Flink的窗口、时间语义,Watermark机制,多代码案例详解,Flink学习入门(三)
❝
大家好,我是后来,我会分享我在学习和工作中遇到的点滴,希望有机会我的某篇文章能够对你有所帮助,所有的文章都会在公众号首发,欢迎大家关注我的公众号" 「后来X大数据」 ",感谢你的支持与认可。
❞
@目录
- 滚动窗口
- 滑动窗口
- 会话窗口
- 总结窗口的知识点:
那么水位线怎么生成呢?
- 周期性水位线
- 标记性水位线
- 关于并行度与水位线
- 扫码关注公众号“后来X大数据”,回复【电子书】,领取超多本pdf 【java及大数据 电子书】
通过前2篇flink的学习,已经基本掌握了flink的基本使用,但是关于flink真正内核的东西还没开始说,那先简单介绍一下,flink的核心亮点:
窗口 时间语义 精准一次性
我们在第一篇的学习了解到了flink的wordCount,以及在第二篇的API 中,我们也只是获取到数据,进行简单的转换,就直接把数据输出。
但是我们在之前都是以事件为驱动,等于说是来了一条数据,我就处理一次,但是现在遇到的问题是:
我们可以简单的把wordCount的需求比做公司的订单金额,也就是订单金额会随着订单的增加而只增不减,那么如果运营部门提了以下需求:
每有1000条订单就输出一次这1000条订单的总金额 每5分钟输出一次刚刚过去这5分钟的订单总金额 每3秒输出一次最近5分钟内的累计成交额 连续2条订单的间隔时间超过30秒就按照这个时间分为2组订单,输出前一组订单的总金额
那么面对这个需求,因为时间一直是流动的,大家有什么想法?
基于这些需求,我们来讲一下flink的窗口。
窗口
窗口:无论是hive中的开窗函数,还是Spark中的批次计算中的窗口,还是我们这里讲的窗口,「本质上都是对数据进行划分,然后对划分后的数据进行计算。」
那么Windows是处理无限流的核心。Windows将流分成有限大小的“存储桶”,我们可以在其上应用计算。
在flink中,窗口式Flink程序一般有2类,
键控流
stream .keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (elsedefault trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
非键控流
stream .windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (elsedefault trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
「唯一的区别是:对键控流的keyBy(…)调用window(…),而非键控流则是调用windowAll(…)。」
窗口的生命周期
我们上面说窗口就是对数据进行划分到不同的“桶”中,然后进行计算,那么什么开始有这个桶,什么时候就算是分完了呢?
简而言之,一旦应属于该窗口的第一个元素到达,就会创建一个窗口,当时间超过用户设置的时间戳时,flink将删除这个窗口。
那我们来理解一下窗口的类型:
CountWindow:按照指定的数据条数生成一个Window,与时间无关。 TimeWindow:按照时间生成Window。 1. 滚动窗口
2. 滑动窗口
3. 会话窗口
从文字也不难看出,CountWindow就是按照数据条数生成窗口,样例代码如下:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala._
object CountWindowsTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val wordDS = env.socketTextStream("master102",3456)
wordDS
.map((_,1))
.keyBy(0)
//累计单个Key中3条数据就进行处理
.countWindow(3)
.sum(1)
.print("测试:")
env.execute()
}
}
执行结果如下:
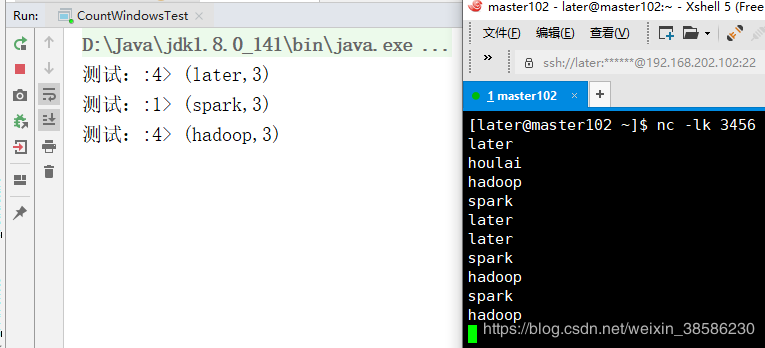
可以看出,不同的单词根据keyby进入不同的窗口,然后当窗口中的单个key的数据个数达到3个之后进行输出。
接下来,我们主要来说一下时间窗口,「这些窗口的结束与开始都是根据数据的时间来判断的」,所以这里就引出了我们今天的第二个重点:时间语义
时间语义
Flink 在流式传输程序中支持不同的时间概念:
Event Time:「事件时间是每个事件在其生产设备上发生的时间」。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。 Ingestion Time:「摄取时间是数据进入Flink的时间」。摄取时间从概念上讲介于事件时间和处理时间之间。 Processing Time:「处理时间是是指正在执行相应算子操作的机器的系统时间,默认的时间属性就是Processing Time。」 处理时间是最简单的时间概念,不能提供确定性,因为它容易依赖数据到达系统(例如从消息队列)到达系统的速度,以及数据在系统内部之间流动的速度。
我们根据业务的需求还判断使用哪个时间类型,一般来说使用Event Time更多,比如:在统计最近5分钟的订单总金额时,我们需要的是真实的订单时间,而不是进入flink的时间或者是处理时间。
「在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。默认情况下,Flink框架中处理的时间语义为ProcessingTime,如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:」
import org.apache.flink.streaming.api.TimeCharacteristic
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
「这里注意:如果要使用事件时间,那么必须要为数据定义事件时间,并且还要注册水位线」
好了,又是一个新的知识点:水位线
我们暂时先有这些概念,然后我们再返回来继续说我们的窗口的类型。说完窗口类型,再详细说水位线的应用。
所以这也为后面的数据乱序埋下了坑,比如,2条订单,它们的订单时间差不多,一前一后,但是因为先下单的这条订单的网络情况不好,导致后到达flink窗口,也就是我们常说的数据乱序,那么这种情况该怎么办?我们后面再说这个问题
「特别注意:窗口是左闭右开的。」
滚动窗口
滚动窗口具有固定的尺寸和不重叠,例如,如果指定大小为5分钟的滚动窗口,则每五分钟将启动一个新窗口,如下图所示。
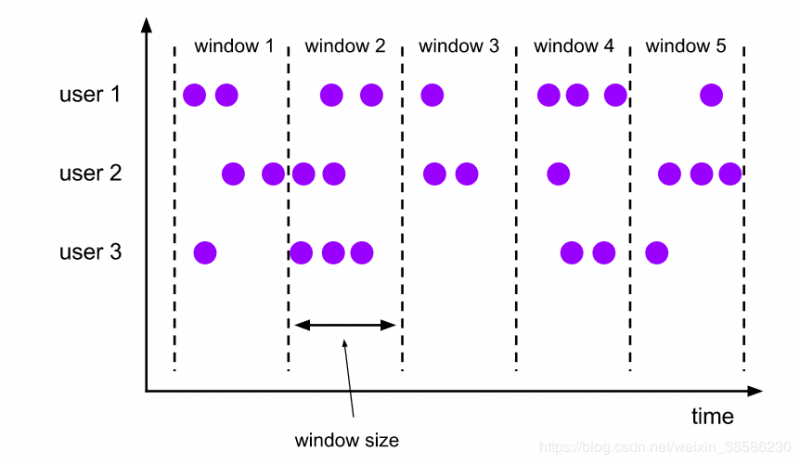
样例代码如下:
import java.text.SimpleDateFormat
