《Streaming Systems》读书笔记(三):Watermark
感觉这一章写的……怎么说呢,都是概念,而并没有像我预期的一样,提供什么银弹。
形而上学的说,Watermark 是解决一个持续性数据处理管道何时关闭事件时间窗口的工具。之前我们可以看到,使用处理时间作为窗口的时间这种方法并不合理。这里书中还提到一种方法,是观察信息处理的速率。然而,这种方法看起来就漏洞百出:如何根据不同的时间窗口来考虑速率?程序宕机等问题出现时,处理速率一定会有异常,但这是否代表着需要关闭窗口?
作者认为,合理的方法是利用一种逻辑时间戳,通常是事件发生的时间。由于分布式的 agent 之间不保证次序,最终处理中和已处理的消息可能是这样的分布:
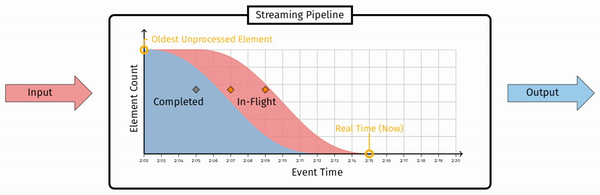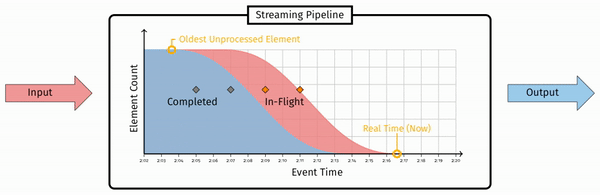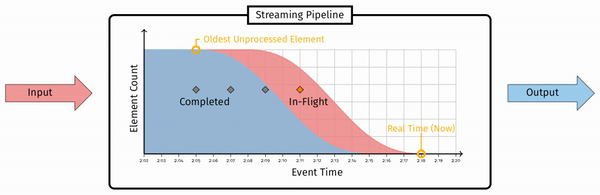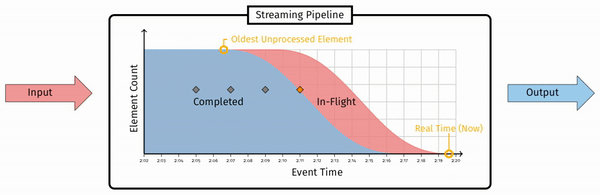
而这里in-flight 最左侧的消息,即已接收的消息中时间戳最小的,这个时间戳即为 Watermark。形式化的定义是(注意这里的定义其实是低水印):
The watermark is a monotonically increasing timestamp of the oldest work not yet completed.
注意 Watermark 定义的要点:单调递增、未完成。这个定义代表了两个属性:
- 完整性(Completeness):一旦 Watermark 大于某个时间戳 T,那么就代表这个时间戳及之前的数据不会再被处理。
- 可见性(Visibility):如果一个消息阻塞,那么 Watermark 也会被阻塞(无法递增)。
Watermark Creation
前面章节提到,Watermark 分为完美型和启发型。完美型水印通常需要对输入有全面的了解。比如,入口时间戳(Ingress timestamping)——其实就是指使用处理时间作为 Watermark。实际上,我们如果不考虑 Watermark 这个术语,这就是 Spark Streaming 这样的引擎选择的方式(不考虑后来的 Structured Streaming):在某个固定的时间间隔关闭窗口。还有一种完美型水印是排序的静态日志集(Static sets of time-ordered logs)。这里之所以说的这么绕口主要是针对 Kafka 这样的可分布式的数据源,如果可以实现全局有序,那么可以去掉静态这个限定词(如果分区数不变,那么只需要追踪每个分区得到一个最小时间戳即可)。反过来,如果数据源是动态的,那么就需要使用启发式水印。
Watermark Propagation
Watermark 如何在不同的 Stage 进行传播?这里的 Stage 可以类比 Spark Streaming 中的 Stage(由 Shuffle 产生)。比如,计算每个用户的聚合,然后使用这些聚合来计算每个团队的聚合,这将分为3个 Stage。
当水印在流中传播时,Stage 的不同可能会导致数据粒度的不同。因此,每个 Stage 都追踪它自己的水印。根据 Stage 的边界,我们可以把 Watermark 分为 Input Watermark 和 Output Watermark 两种:输入水印是对上游水印最小值的捕获,而输出水印是对输入水印和数据本身事件时间的捕获。
写到这里,碰巧遇到了一直很反感的事情:中文社区的抄袭(成风)。因为 Flink Watermark 传播机制在官方文档也一直说的不是特别详细,我想看一下有没有好的文章,结果就遇到了这个:
显然,这是大家民间翻译的书中内容。实际上,我甚至也不是针对此时的某人,而是对所谓知识社区的各种反刍感到难过:难道人类的本质,只能是当复读机吗?
