大数据的下一站是什么?服务/分析一体化(HSAP)
作者:蒋晓伟(量仔) 阿里巴巴研究员
因为侧重点的不同,传统的数据库可以分为交易型的 OLTP 系统和分析型的 OLAP 系统。随着互联网的发展,数据量出现了指数型的增长,单机的数据库已经不能满足业务的需求。特别是在分析领域,一个查询就可能需要处理很大一部分甚至全量数据,海量数据带来的压力变得尤为迫切。这促成了过去十多年来以 Hadoop 技术开始的大数据革命,解决了海量数据分析的需求。与此同时,数据库领域也出现了一批分布式数据库产品来应对 OLTP 场景数据量的增长。
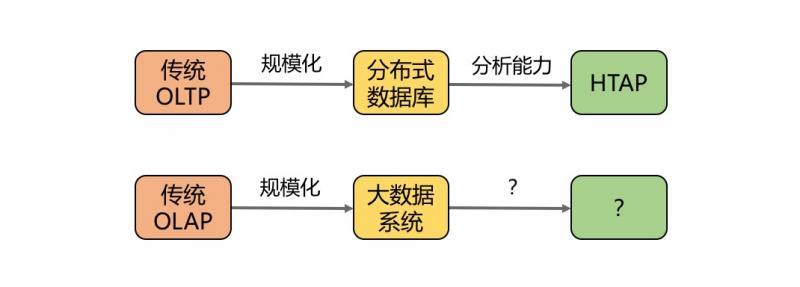
为了对 OLTP 系统里的数据进行分析,标准的做法是把里面的数据定期(比如说每天)同步到一个 OLAP 系统中。这种架构通过两套系统保证了分析型查询不会影响线上的交易。但是定期同步导致了分析的结果并不是基于最新数据,这种延迟让我们失去了做出更及时的商业决策的机会。为了解决这个问题,近几年出现了 HTAP 的架构,这种架构允许我们对 OLTP 数据库里的数据直接进行分析,从而保证了分析的时效性。分析不再是传统的 OLAP 系统或者大数据系统特有的能力,一个很自然的问题是:既然 HTAP 有了分析的能力,它是不是将取代大数据系统呢?大数据的下一站是什么?
背景
为了回答这个问题,我们以推荐系统为例分析一下大数据系统的典型场景。
当你看到购物应用给你展示正好想要买的商品,短视频应用播放你喜欢的音乐时,推荐系统正在发挥它神奇的作用。一个先进的推荐系统,核心目标是根据用户的实时行为做出个性化的推荐,用户和系统的每一次交互都将即时优化下一步的体验。为了支持这样一个系统,后端的大数据技术栈已经演变为一个非常复杂和多元化的系统。
下图展示了一个支持实时推荐系统的大数据技术栈。
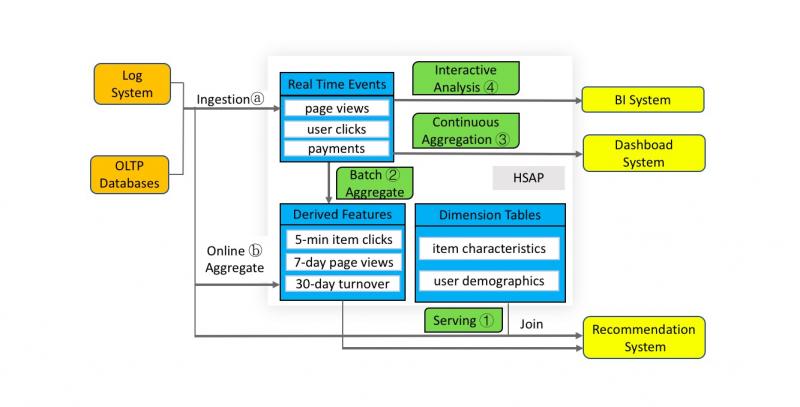
为了提供优质的实时个性化推荐,推荐系统重度依赖实时特征和模型的连续更新。
实时特征可以分为两类:
系统会收集大量的用户行为事件(比如说浏览、点击等),以及交易记录(比如说从 OLTP 数据库同步过来的付款记录等)。这些数据量非常巨大(可能高达每秒种数千万甚至上亿条),并且其中的绝大部分不是来自交易系统。为了方便以后使用,这些数据会导入到系统里(图中的 a),同时它们会和各种维表数据做关联推导出一系列重要的特征(图中的 1),这些特征会实时更新到推荐系统以优化用户体验。这里的实时维表关联需要低延迟高吞吐的点查支持才能跟得上新产生的数据。
系统也会使用滑动窗口等方式去计算出各种不同维度和时间粒度的特征(比如说一个商品过去 5 分钟的点击数、过去 7 天的浏览量和过去 30 天的销售等)。根据滑动窗口的粒度,这些聚合可能通过流计算或者批处理的方式完成。
