Redis中Scan命令的踩坑实录
1、原本以为自己对redis命令" title="redis命令">redis命令还蛮熟悉的,各种数据模型各种基于redis的骚操作。但是最近在使用redis的scan的命令式却踩了一个坑,顿时发觉自己原来对redis的游标理解的很有限。所以记录下这个踩坑的过程,背景如下:
公司因为redis服务器内存吃紧,需要删除一些无用的没有设置过期时间的key。大概有500多w的key。虽然key的数目听起来挺吓人。但是自己玩redis也有年头了,这种事还不是手到擒来?
当时想了下,具体方案是通过lua脚本来过滤出500w的key。然后进行删除动作。lua脚本在redis server上执行,执行速度快,执行一批只需要和redis server建立一次连接。筛选出来key,然后一次删1w。然后通过shell脚本循环个500次就能删完所有的。以前通过lua脚本做过类似批量更新的操作,3w一次也是秒级的。基本不会造成redis的阻塞。这样算起来,10分钟就能搞定500w的key。
然后,我就开始直接写lua脚本。首先是筛选。
用过redis的人,肯定知道redis是单线程作业的,肯定不能用keys命令来筛选,因为keys命令会一次性进行全盘搜索,会造成redis的阻塞,从而会影响正常业务的命令执行。
500w数据量的key,只能增量迭代来进行。redis提供了scan命令,就是用于增量迭代的。这个命令可以每次返回少量的元素,所以这个命令十分适合用来处理大的数据集的迭代,可以用于生产环境。

scan命令会返回一个数组,第一项为游标的位置,第二项是key的列表。如果游标到达了末尾,第一项会返回0。
2、所以我写的第一版的lua脚本如下:
local c = 0
local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000)
c = tonumber(resp[1])
local dataList = resp[2]
for i=1,#dataList do
local d = dataList[i]
local ttl = redis.call('TTL',d)
if ttl == -1 then
redis.call('DEL',d)
end
end
if c==0 then
return 'all finished'
else
return 'end'
end
在本地的测试redis环境中,通过执行以下命令mock了20w的测试数据:
eval "for i = 1, 200000 do redis.call('SET','authToken_' .. i,i) end" 0
然后执行script load命令上传lua脚本得到SHA值,然后执行evalsha去执行得到的SHA值来运行。具体过程如下:
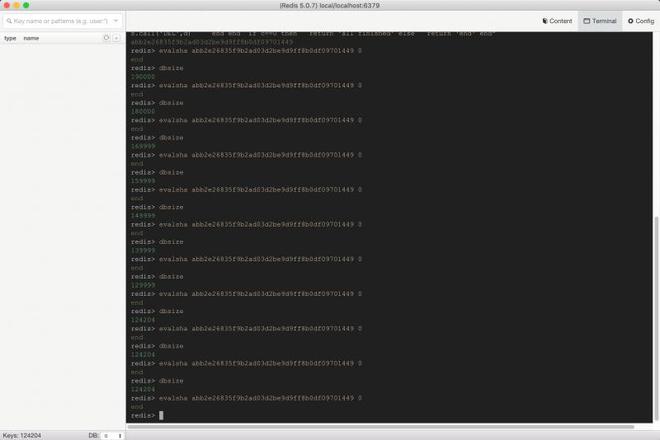
我每删1w数据,执行下dbsize(因为这是我本地的redis,里面只有mock的数据,dbsize也就等同于这个前缀key的数量了)。
奇怪的是,前面几行都是正常的。但是到了第三次的时候,dbsize变成了16999,多删了1个,我也没太在意,但是最后在dbsize还剩下124204个的时候,数量就不动了。之后无论再执行多少遍,数量还依旧是124204个。
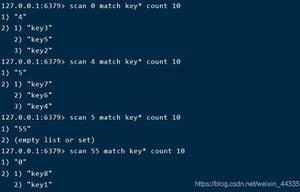
随即我直接运行scan命令:

发现游标虽然没有到达末尾,但是key的列表却是空的。
这个结果让我懵逼了一段时间。我仔细检查了lua脚本,没有问题啊。难道是redis的scan命令有bug?难道我理解的有问题?
我再去翻看redis的命令文档对count选项的解释:

经过详细研读,发现count选项所指定的返回数量还不是一定的,虽然知道可能是count的问题,但无奈文档的解释实在难以很通俗的理解,依旧不知道具体问题在哪
3、后来经过某个小伙伴的提示,看到了另外一篇对于scan命令count选项通俗的解释:

看完之后恍然大悟。原来count选项后面跟的数字并不是意味着每次返回的元素数量,而是scan命令每次遍历字典槽的数量
我scan执行的时候每一次都是从游标0的位置开始遍历,而并不是每一个字典槽里都存放着我所需要筛选的数据,这就造成了我最后的一个现象:虽然我count后面跟的是10000,但是实际redis从开头往下遍历了10000个字典槽后,发现没有数据槽存放着我所需要的数据。所以我最后的dbsize数量永远停留在了124204个。
所以在使用scan命令的时候,如果需要迭代的遍历,需要每次调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
至此,心中的疑惑就此解开,改了一版lua:
local c = tonumber(ARGV[1])
local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000)
c = tonumber(resp[1])
local dataList = resp[2]
for i=1,#dataList do
local d = dataList[i]
local ttl = redis.call('TTL',d)
if ttl == -1 then
redis.call('DEL',d)
end
end
return c
在本地上传后执行:
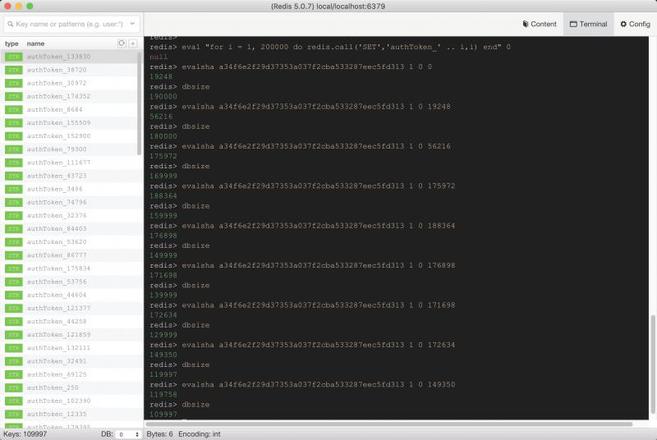
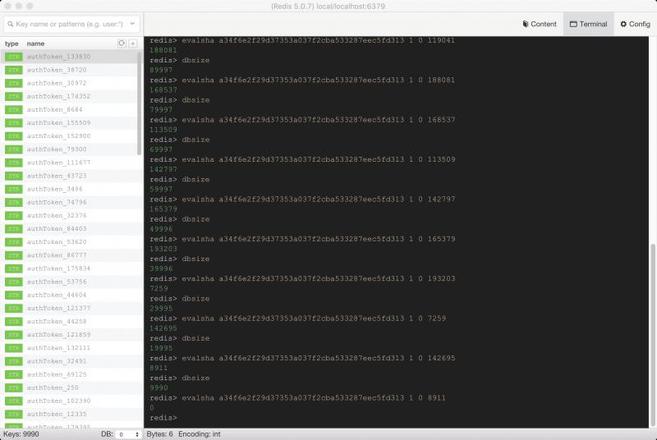
可以看到,scan命令没法完全保证每次筛选的数量完全等同于给定的count,但是整个迭代却很好的延续下去了。最后也得到了游标返回0,也就是到了末尾。至此,测试数据20w被全部删完。
这段lua只要在套上shell进行循环就可以直接在生产上跑了。经过估算大概在12分钟左右能删除掉500w的数据。
知其然,知其所以然。虽然scan命令以前也曾玩过。但是的确不知道其中的细节。况且文档的翻译也不是那么的准确,以至于自己在面对错误的结果时整整浪费了近1个多小时的时间。记录下来,加深理解。
总结
到此这篇关于Redis中Scan命令踩坑的文章就介绍到这了,更多相关Redis Scan命令踩坑内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Redis中Scan命令的踩坑实录 的全部内容, 来源链接: utcz.com/a/254362.html