由于下游对于数据整体的认知更少(粒度),因此下游 Operator 生成的水印更旧。定义输入输出水印还有一个好处,就是追踪每个 Stage 引入的事件时间延迟。这个延迟等于输入水印-输出水印。比如,一个 10s 的聚合窗口会有 10s 以上的延迟(这个以上我不是很理解,但聚合的粒度会导致延迟应该很好理解)。
每个 Stage 的处理不是单一的。我们可以把流处理的任意 Stage 处理抽象成若干个组件:

即通过若干个输入,若干个状态和中间的逻辑代码,输出到若干个缓冲区中。所以最后的输出水印是其中的最小值:
- 每个源的水印(Per-source watermark):每个数据源 Stage(最开始的那个)都有一个源的水印
- 每个外部输入的水印(Per-external input watermark)
- 每个状态组件水印(Per-state component watermark)
- 每个输出缓冲水印(Per-output buffer watermark)
当然,本书只是刻意的将这里的水印划分的很细,实际中也许我们并不用得到。
按照前面说计算手机和 PC 上用户的平均 Session 长度:
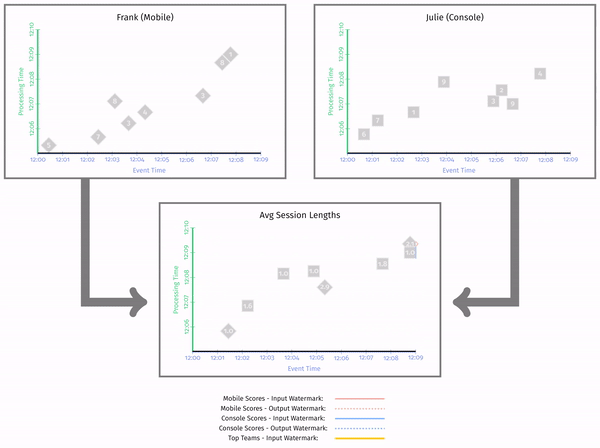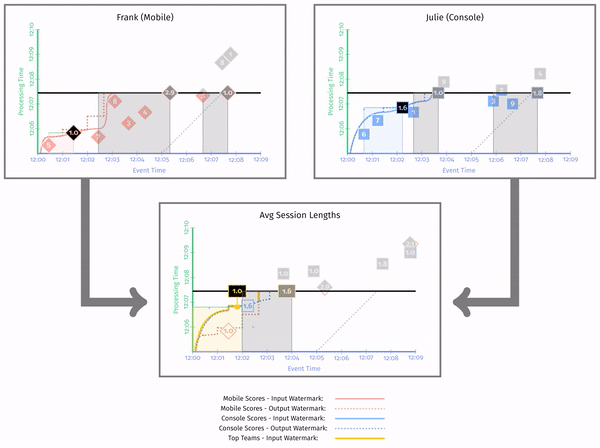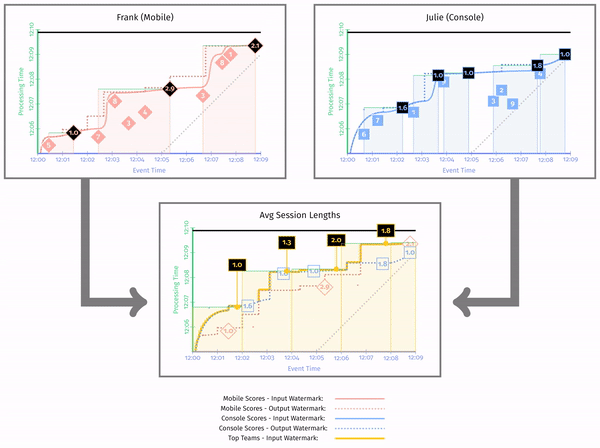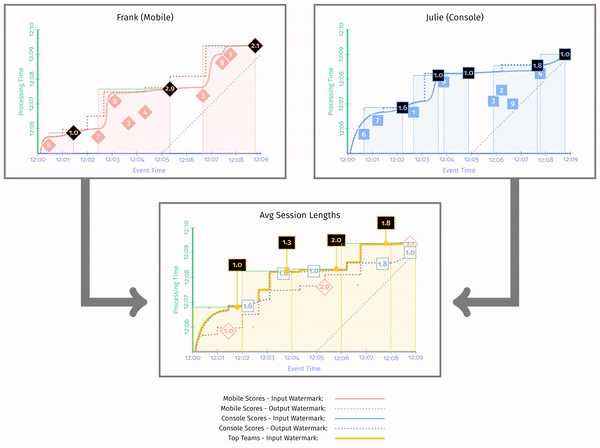