这些数据也被用来产生实时和离线机器学习的样本,训练出来的模型经过验证后会持续地更新到推荐系统中。
上述所解释的是一个先进的推荐系统的核心部分,但这只是整个系统的冰山一角。除此之外还需要实时模型监控、验证、分析和调优等一整套体系,这包含:使用实时大屏去查看 A/B 测试的结果(3),使用交互式分析(4)去做 BI 分析,对模型进行细化和调优。除此之外,运营还会使用各种复杂的查询去洞察业务的进展,并且通过圈人圈品等方式进行针对性的营销。
这个例子展示了一个非常复杂但典型的大数据场景,从数据的实时导入(a),到预聚合(b),从数据服务(1),持续聚合(3),到交互式查询(4),一直到批处理(2)。这类复杂场景对大数据系统有着非常多样化的需求,在构建这些系统的实践中我们看到了两个新的趋势。
**实时化:**业务需要快速地从刚刚收集到的数据中获得商业洞察。写入的数据需要在秒级甚至亚秒级就可见。冗长的离线 ETL 过程正在变得不可容忍。同时,收集到的数据比从 OLTP 系统同步过来的数据要大得多,用户浏览点击等日志类数据甚至要比它大几个数量级。我们的系统需要有能力在大量实时数据写入的同时提供低延迟的查询能力。
**服务 / 分析的融合:**传统的 OLAP 系统在业务中往往扮演着比较静态的角色。我们通过分析海量的数据得到业务的洞察(比如说预计算好的视图、模型等),这些获得的知识通过另外一个系统提供在线数据服务。这里的服务和分析是个割裂的过程。与此不同的是,理想的业务决策过程往往是一个持续优化的在线过程。服务的过程会产生大量的新数据,我们需要对这些新数据进行复杂的分析。分析产生的洞察实时反馈到服务创造更大的商业价值。服务和分析正在形成一个闭环。
现有的解决方案通过一系列产品的组合来解决实时的服务 / 分析融合的需求。比如说,通过 Apache Flink 做数据的实时预聚合,聚合后的数据会存储在类似 Apache Druid 这种提供多维分析的产品中,并且通过 Apache HBase 这类产品来提供数据服务。这种烟囱式开发的模式会不可避免地产生数据孤岛,从而引起不必要的数据重复,各个产品间复杂的数据同步也使数据的一致性和安全性成为挑战。这种复杂度使得应用开发很难快速响应新需求,影响了业务的迭代速度,也给开发和运维都带来了较大的额外开销。
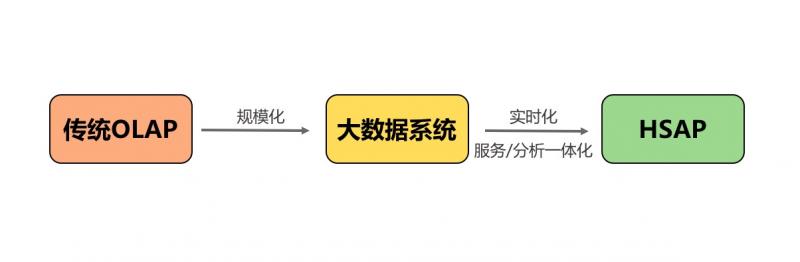
我们认为实时的服务 / 分析的融合应该通过一个统一的 Hybrid Serving/Analytical Processing(HSAP)系统来实现。
通过这样一个系统,应用开发不再需要和多个不同的产品打交道,不再需要去学习和接受每个产品的问题和局限,这能够大大简化业务的架构,提升开发和运维效率。这样一个统一的系统能够避免不必要的数据重复从而节约成本。同时这种架构还能够为系统带来秒级甚至亚秒级的实时性,让业务的决策更实时,从而让数据发挥出更大的商业价值。
