Streaming Systems读书笔记:Streaming
不太喜欢看英文书所以拖了很久,但这本书又实在名气太大了……
DDIA 的作者 Martin Kleppmann 是这样评价本书的:
If you care about the correctness of your streaming and batch processing jobs, this book is a must-read. It provides the most clearthinking and logical discussion of the topic that I have seen, and its ideas are brilliantly explained.
本书作者 Tyler Akidau 在流处理领域是无人不知的大牛。他的文章the Streaming 101和Streaming 102很有名,现在成了本书的序章。网上有人喜欢把这两篇说成是论文,这其实说的是这篇2015 Dataflow Model)。它可以说是现代流式计算的基石。
老外的计算机书籍通常会厘清一些非常晦涩的概念,然后再阐述整个过程。
What Is Streaming?
流处理系统并不能等同于无界数据的处理。实际上,有界和无界代表的是数据集的基数(cardinality),而流对应的是数据的构造(constitution)。这个术语指的是数据集物理的形式,我们和数据集打交道的方法,而另一个典型的构造是 SQL 中的表。这就是为什么像 Spark 这样的批处理引擎要使用 DataFrame 这样的模型来表示数据,它是一个对数据的全量视图(A holistic view of a dataset at a specific point in time)。而流数据是不断随逐个元素变化的。
Lambda 架构的盛行,是因为流处理被认为是不准确的观念在人们心中根深蒂固。而作者认为流处理引擎可以做到和批处理一样的准确性,甚至可以完全替代批处理。那么关键在于两点:
- 正确性(Correctness)。
- 时间相关的工具(Tools for reasoning about time)。
第一个很好理解,其实就是流处理中的仅一次(exactly-once)语义。流处理系统只有做到了仅一次处理,才能实现强一致性,这就是为什么像 Flink 这样现代的流处理引擎天然就支持仅一次语义。
第二个指的是处理无界数据的事件时间倾斜问题(varying event-time skew),实际上这也体现为批处理超集的能力。这就是初学 Flink 的人常常困惑的一些概念,比如 Watermark,Trigger 等等,其实都是按图索骥罢了。
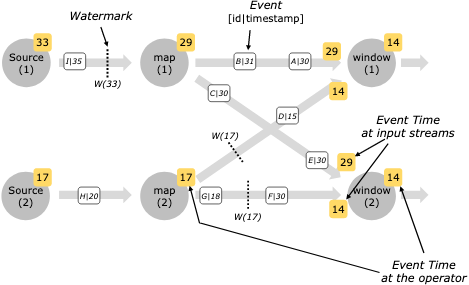
事件时间(Event Time)是一个流处理中重要的概念。原因在于无界数据集的数据有可能到达系统的时间不一,而且是无规律可循的——
the skew between event time and processing time is not only nonzero, but often a highly variable function of the characteristics of the underlying input sources, execution engine, and hardware.
我们把到达时间作为另一种度量,即处理时间(Process Time)。二者关系如下:
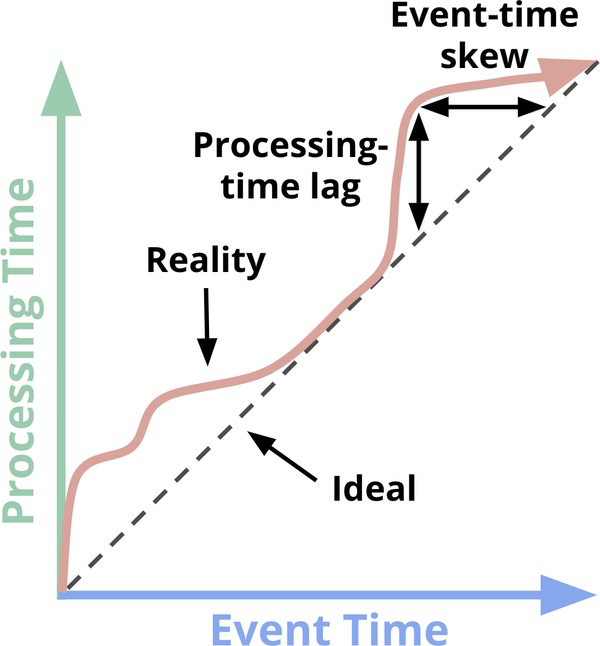
因此最终将得到一个问题:如何在延迟的处理时间下,保证数据计算的完整性?常见的批处理模式是针对有界数据设计的,而面对无界数据,批处理引擎可以采取固定窗口(Fixed windows)。这个数据处理模式(Data Processing Patterns)最典型的就是 Spark Streaming,也就是微批处理——将数据按照固定的时间间隔划分窗口,然后每个窗口计算一次。
问题是,这个处理是和处理时间绑定的,而不是事件时间。当然你也可以每当数据到达时计算一次,那么何时结束这个计算呢?在流处理场景中,一种常见的场景是处理 Session(这里应该并不特指用户 session,而是一种任何一段时间内的活动)。显然,固定窗口无法处理 Session,因为 batch 总是无法精确匹配 Session 的大小。也就是说,需要引擎提供一种特殊的机制(而不是通过自己实现复杂的逻辑),专门为 Session 而设计。