这里再提一下 Session 的定义。Session 指的是一段时间内事件的连续出现,也就是说如果事件超过了一定时间,那么就认为 Session 结束。这也是 Session 计算的方法。这里书中是直接将当前窗口作为 Session 的长度,可能不太准确(在最后结束的时候多了一截)。
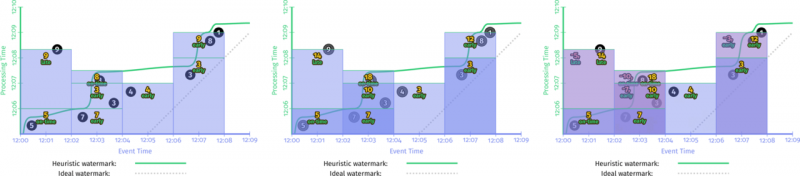
在图中,我们可以看到最后的聚合水印在最左边,同时输出水印总是在输入水印的左边。同时,聚合水印是前面两个输出水印的最小值。
Output Timestamps
在聚合输出时,不光要输出水印,还要输出时间戳。如果是计算一个窗口的聚合值,那么时间戳使用什么合适呢?
- 窗口的结尾(End of the window)
- 窗口中第一个没有迟到数据的时间戳(Timestamp of first nonlate element)
- 窗口中特定元素的时间戳(Timestamp of a specific element)
如果按照窗口的结尾来作为输出的时间戳:
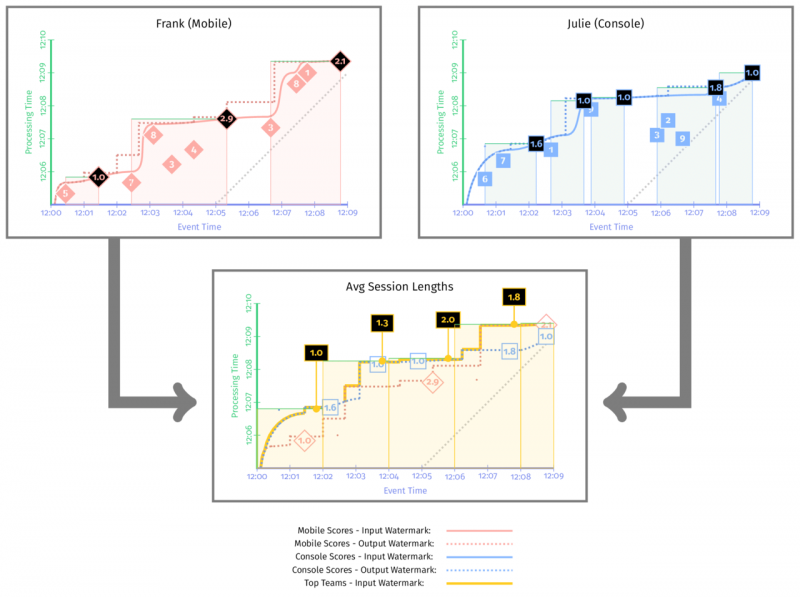
当窗口为 Session 窗口时,窗口中第一个没有迟到数据的时间戳就是窗口的开头。对比一下:
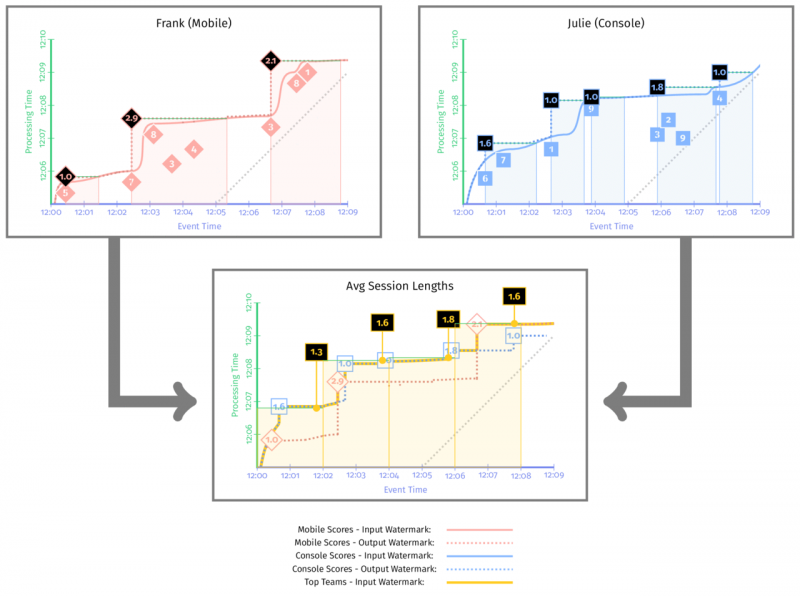