分布式 HTAP 系统虽然具有了实时分析的能力,但是并不能解决大数据的问题。
首先,交易系统同步过来的数据只是实时推荐系统需要处理的一小部分数据,其他绝大部分数据来自日志等非交易系统(用户每次购买前往往有数十个甚至数百个浏览行为),大部分分析是在这些非交易数据上进行的。但 HTAP 系统并没有这部分数据,所以在这些非交易数据上做分析就无从谈起。
那么是不是可以将这些非交易数据写入 HTAP 系统来进行分析呢?我们来分析一下 HTAP 系统和 HSAP 系统在数据写入模式上的不同。HTAP 系统的基石和优势是支持细粒度的分布式事务,交易型数据往往以很多分布式小事务的方式写入 HTAP 系统。然而来自日志等系统的数据并没有细粒度分布式事务的语意,如果要把这些非交易型数据导入 HTAP 系统势必会带来不必要的开销。
相比之下, HSAP 系统并没有这种高频率分布式小事务的需求。数据写入 HSAP 系统一般有两种模式:1)海量的单条数据实时写入;2)相对低频的分布式批量数据写入。这就允许 HSAP 系统在设计上做出一系列优化,从而提升性价比,避免把非交易型数据导入 HTAP 系统带来的不必要开销。
就算我们不在乎这些开销,假设能不计成本把数据都写入 HTAP 系统,是不是就解决问题了呢?答案仍然是否定的。
支持好 OLTP 的场景是 HTAP 系统的前提条件,为了做到这点,HTAP 系统往往采用了行存的数据格式,而分析型的查询在行存的效率相比于列存有很大的(数量级的)劣势。**具备分析的能力和能够高效地分析并不是一回事。**为了提供高效分析的能力,HTAP 系统必须把海量的非交易数据复制到列存,但这势必带来不小的成本,不如把少量的交易数据复制到 HSAP 系统成本更低,同时还能更好地避免对线上交易系统产生影响。
所以,我们认为 HTAP 和 HSAP 会相辅相成,分别引领数据库和大数据领域的方向。
HSAP 的挑战
作为一种全新的架构,HSAP 面临着和已有的大数据以及传统的 OLAP 系统相比很不一样的挑战。
**高并发的混合工作负载:**HSAP 系统需要处理远远超出传统的 OLAP 系统的并发查询。在实践中,数据服务的并发远远超出了 OLAP 查询。比如说,我们在实践中见到数据服务需要处理高达每秒钟数千万个查询,这比 OLAP 查询的并发高出了 5 个数量级。同时,和 OLAP 查询相比,数据服务型查询对延迟有着更加苛刻的要求。除此之外,更大的挑战是系统在提供数据服务查询的同时需要处理非常复杂的分析型查询。这些混合查询负载在延迟和吞吐间有着非常不同的取舍。如何高效地利用系统资源处理好这些非常不一样的查询,并且保证每个查询的 SLO 是一个巨大的挑战。
