs = require('fs');const file = './file.mp4';
fs.createReadStream(file)
.pipe(fs.createWriteStream('./file.copy.mp4'))
.on('finish', () => {
console.log('file successfully copy');
})
双工流(Duplex)
双工流同时实现了 Readable 和 Writable,具体用法可以参照可读流和可写流,这里就不占用文章篇幅了。
管道串联
前面介绍了通过管道(.pipe())可以将一个桶里的数据转移到另一个桶里,但是有多个桶的时候,我们就需要多次调用 .pipe()。例如,我们有一个文件,需要经过 gzip 压缩后重新输出。
const fs = require('fs')const zlib = require('zlib')
const gzip = zlib.createGzip() // gzip 为一个双工流,可读可写
const input = fs.createReadStream('./data.json')
const output = fs.createWriteStream('./data.json.gz')
input.pipe(gzip) // 文件压缩
gzip.pipe(output) // 压缩后输出
面对这种情况,Node.js 提供了 pipeline() api,可以一次性完成多个管道操作,而且还支持错误处理。
const { pipeline } = require('stream')const fs = require('fs')
const zlib = require('zlib')
const gzip = zlib.createGzip()
const input = fs.createReadStream('./data.json')
const output = fs.createWriteStream('./data.json.gz')
pipeline(
input, // 输入
gzip, // 压缩
output, // 输出
// 最后一个参数为回调函数,用于错误捕获
(err) => {
if (err) {
console.error('压缩失败', err)
} else {
console.log('压缩成功')
}
}
)
参考
- 字符编码笔记
- Buffer | Node.js API
- stream | Node.js API
- stream-handbook
以上是 Node.js与二进制数据流 的全部内容, 来源链接: utcz.com/a/28732.html