《Streaming Systems》读书笔记(二)
这个标题很亲切,让人想到了义务教育的英语老师,5个W法则(这里少了一个 Who️)……
在本章中主要是理解三个概念:Trigger,Watermark 和 Accumulation。这些概念的引入主要是和流处理的过程息息相关。首先以批处理为例:What 代表的是数据将得到什么样的结果,即 Transformation;Where 就是在 window上进行计算。现在有这样一个数据集:
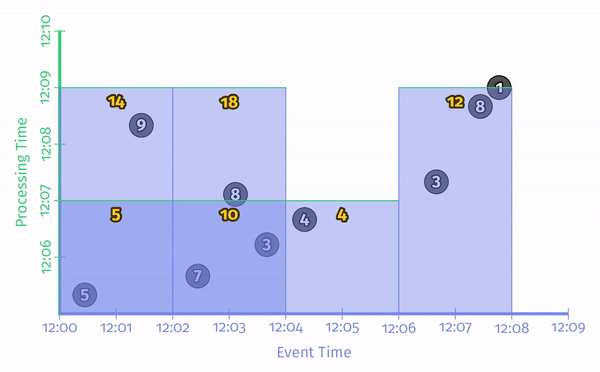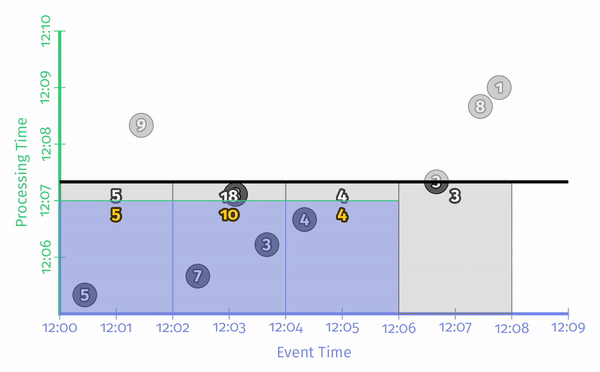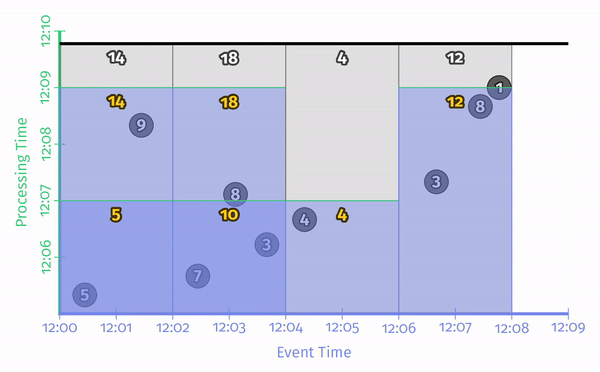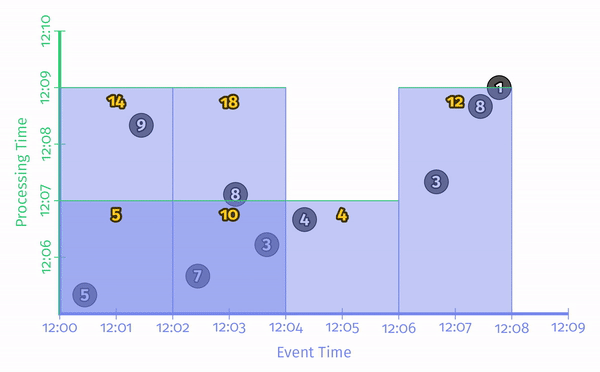
现在要对这个数据集的窗口进行求和(本书的一大特点就是使用了大量的动画,不过这只能在电子版看到了)。一个典型的批处理将等待数据到达后整体计算:

注意这里的合计数字并不重要,只有当颜色变成深色才代表进行一次计算。
一个批流融合的引擎在进行批处理时可以对事件时间进行分割从而得到不同的窗口:

Streamings: When and How
当数据是无界的,就需要考虑何时对数据进行计算。这将引入触发器(Trigger)——所谓触发器就是针对外部信号(比如 Watermark)如何触发窗口物化(materialized)的机制。按照本书所说,触发器类似于照相机的『快门』,决定了何时对窗口触发快照。这里分为两种触发器:
- 可重复更新触发器(Repeated update triggers)。
- 完整性触发器(Completeness triggers)。
名字比较晦涩,其实就对应了流处理和批处理的一般模式。第一个代表窗口将随着数据或者时间不断更新,第二个代表数据只会在整批到达后进行计算。我们在 Flink 中使用的触发器提供了onEventTime,onElement等钩子函数。
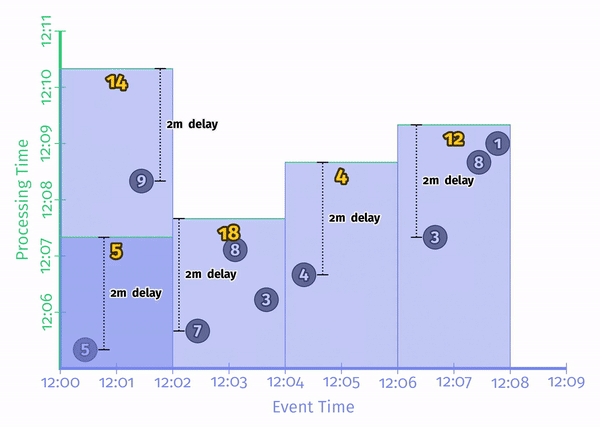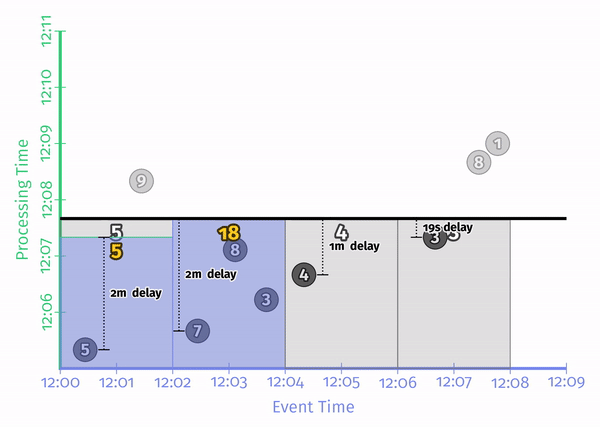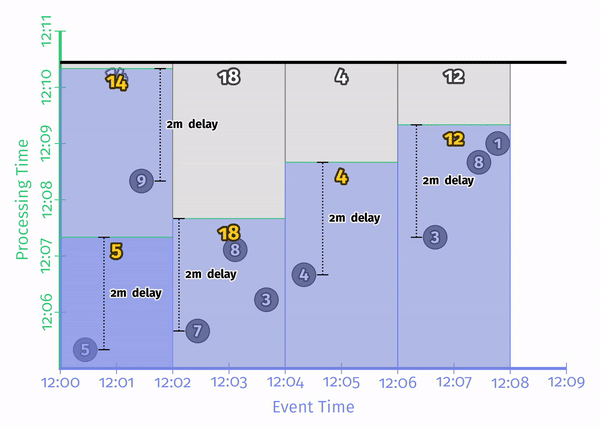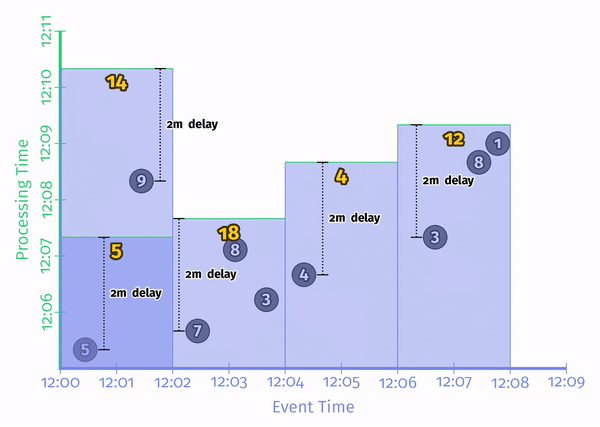