**高吞吐实时数据导入:**在处理高并发的查询负载的同时,HSAP 系统还需要支持海量数据的实时写入。这些实时写入的数据量远远超出了传统的 OLAP 系统的需求。比如说,上面的实时推荐场景会持续写入每秒钟数千万甚至上亿条事件。和传统的 OLAP 系统的另外一个区别是 HSAP 系统对数据的实时性有着很高的要求,写入的数据需要在秒级甚至亚秒级可见,这样才能保证我们服务和分析结果的时效性。
**弹性和可扩展性:**数据写入和查询负载可能会有突发的高峰,这对系统提出了很高的弹性和可扩展性的要求。在实践中,我们注意到数据写入峰值能达到平均的 2.5 倍,查询的峰值能达到平均的 3 倍。而且数据写入和查询的峰值不一定同时出现,这也需要系统有根据不同的峰值做迅速调整的能力。
HSAP 的系统设计
为了应对这些挑战,我们认为一个典型的 HSAP 系统可以采用类似于上图的一个架构。
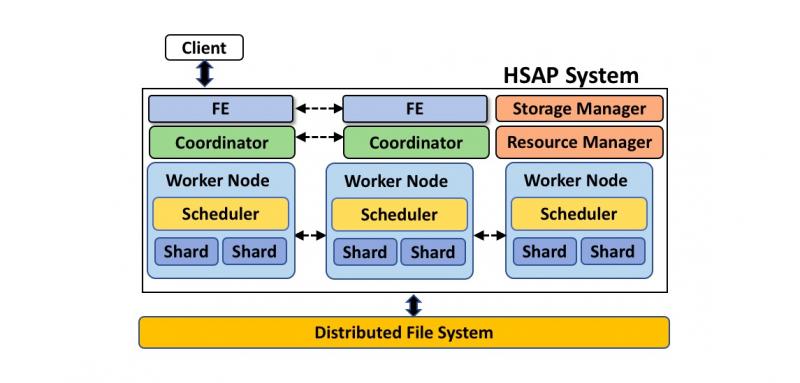
**存储计算分离:**所有的数据存储在一个分布式文件系统中,我们以数据分片的方式来扩展系统,Storage Manager 会管理这些数据分片(Shard),Resource Manager 管理系统的计算资源,保证系统能够处理高吞吐的数据写入和查询的需求。这种架构能够快速应对工作负载的变化,当查询负载变大需要更多的计算资源的时候可以扩展计算资源,当数据量快速增长的时候可以快速扩展存储资源。存储计算分离的架构保证了不需要等待移动 / 拷贝数据就能快速完成这些操作。这种架构较大地简化了运维,为系统的稳定性提供了保障。
**统一的实时存储:**为了能够支持各种查询模式,统一的实时存储层至关重要。查询大体可以分为两类,一类是简单的点查询(数据服务类的大多是这类),另一类是扫描大量数据的复杂查询(分析类的大多是这类),当然这是一个连续变化的过程,很多查询介于两者之间。这两种查询模式对数据存储也提出了不同的要求。行存储能够比较高效地支持点查询,而列存储在支持大量扫描的查询上有明显的优势。我们可以通过类似 PAX 的方式在行存和列存之间做一个折衷,付出的代价是可能在点查和扫描数据的场景都不能获得最佳的性能。我们希望在两种场景都做到最优,所以在系统里同时支持了行存和列存,用户可以根据场景选择每个表的存储方式。对同时有两种需求的表我们通过索引的抽象允许用户同时选择两种存储,系统通过索引维护的机制保证两者间的一致性。在实践中我们发现这种设计带来的效率和灵活性能够更好地支持业务。
**工作负载的隔离:**系统在混合工作负载下的 SLO 是通过调度来保证的。在理想情况下,一个大查询就应该能把所有的资源都利用起来。而当有多个查询同时运行的时候,这些查询需要公平地共享资源。由于服务型的查询通常比较简单从而需要的资源比较少,这种公平调度的机制能够保证服务型查询的延迟即使在有复杂的分析型查询的情况下仍然能够得到保障。