可以看到这里输出水印(虚线部分)的时间戳更早,这是因为作为下游唯一输出的元素(平均会话长度)的时间戳,水印必须小于等于这个值。但是,这并不意味着这个水印更早得到。可以看到,前一个图中输出水印一开始总是跟随着输入水印的曲线,这说明以窗口的结尾作为输出时间戳,水印更容易向前推进。
对于滑动窗口,使用第二种策略会有一些明显的延迟。
Percentile Watermarks
了解数据库的人知道,数据库的代价估计依赖于统计信息。而 Watermark 也有比较明显的统计学特点——最简单的是,我们用百分位数来代替时间戳的最小值。这样,就可以在精度和效率之间进行 tradeoff。
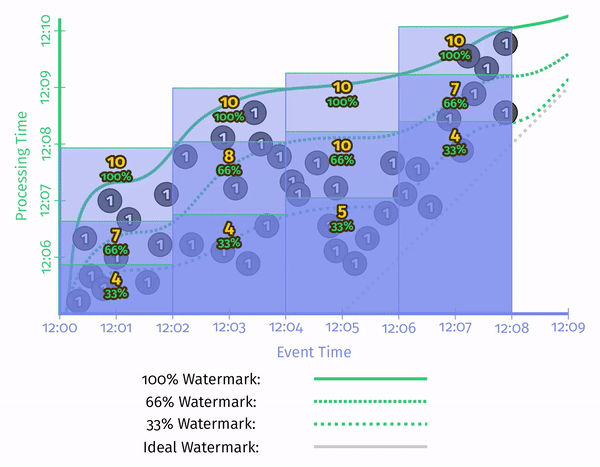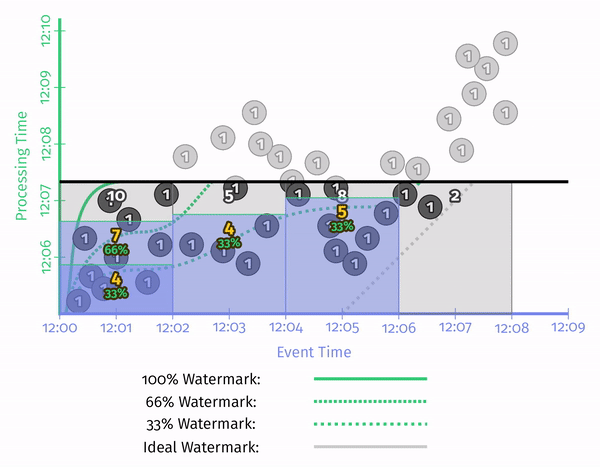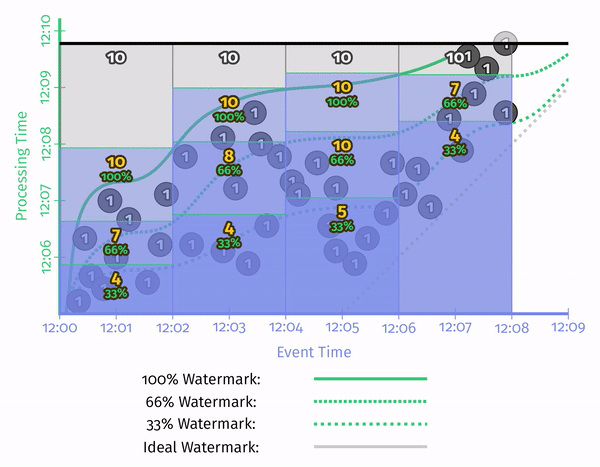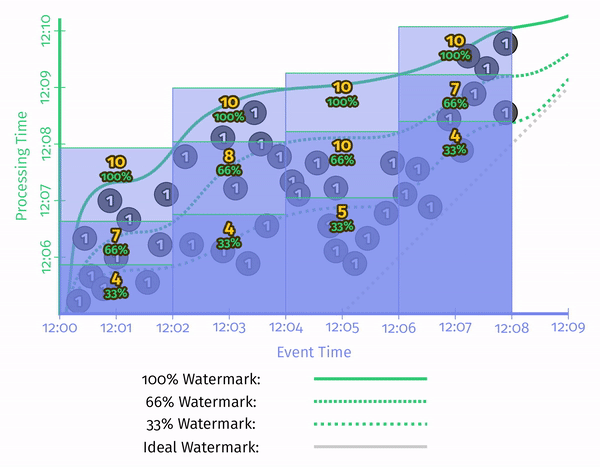
Processing-Time Watermarks
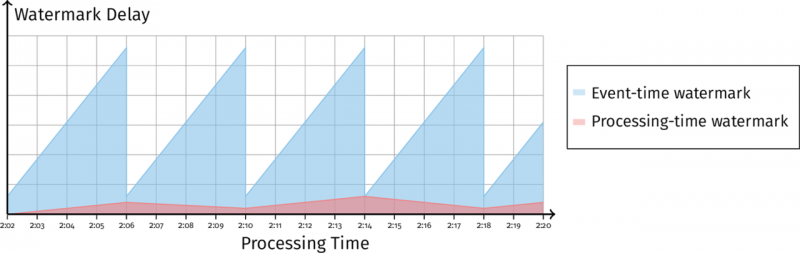
前面提到,Watermark 有两种作用:作为窗口何时关闭的依据,以及了解数据是否延迟(用实时时间减去水印时间)。但是,事件时间水印有一个缺点:无法区别究竟是数据问题还是系统问题——到底是数据延迟了,还是一个系统一直在快速处理,但是系统是在一个小时前处理的。这就引入了处理时间水印。
当处理时间和事件时间水印是这样的:

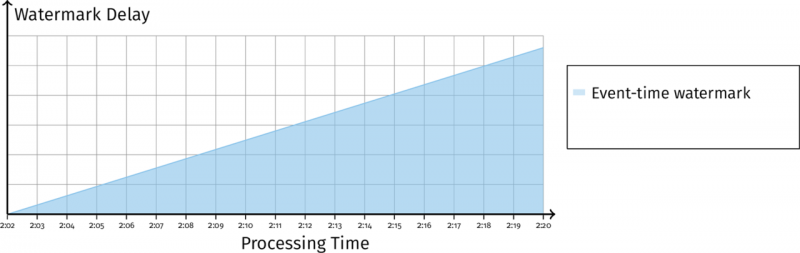