对于 Repeated update triggers,也有不同的做法。比如按照处理时间延迟(processing-time delays),或者按照每条数据进行触发(per-record triggering),典型是这样的:

对应 Flink 代码:
input.assignTimestampsAndWatermarks(newCustomTimeExtrator())
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.minutes(2)))
.sum(1)
在 Flink 中,每一种 Window 都有自己默认的 Trigger。这里TumblingEventTimeWindows默认是EventTimeTrigger,它将依据 Watermark 和窗口来判断每条记录是否触发计算。
它的缺点就是效率比较低(原文使用了chatty这个单词)。如果你只是想要一个不那么实时精确的结果,那么按照处理时间延迟是更好的选择。此外,定时触发还有一个好处,就是它可以平衡那些热点键(这里我没太看懂,应该指的是短期内某个窗口可能数据量额外的多,原文是it has an equalizing effect across high-volume keys or windows: the resulting stream ends up being more uniform cardinality-wise)。
按照处理时间延迟又可以分为两种:
- 对齐延迟(aligned delays)
- 非对齐延迟(unaligned delays)
注意这里事件时间不可能对齐。典型的对齐延迟就是 Spark Streaming 的微批处理:
它的缺点是负载集中于某一个时刻,可能需要比非对齐延迟更高的处理能力。
非对齐延迟针对已经观测到的数据的时间进行对比:
这里的时间都是处理时间。那么如何针对事件时间处理?解决方法即 Watermark。Watermark 可以分为两种:
- 完美型水印(Perfect watermarks)
- 启发式水印(Heuristic watermarks)
完美型水印是比较理想化的,意味着我们总是对数据的延迟有完全的了解。这里我觉得可能是 Flink 未来将和机器学习技术结合的重点——作者的意思是,我们可以依据数据的分布、增长情况等信息来推测这个水印。