接下来看看流处理的模式。流处理专门为无界数据而设计。而现实中无界数据不仅仅只有无界的特点,还有:
- 高度无序的事件时间(Highly unordered with respect to event times)。
- 不断变化的时间倾斜(Of varying event-time skew)。
因此,作者将通常的处理分为4种情况,依赖于对时间的敏感度:
- 时间无关(Time-agnostic)。比如,筛选所有满足某个条件的数据,检查每个数据是否满足黑白名单。另外无界数据的 inner join 也属于此类,只要我们只关心数据的结果。
- 近似(Approximation algorithms)。这个也很容易理解,比如求近似的 TOPN,或者使用概率性数据结构求 PV 等。注意到近似也会用到时间,但是处理时间。
- 窗口(Windowing)。作者将窗口类型分为固定、滑动、Session 三种。滑动窗口也是一种常见需求,比如每隔1分钟统计前1小时的 pv之类的。实际上,滑动窗口是固定窗口的泛化。

这里重点讨论窗口。窗口可以按照事件时间或者处理时间分类。按照处理时间的窗口是非常简单的,只需要像 Spark Streaming 这样定时触发即可。另外,当我们需要按照事件观测的时间推断信息(infer information about the source as it is observed)时,比如监控一个 web 服务请求的流量来检测请求的成功率。
不过,如果需要事件时间,那么这种模式必须保证事件时间有序(those data must arrive in event-time order)。即使在 Kafka 这样的流处理存储中,这一点也很难保证。书中举的例子也很经典,比如手机上报埋点中断再上传。所以,处理时间无法替代事件时间的窗口。
那么最后就引出了流处理中的一个重要概念:事件时间窗口(Windowing by event time)。他是这样的:
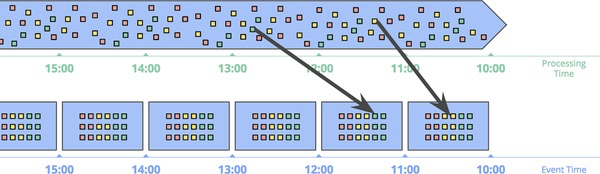
或者是这样的(Session 窗口):
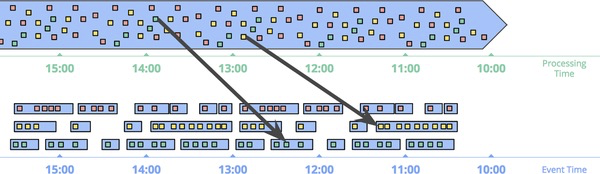
如果从 Spark Streaming 的角度来看,我们只是针对每个窗口保存了一个 Checkpoint。新的数据调用类似于mapWithStates的方法进行合并。显然,这种模式有这样的缺点:
- 缓存(Buffering)。相比前一种,我们缓存了更多的数据。但是从 MapReduce 发展至今,内存、网络带宽早已不是核心瓶颈,所以这种空间的 tradeoff 是可接受的。另外,我们存储的可能是聚合的结果,所以并不总是需要缓存数据的整个快照。
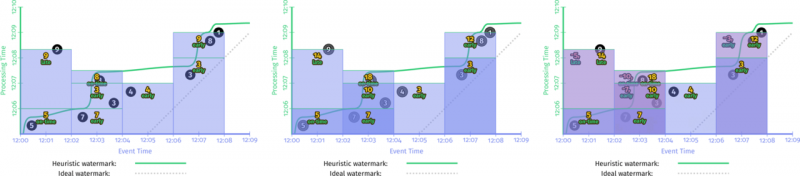
- 完整性(Completeness)。何时触发窗口的计算(这里书中的说法是 materialize,我换成了一种更易懂的解释)?实际上,我们无法得到一个准确的 timing。但是,可以通过一种适度精确的、启发式的度量(reasonably accurate heuristic estimate of window completion)来处理,比如 Watermark。什么叫适度精确和启发式呢?熟悉 Flink 的同学知道,我们会用到达事件本身的时间来作为参照设置 Watermark(比如取到达数据事件时间的最大值)。不过,书中也提到,某些场景可能需要完全准确的结果(当然就是钱的事情了),在这种场景下需要构建窗口何时何法处理的管道——But for cases in which absolute correctness is paramount (again, think billing), the only real option is to provide a way for the pipeline builder to express when they want results for windows to be materialized and how those results should be refined over time.
以上是 Streaming Systems读书笔记:Streaming 的全部内容, 来源链接: utcz.com/a/22535.html