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* @description: ${description}
* @author: Liu Jun Jun
* @create: 2020-06-29 13:59
**/
object WindowTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val dataDS = env.socketTextStream("bigdata101", 3456)
val tsDS = dataDS.map(str => {
val strings = str.split(",")
(strings(0), strings(1).toLong, 1)
}).keyBy(0)
//窗口大小为5s的滚动窗口
//.timeWindow(Time.seconds(5))和下面的这种写法都是可以的
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply {
(tuple: Tuple, window: TimeWindow, es: Iterable[(String, Long, Int)], out: Collector[String]) => {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//out.collect(s"window:[${sdf.format(new Date(window.getStart))}-${sdf.format(new Date(window.getEnd))}]:{ ${es.mkString(",")} }")
out.collect(s"window:[${window.getStart}-${window.getEnd}]:{ ${es.mkString(",")} }")
}
}.print("windows:>>>")
env.execute()
}
}
通过运行,大概会发现,我们输入的时间戳并不会起作用,默认使用的确实是处理时间:

同时,可以看出,滚动窗口的时间窗口不会有重叠,一条数据只会属于一个窗口,而且,窗口是左闭右开的。
滑动窗口
滑动窗口也是固定长度的窗口,不过由于滑动的频率,当滑动频率小于窗口大小时,「滑动窗口会重叠,在这种情况下,一个元素被分配到多个窗口。」
例如:指定大小为10分钟的窗口滑动5分钟。这样,您每隔5分钟就会得到一个窗口,其中包含最近10分钟内到达的事件,如下图所示。
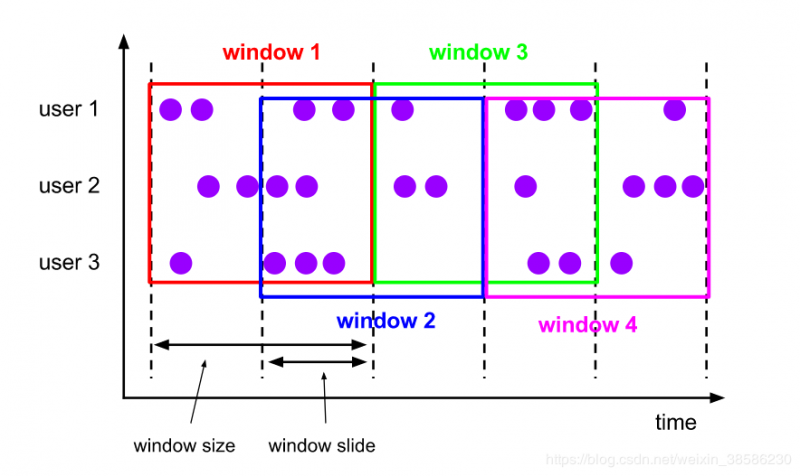
接下来,我只贴改动代码,其余代码和上面的滚动代码是一样的:
//滚动5秒,滑动3秒//.window(SlidingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(3)))和下面的这句话是一样的
.timeWindow(Time.seconds(5),Time.seconds(3))
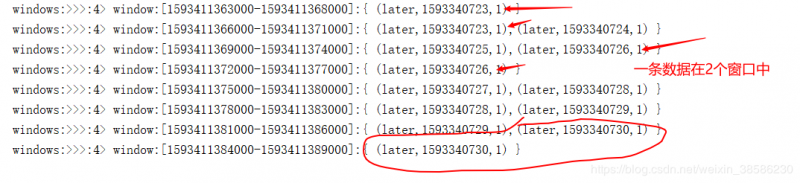
非常关键的是:大家发现,flink默认的分配窗口是从每秒从0开始数的,举例:会把5秒的窗口分为:
[0-5),[5,10),[10-15),....
3秒的窗口为:
[0-3),[3,6),[6-9),....