Watermark 是一种推理完整性的工具。虽然本书对 Watermark 吹得神乎其神,实际上就现实中的应用而言大多非常朴素。Watermark 是一种效率与完整性的 tradeoff,太快会导致数据不准,太慢又不能满足需求。于是作者说,那我们就把他们融合在一起吧。
Early/On-Time/Late Triggers FTW
这个名字实际上代表三个部分:
- 可能有多个 early pane,意思是通过 repeated update trigger 先得到可观测的不断变化的结果。
- 一个 on-time pane,意思是 completeness/watermark trigger 得到的结果。
- 可能多个 late panes,也就是有(另)一个 repeated update trigger 不断处理延迟的数据。
说穿了,这个模式和 Lambda 架构很像,不过批处理换成了 Watermark。说实话感觉这个意义并不大(看了一下果然 Flink 曾经 16 年就有 PMC 提过相关的 PR,但是最后没有合进来),所以大家也就随便看看不要太当真。
When: Allowed Lateness
初学 Flink 的时候,有可能会对这个allowedLateness和 Watermark 比较迷惑。由于 Watermark 不完全可信,需要给迟到数据一个 deadline 来避免窗口无限制的扩张(所以其实是一个存储上的限制,如果我们有相对充分的存储,则不需要)。
根据获取数据的信息不同,水印通常有两种方式:低水印(获取事件时间最旧的数据)和高水印(获取最新的数据)。
How: Accumulation
最后就是关于如何计算数据,这个比较简单,一般就是丢弃(Discarding)、累积(Accumulating),还有一种比较特殊的是累积并撤回(Accumulating and retracting)。比如,计算窗口内的和就是一种丢弃,因为之前窗口的值没有意义。

这个图是基于前面的 Early/On-Time/Late Triggers。可以看到,每次触发窗口计算之后,比如 on-time trigger 后,数据都重新清0计算。对比一下这3种模式:
在 FLink 中,动态表可以被转换为一个 Retract stream,此时就可以控制对下游 sink 的写入(前提是下游对 Retract 支持,比如 Kafka 就无法这样做)。
以上是 《Streaming Systems》读书笔记(二) 的全部内容, 来源链接: utcz.com/a/23608.html