希尔排序算法是如何进行的?
前言




概念介绍
- 希尔排序是基于插入排序算法的一种更高效的改进版本。
- 它是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越少,当增量减少至1时,整个文件恰被分成一组。此时算法便终止。
原理讲解
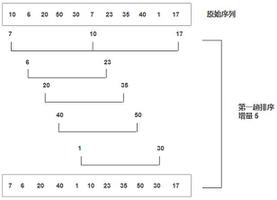
以[41 24 34 2 19 17]这个序列为例说明希尔排序算法的实现原理
- 未开始遍历时,此时效果如下图
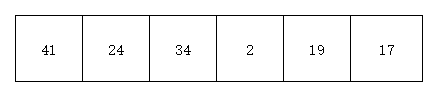
- 由上面数组可知,该数组长度为6,我们人为的选择增量为gap=6/2=3,故将整个数组分为3个子数组(颜色相同为一组),分别为[41 2],[24 19],[34 17]。效果如下图
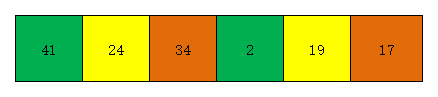
- 第一次遍历时(增量为3),我们分别对三个子数组进行插入排序,插入排序后3个子数组变为[2 41],[19 24],[17 34]。效果如下图
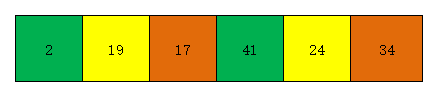
- 第二次遍历时(增量为1),我们对整个数组[2 19 17 41 24 34]进行插入排序,插入排序后效果如下图
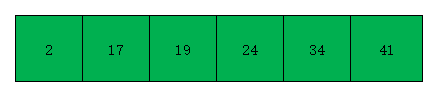
- 至此,希尔排序原理讲解完毕。
时间复杂度
由希尔排序的过程可知,该算法的时间复杂度和增量有很大关系。如果增量为1,此时希尔排序就是插入排序;如果增量为Hibbard增量,此时希尔排序算法则明显有别于插入排序;
| 数据个数 | 增量为1时最大比较次数 |
|---|---|
| 1 | 0 |
| 2 | 1 |
| 3 | 3 |
| 4 | 6 |
| 5 | 10 |
| 10 | 45 |
| N | 1/2N(N-1) |
所以根据时间复杂度的概念,当增量为1时希尔排序算法的时间复杂度为O(N^2);
当增量为Hibbard增量时希尔排序算法的时间复杂度为O(N^3/2)(这个留着有兴趣的同学自行证明)
空间复杂度
- 空间复杂度是对一个算法在运行过程中临时占用存储空间大小的度量。
- 由于希尔排序算法前后占用空间大小不变,由空间复杂度含义可知,该算法空间复杂度为O(1)
算法优缺点
- 优点:速度快;移动次数少
- 缺点:不稳定;增量选择不定,只能根据数据量靠经验选取
效果展示
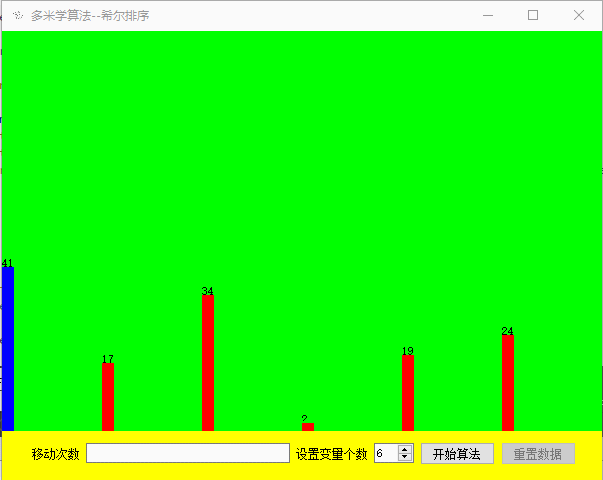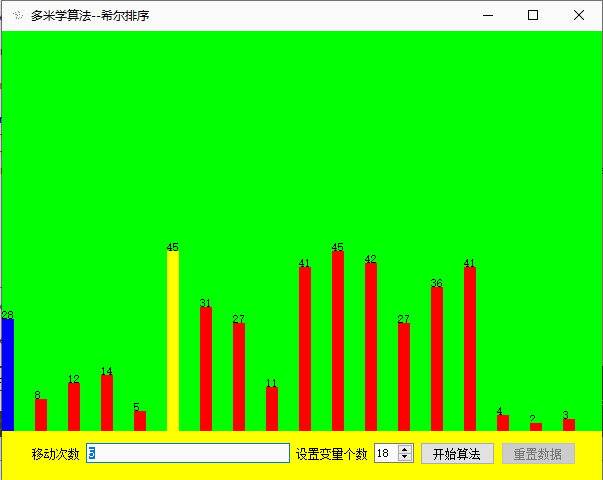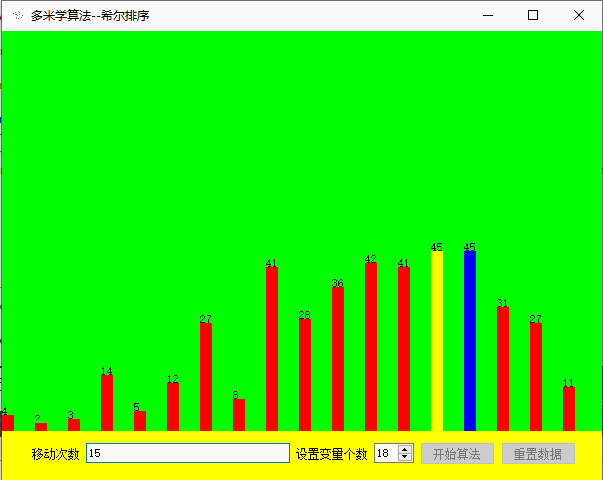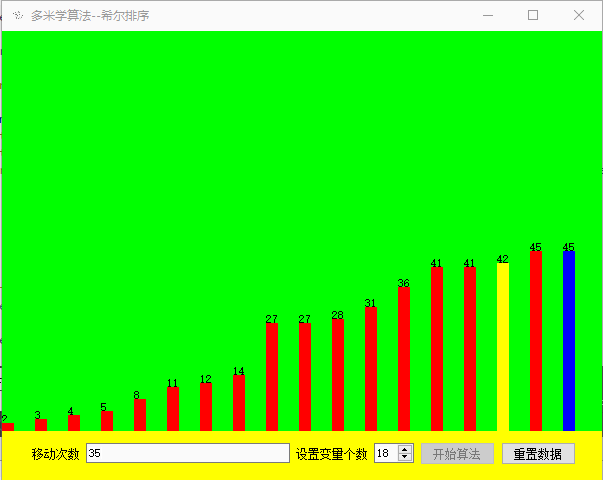
源码下载
- 请在公众号中回复“算法源码”即可获得十大经典排序算法源码
更多算法学习请关注我的公众号

以上是 希尔排序算法是如何进行的? 的全部内容, 来源链接: utcz.com/a/24347.html