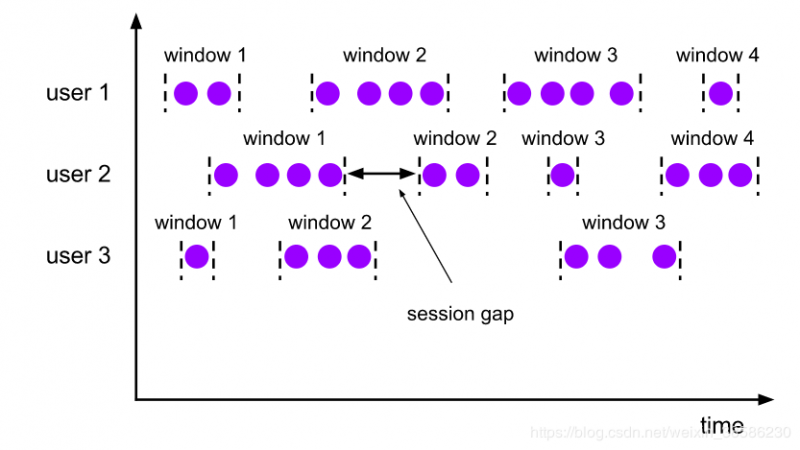
会话窗口
与滚动窗口和滑动窗口相比,「会话窗口不重叠且没有固定的开始和结束时间」。相反,会话窗口在一定时间段内未收到元素时(即,出现不活动间隙时)关闭。随后的元素将分配给新的会话窗口。
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
可以看出,这次的窗口大小并不是固定的,那么我在测试输入的时候,输完一些后等了一会儿才继续输入的,那么就出现了第一个窗口,所以只要processtime间隔时间超过10s,就会输出上一个窗口。
总结窗口的知识点:
以上所有的窗口的时间都可以更改为EventTime,同时时间间隔可以指定为Time.milliseconds(x),Time.seconds(x),Time.minutes(x) 如果使用timewindow()方法,那么会随着事件时间的指定会更改为以事件时间为标准的窗口,而如果使用window()方法,那么其中的参数会发生变化。
//滚动窗口//事件时间
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//处理时间
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
//滑动窗口
//事件时间
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//处理时间
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
//会话窗口
//事件时间
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
//处理时间
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
flink默认的分配窗口是从每秒从0开始数的,举例:会把5秒的窗口分为: [0-5),[5,10),[10-15),....
3秒的窗口为:
[0-3),[3,6),[6-9),....
那么可不可以做到窗口的划分为[1-6),[6,11)...
当然可以,flink有窗口偏移设置。一般用不到,我在这里简单贴一下使用方式:
//5秒的窗口偏移3秒 .window(TumblingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(3)))

能从上图看出,窗口从原来的80-85,偏移到了83-88。那我再把方法总结一下
//窗口偏移方法总结//滚动窗口
//事件时间
.window(TumblingEventTimeWindows.of(Time.seconds(5),Time.seconds(3)))
//处理时间
.window(TumblingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(3)))
//滑动窗口
//事件时间
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5),Time.seconds(3)))
//处理时间
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5),Time.seconds(3)))
//会话窗口
//事件时间
.window(EventTimeSessionWindows.withGap(Time.minutes(10),Time.seconds(3)))
//处理时间
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10),Time.seconds(3)))
关于窗口的使用基本上差不多了,接下来只要说一说水位线
水位线WaterMark
WaterMark,叫做水位线,那它是干啥的?「支持事件时间的流处理器需要一种衡量事件时间进度的方法。」
这里要注意:使用事件时间必须要使用注册水位线,而水位线也是事件时间专用的
例如,当以事件时间开窗1小时,目前窗口刚超过一个小时,需要通知构建每小时窗口的窗口操作员,关闭正在进行中的这个窗口程序。
那问题来了,怎么衡量时间到了没?所以Flink中用于衡量事件时间进度的机制是水位线。
「强调:并不是每条数据都会生成水位线。水位线也是一条数据,是流数据的一部分,watermark是一个全局的值,不是某一个key下的值,所以即使不是同一个key的数据,其warmark也会增加。」
同时,水位线还有一个重要作用,就是处理延迟数据,我们在文章开头的部分也提到了,数据乱序怎么处理,那么有些数据因为网络的原因,延迟了几秒,所以也可以「把水位线看作是窗口最后的执行时间」。
比如说,我们规定滚动窗口为5秒,也就是[5-10),同时我们预测数据一般可能延迟3秒,所以我们希望窗口是当10s的数据到达后,继续等待3秒,看这3秒内,还是否有原本是[5-10)中的数据,一起归并到这个窗口中,等到出现了时间为大于等于13s的数据时,就会触发[5-10)这个窗口的数据执行。这就是延迟处理。(代码案例看下面的周期性水位线)
那么水位线怎么生成呢?