说明此时系统被阻塞了。相反,如果是这样的:

说明可能是在等待某些状态的存储(Flink 的 Checkpoint 操作)。
前面的例子,使用第一个非迟到元素作为输出时间戳时,可能水印是这样的:
Case Studies
最后本书带我们看了一下不同的 Watermark 实现。第一个是作者所在的 Google 的产品 Google Cloud Dataflow。它执行严格的 Keyby 操作,将根据键值分配 Worker。每个分区都有自己的水印,因此最后需要进行聚合。Google Cloud Dataflow 通过一个集中的聚合器(centralized aggregator agent)完成,这个聚合器也是可分区的。显然,聚合水印是一件比较有挑战性的工作。
第二个例子是大家最熟悉的 Flink。个人觉得 Flink 的设计更科学:Flink 使用了自身的 Checkpoint 机制,将 Watermark 随着数据一起流动。看一下官方的图:
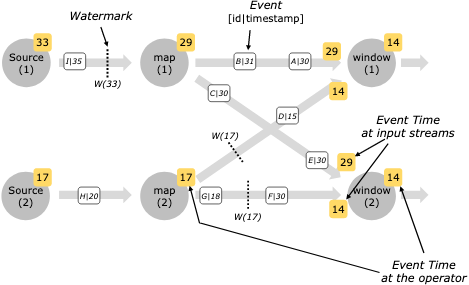
可以看到,这种分布式的水印速度更快,而且没有单点问题。
关于这个图你可能会提出疑问:水印不是保证只有超过水印时间戳的数据被处理吗?这里面不是有一个D:15么?它不是小于17吗?这是因为水印是不断推进的,这个17在数据发送之后得到。
以上是 《Streaming Systems》读书笔记(三):Watermark 的全部内容, 来源链接: utcz.com/a/26538.html