作为一个分布式的系统,调度可以分为分布式和进程内两部分。Coordinator 会把一个查询分解为多个任务,这些任务被分发到不同的进程,Coordinator 需要采取一定的策略保证公平性。同样重要的是,在一个进程内我们也需要让不同任务公平地分享资源。由于操作系统并不理解任务间的关系,所以我们在每个进程里实现了一个用户态的 Scheduler 去更灵活地支持工作负载的隔离。
**系统的开放性:**很多业务已经使用了其他存储平台或者计算引擎,新的系统必须考虑和已有系统的融合。对时效性要求高的查询,计算和存储的一体化能够带来明显的优势。但是对时效性不高的离线计算,存储层可以提供统一的接口开放数据,这种开放性允许其他引擎把数据拉出去处理能够赋予业务更大的灵活度。开放性的另外一面是对存储在其他系统中数据进行处理的能力,这个可以通过联邦查询的方式去实现。
HSAP 的应用
这里我们分享一下阿里巴巴搜索推荐精细化运营业务,下图显示了在采用 HSAP 前这样一个系统架构的示例。
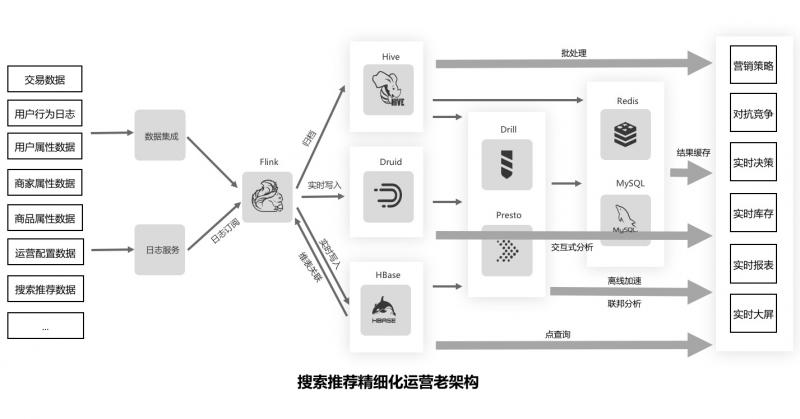
我们通过一系列存储和计算引擎(HBase、Druid、Hive、Drill、Redis 等)的复杂配合才能满足业务的需求,并且多个存储之间需要通过数据同步任务来保持大致的同步。这种业务架构极其复杂,整个业务的开发耗费了大量的时间。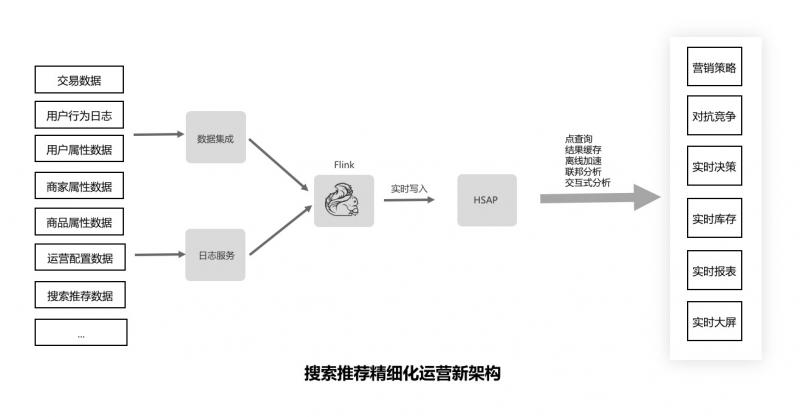
我们在 2019 年的双十一使用 HSAP 系统升级了这个业务,新架构得到了极大的简化。用户、商品、商家属性数据和海量的用户行为数据经过实时和离线的数据清洗统一进入 HSAP 系统,由 HSAP 系统向上承接了实时大屏、实时报表、效果跟踪、实时数据应用等查询和分析服务。实时大屏、实时销售预测、实时库存监控、实时 BI 报表实时监测业务进展,洞悉运营增长,跟踪算法效果,从而助力高效决策。实时标签、实时画像、竞对分析、圈人圈品、权益投放等数据产品助力精细化运营和决策。实时数据接口服务支持算法调控、库存监控预警等服务。一套 HSAP 系统实现了全渠道全链路的数据共享和复用,解决了运营、产品、算法、开发、分析师到决策层不同业务视角的数据分析和查询需求。
总结
HSAP 架构通过统一的实时存储,数据无需复制就能一站式提供简单查询、OLAP 分析、在线数据服务等多样化的数据查询和应用服务,满足数据应用方的访问和接入需求。这种新架构大大地降低了业务的复杂度,让我们能够快速应对新的业务需求。它提供的秒级甚至亚秒级实时性让决策更及时高效,从而让数据创造出更大的商业价值。
最后,欢迎加入交互式分析Hologres交流群

以上是 大数据的下一站是什么?服务/分析一体化(HSAP) 的全部内容, 来源链接: utcz.com/a/24339.html