有两种分配时间戳和生成水位线的方法:
直接在数据流源中(我现在还不知道哪种数据源可以直接生成时间戳和水位线,所以这里不讨论了) 通过时间戳分配器/水位线生成器:在Flink中,时间戳分配器还定义要发送的水位线注意自1970-01-01T00:00:00Z的Java时代以来,时间戳和水位线都指定为毫秒。(大部分使用情况)
「Event Time的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用Processing Time了)。」
那我们就利用第二种方式来生成水位线吧,注意要在「事件时间的第一个操作」(例如第一个窗口操作)之前指定分配器,例如:
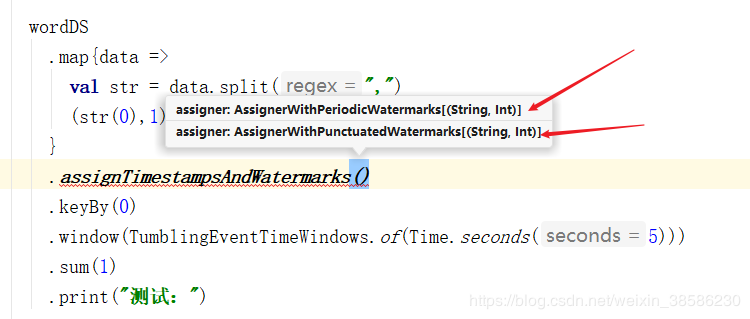
我们发现注册水位线的有2个接口可以实现:
AssignerWithPeriodicWatermarks(周期性生成水位线) AssignerWithPunctuatedWatermarks(标记性生成水位线)
一个一个说,先说周期性生成水位线:
周期性水位线
//flink默认200ms(毫秒)生成一条水位线,那我们也可以修改@PublicEvolving
publicvoidsetStreamTimeCharacteristic(TimeCharacteristic characteristic){
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
//单位是毫秒,所以我这里模拟设置的为10s
env.getConfig.setAutoWatermarkInterval(10000)
那么「这里的时间间隔指的是系统时间的10s,可不是事件时间的10s,这个不要弄混,不相信的话可以等会看我的测试案例。」
import java.text.SimpleDateFormatimport org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* @description: ${本案例模拟的是:以事件时间为标准,窗口滚动时间为5秒}
* @author: Liu Jun Jun
* @create: 2020-06-28 18:31
**/
object WaterMarkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置以事件时间为基准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//并行度设置为1。关于并行度的案例会在后面测试
env.setParallelism(1)
//设置10s生成一次水位线
env.getConfig.setAutoWatermarkInterval(10000)
val dataDS = env.socketTextStream("bigdata101", 3456)
val tsDS = dataDS.map(str => {
val strings = str.split(",")
(strings(0), strings(1).toLong, 1)
}).assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks[(String,Long,Int)]{
var maxTs :Long= 0
//得到水位线,周期性调用这个方法,得到水位线,我这里设置的也就是延迟5秒
override def getCurrentWatermark: Watermark = new Watermark(maxTs - 5000)
//负责抽取事件事件
override def extractTimestamp(element: (String, Long, Int), previousElementTimestamp: Long): Long = {
maxTs = maxTs.max(element._2 * 1000L)
element._2 * 1000L
}
}
/*new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.seconds(5)) {
override def extractTimestamp(element: (String, Long, Int)): Long = element._2 * 1000
}*/
)
val result = tsDS
.keyBy(0)
//窗口大小为5s的滚动窗口
.timeWindow(Time.seconds(5))
.apply {
