Redis中scan命令的深入讲解
前言
熟悉Redis的人都知道,它是单线程的。因此在使用一些时间复杂度为O(N)的命令时要非常谨慎。可能一不小心就会阻塞进程,导致Redis出现卡顿。
有时,我们需要针对符合条件的一部分命令进行操作,比如删除以test_开头的key。那么怎么获取到这些key呢?在Redis2.8版本之前,我们可以使用keys命令按照正则匹配得到我们需要的key。但是这个命令有两个缺点:
- 没有limit,我们只能一次性获取所有符合条件的key,如果结果有上百万条,那么等待你的就是“无穷无尽”的字符串输出。
- keys命令是遍历算法,时间复杂度是O(N)。如我们刚才所说,这个命令非常容易导致Redis服务卡顿。因此,我们要尽量避免在生产环境使用该命令。
在满足需求和存在造成Redis卡顿之间究竟要如何选择呢?面对这个两难的抉择,Redis在2.8版本给我们提供了解决办法——scan命令。
相比于keys命令,scan命令有两个比较明显的优势:
- scan命令的时间复杂度虽然也是O(N),但它是分次进行的,不会阻塞线程。
- scan命令提供了limit参数,可以控制每次返回结果的最大条数。
这两个优势就帮助我们解决了上面的难题,不过scan命令也并不是完美的,它返回的结果有可能重复,因此需要客户端去重。至于为什么会重复,相信你看完本文之后就会有答案了。
关于scan命令的基本用法,可以参看Redis命令详解:Keys一文中关于SCAN命令的介绍。
SCAN 命令
SCAN命令的有SCAN,SSCAN,HSCAN,ZSCAN。
SCAN的话就是遍历所有的keys
其他的SCAN命令的话是SCAN选中的集合。
SCAN命令是增量的循环,每次调用只会返回一小部分的元素。所以不会有KEYS命令的坑。
SCAN命令返回的是一个游标,从0开始遍历,到0结束遍历。
今天我们主要从底层的结构和源码的角度来讨论scan是如何工作的。
Redis的结构
Redis使用了Hash表作为底层实现,原因不外乎高效且实现简单。说到Hash表,很多Java程序员第一反应就是HashMap。没错,Redis底层key的存储结构就是类似于HashMap那样数组+链表的结构。其中第一维的数组大小为2n(n>=0)。每次扩容数组长度扩大一倍。
scan命令就是对这个一维数组进行遍历。每次返回的游标值也都是这个数组的索引。limit参数表示遍历多少个数组的元素,将这些元素下挂接的符合条件的结果都返回。因为每个元素下挂接的链表大小不同,所以每次返回的结果数量也就不同。
SCAN的遍历顺序
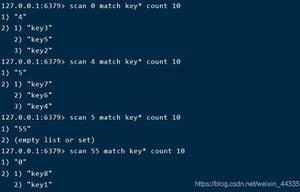
关于scan命令的遍历顺序,我们可以用一个小栗子来具体看一下。
127.0.0.1:6379> keys *
1) "db_number"
2) "key1"
3) "myKey"
127.0.0.1:6379> scan 0 MATCH * COUNT 1
1) "2"
2) 1) "db_number"
127.0.0.1:6379> scan 2 MATCH * COUNT 1
1) "1"
2) 1) "myKey"
127.0.0.1:6379> scan 1 MATCH * COUNT 1
1) "3"
2) 1) "key1"
127.0.0.1:6379> scan 3 MATCH * COUNT 1
1) "0"
2) (empty list or set)
我们的Redis中有3个key,我们每次只遍历一个一维数组中的元素。如上所示,SCAN命令的遍历顺序是
0->2->1->3
这个顺序看起来有些奇怪。我们把它转换成二进制就好理解一些了。
00->10->01->11
我们发现每次这个序列是高位加1的。普通二进制的加法,是从右往左相加、进位。而这个序列是从左往右相加、进位的。这一点我们在redis的源码中也得到印证。
在dict.c文件的dictScan函数中对游标进行了如下处理
v = rev(v);
v++;
v = rev(v);
意思是,将游标倒置,加一后,再倒置,也就是我们所说的“高位加1”的操作。
这里大家可能会有疑问了,为什么要使用这样的顺序进行遍历,而不是用正常的0、1、2……这样的顺序呢,这是因为需要考虑遍历时发生字典扩容与缩容的情况(不得不佩服开发者考虑问题的全面性)。
我们来看一下在SCAN遍历过程中,发生扩容时,遍历会如何进行。加入我们原始的数组有4个元素,也就是索引有两位,这时需要把它扩充成3位,并进行rehash。

原来挂接在xx下的所有元素被分配到0xx和1xx下。在上图中,当我们即将遍历10时,dict进行了rehash,这时,scan命令会从010开始遍历,而000和100(原00下挂接的元素)不会再被重复遍历。
再来看看缩容的情况。假设dict从3位缩容到2位,当即将遍历110时,dict发生了缩容,这时scan会遍历10。这时010下挂接的元素会被重复遍历,但010之前的元素都不会被重复遍历了。所以,缩容时还是可能会有些重复元素出现的。
Redis的rehash
rehash是一个比较复杂的过程,为了不阻塞Redis的进程,它采用了一种渐进式的rehash的机制。
/* 字典 */
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
在Redis的字典结构中,有两个hash表,一个新表,一个旧表。在rehash的过程中,redis将旧表中的元素逐步迁移到新表中,接下来我们看一下dict的rehash操作的源码。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
通过注释我们就能了解到,rehash的过程是以bucket为基本单位进行迁移的。所谓的bucket其实就是我们前面所提到的一维数组的元素。每次迁移一个列表。下面来解释一下这段代码。
- 首先判断一下是否在进行rehash,如果是,则继续进行;否则直接返回。
- 接着就是分n步开始进行渐进式rehash。同时还判断是否还有剩余元素,以保证安全性。
- 在进行rehash之前,首先判断要迁移的bucket是否越界。
- 然后跳过空的bucket,这里有一个empty_visits变量,表示最大可访问的空bucket的数量,这一变量主要是为了保证不过多的阻塞Redis。
- 接下来就是元素的迁移,将当前bucket的全部元素进行rehash,并且更新两张表中元素的数量。
- 每次迁移完一个bucket,需要将旧表中的bucket指向NULL。
- 最后判断一下是否全部迁移完成,如果是,则收回空间,重置rehash索引,否则告诉调用方,仍有数据未迁移。
由于Redis使用的是渐进式rehash机制,因此,scan命令在需要同时扫描新表和旧表,将结果返回客户端。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
以上是 Redis中scan命令的深入讲解 的全部内容, 来源链接: utcz.com/a/254229.html