(tuple: Tuple, window: TimeWindow, es: Iterable[(String, Long, Int)], out: Collector[String]) => {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//out.collect(s"window:[${sdf.format(new Date(window.getStart))}-${sdf.format(new Date(window.getEnd))}]:{ ${es.mkString(",")} }")
out.collect(s"window:[${window.getStart}-${window.getEnd}]:{ ${es.mkString(",")} }")
}
}
tsDS.print("water")
result.print("windows:>>>")
env.execute()
}
}

那么从结果可以看出:
【10- 15)的窗口是20这条数据触发的,在我输入20这条数据等了几秒后输出了第一个窗口
证实:10s的间隔时间为系统时间,同时水位线=当前时间戳 - 延迟时间 ,如果窗口的end time <= 水位线,则会触发这个窗口的执行
【15- 20)的窗口是25这条数据触发的,同样符合「窗口的end time <= 水位线」
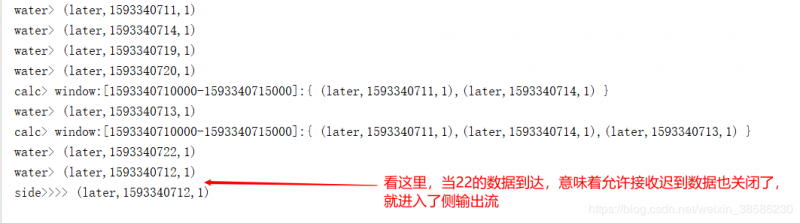
那么如果数据的窗口已经触发了,但还有一点数据还是迟到了怎么办?
所有还有个概念就是allowedLateness(允许接收延迟数据),并且还会继续把数据放入对应的窗口。看代码吧:
//其余代码和上面案例的一样,只是在开窗之后多了一行 .keyBy(0)
.timeWindow(Time.seconds(5))
//具体这2秒代表什么意思,看完测试结果案例就懂了
.allowedLateness(Time.seconds(2)
.apply{}

通过看图应该能明白这里allowedLateness(Time.seconds(2)是什么意思了,只要是窗口触发后,时间小于设定的延迟时间,收到的延迟数据都可以处理,但要是没有设置allowedLateness(Time.seconds(2)),那么窗口触发后的延迟数据都不会处理。
数据的延迟总是不可完全预测的,假如时间已经超过了允许接收的延迟数据时间,还有一点点数据迟到,就是上图中,在22这条数据之后我输入的14这条数据,那怎么办?这种情况下,我们不能为了偶尔的一点数据就把所有窗口的等待时间延迟很久,所有还有个概念就是「侧输出流」,将晚到的数据放置在侧输出流中。来看代码:
//只加了3行,其余的和之前的代码一样 val outputTag = new OutputTag[(String, Long, Int)]("lateData")//新加的
val result = tsDS
.keyBy(0)
.timeWindow(Time.seconds(5))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(outputTag)//新加的
.apply {}
result.getSideOutput(outputTag).print("side>>>")//新加的
标记性水位线
知识很多东西是想通的,所以开始讲延迟数据就巴拉巴拉一堆,再继续说间标记水位线,为什么叫做标记呢?因为这种水位线的生成与时间无关,而是决定于何时收到标记事件。
默认情况下,所有的数据都属于标记事件,意味着每条数据都会生成水位线。
所以使用这种方式的时候,需要对某些特定事件进行标记。
object WaterMarkTest {def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val dataDS = env.socketTextStream("bigdata101", 3456)
val tsDS = dataDS.map(str => {
val strings = str.split(",")
(strings(0), strings(1).toLong, 1)
}).assignTimestampsAndWatermarks(
new AssignerWithPunctuatedWatermarks[(String,Long,Int)] {
override def checkAndGetNextWatermark(lastElement: (String, Long, Int), extractedTimestamp: Long): Watermark = {
if (lastElement._1 .contains("later")){
println("间歇性生成了水位线.....")
// 间歇性生成水位线数据
new Watermark(extractedTimestamp)
}
returnnull
}
override def extractTimestamp(element: (String, Long, Int), previousElementTimestamp: Long): Long = {
element._2 * 1000L
}
}
)
val result = tsDS
.keyBy(0)
.timeWindow(Time.seconds(5))
.apply {
(tuple: Tuple, window: TimeWindow, es: Iterable[(String, Long, Int)], out: Collector[String]) => {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect(s"window:[${window.getStart}-${window.getEnd}]:{ ${es.mkString(",")} }")
}
}
tsDS.print("water")
result.print("calc")
env.execute()
}
}
看一下我的测试结果:

当然即便我们设置了标记,在TPS很高的场景下依然会产生大量的Watermark,在一定程度上对下游算子造成压力,「所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。」
关于并行度与水位线
细心的小伙伴也会发现,我在上面的所有的案例中,使用的并行度都是1,但实际生产中肯定不是1啊,这个会有什么变化么?当然是有的。
我先说结论:
「如果并行度不为1,那么在计算窗口时,是按照各自的并行度单独计算的。只有当所有并行度中都触发了同一个窗口,那么这个窗口才会触发。」
口说无凭,我们来看案例,这次放完整代码:
import java.text.SimpleDateFormatimport org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* @description: ${模拟多并行度下,窗口如何触发}
* @author: Liu Jun Jun
* @create: 2020-06-28 18:31
**/
object WaterMarkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//注掉了并行度为1,默认并行度=cpu核数,我这里cpu为4个
//env.setParallelism(1)
env.getConfig.setAutoWatermarkInterval(10000)
val dataDS = env.socketTextStream("bigdata101", 3456)
val tsDS = dataDS.map(str => {
val strings = str.split(",")
(strings(0), strings(1).toLong, 1)
}).assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks[(String,Long,Int)]{
var maxTs :Long= 0
override def getCurrentWatermark: Watermark = new Watermark(maxTs - 5000)
override def extractTimestamp(element: (String, Long, Int), previousElementTimestamp: Long): Long = {
maxTs = maxTs.max(element._2 * 1000L)
element._2 * 1000L
}
}
)
//该案例中,为了简单,去掉了allowedLateness和侧输出流
val result = tsDS
.keyBy(0)
.timeWindow(Time.seconds(5))
.apply {
(tuple: Tuple, window: TimeWindow, es: Iterable[(String, Long, Int)], out: Collector[String]) => {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//out.collect(s"window:[${sdf.format(new Date(window.getStart))}-${sdf.format(new Date(window.getEnd))}]:{ ${es.mkString(",")} }")
out.collect(s"window:[${window.getStart}-${window.getEnd}]:{ ${es.mkString(",")} }")
}
}
tsDS.print("water")
result.print("calc")
env.execute()
}
}
看一下测试结果吧:

好了,到这里,窗口、时间语义以及水位线的基本原理就说完了,理解了这些再看看文章开头提到了4个需求,是不是就有些想法了呢?
到目前为止,我们只是对数据进行了开窗,但是数据在一个窗口内怎么处理还没有说,那么下一章就来说处理函数,以及Flink的状态编程。
在这次学习中发现的不错的帖子:https://www.cnblogs.com/rossiXYZ/p/12286407.html
扫码关注公众号“后来X大数据”,回复【电子书】,领取超多本pdf 【java及大数据 电子书】

以上是 Flink的窗口、时间语义,Watermark机制,多代码案例详解,Flink学习入门(三) 的全部内容, 来源链接: utcz.com/a/28132.html