并发编程第六天----LongAdder源码深度解析
简介
AtomicLong 通过 CAS 提供了非阻塞的原子性操作,性能比使用同步锁好多了。但是在高并发情况下,大量线程争夺同一个原子变量,只有一个线程的 CAS 能操作成功,其他线程会不停地 CAS 自旋,极度浪费 CPU 资源。
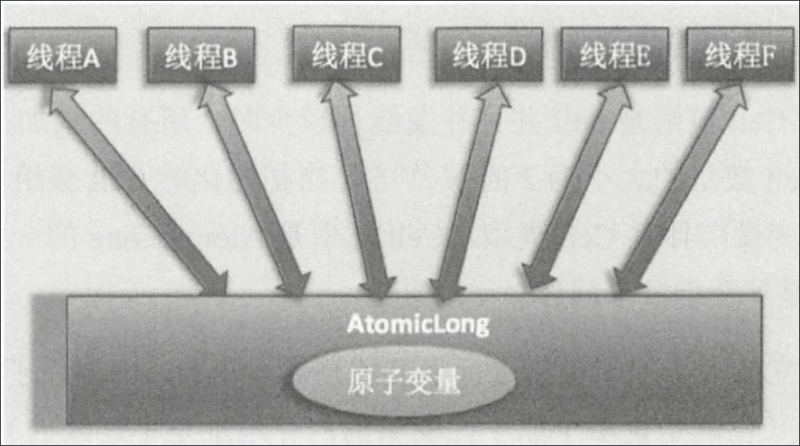
为了解决这个问题,JDK8 提供了一个类 LongAdder。把一个变量分成多个变量,让同样多的线程去竞争多个资源,就解决了性能问题。
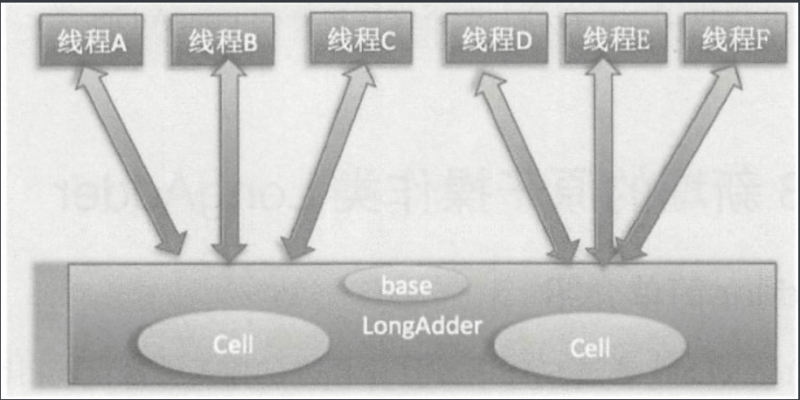
LongAdder 在内部维护了多个 Cell 原子变量,另外,多个线程在争夺同一个 Cell 原子变量时如果失败了,并不是在当前 Cell 变量上一直尝试,而是尝试对其他 Cell 变量进行 CAS 操作。最后,在获取 LongAdder 当前值时,是把所有 Cell 变量的 value 值累加后再加上 base 返回的。下面我们来看看 LongAdder 的使用及源码。
使用
publicclassLongAdderTest{static LongAdder longAdder = new LongAdder();
publicstaticvoidmain(String[] args)throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(()->{
for (int j = 0; j < 10; j++) {
longAdder.add(10);
}
}).start();
}
Thread.sleep(2000); // 保证前面的线程执行完
System.out.println(longAdder.sum());
}
}
毫无疑问,输出的结果肯定是 1000,LongAdder 是线程安全的。
源码分析
Striped64
LongAdder 是继承自 Striped64,我们来看看 Striped64 的主要成员变量。
abstractclassStriped64extendsNumber{// 大小是 2 的 n 次方
transientvolatile Cell[] cells;
// 基础值
transientvolatilelong base;
// 一个标识,状态只有 0 和 1,为 1 表示 cells 数组在初始化或者扩容
transientvolatileint cellsBusy;
@sun.misc.Contended staticfinalclassCell{
volatilelong value;
Cell(long x) { value = x; }
finalbooleancas(long cmp, long val){
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe 机制
privatestaticfinal sun.misc.Unsafe UNSAFE;
privatestaticfinallong valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
// 获取 Cell 实例中变量 value 的内存偏移量
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
thrownew Error(e);
}
}
}
// Unsafe 机制
privatestaticfinal sun.misc.Unsafe UNSAFE;
// 记录 Striped64 实例中变量 base 的偏移量
privatestaticfinallong BASE;
// 记录 Striped64 实例中变量 cellsBusy 的偏移量
privatestaticfinallong CELLSBUSY;
// 记录 Thread 实例中变量 threadLocalRandomProbe 的偏移量,用于计算访问下标
privatestaticfinallong PROBE;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> sk = Striped64.class;
BASE = UNSAFE.objectFieldOffset
(sk.getDeclaredField("base"));
CELLSBUSY = UNSAFE.objectFieldOffset
(sk.getDeclaredField("cellsBusy"));
Class<?> tk = Thread.class;
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
} catch (Exception e) {
thrownew Error(e);
}
}
}
Unsafe 机制现在应该非常熟悉了,就是用于获取变量在实例中的偏移量,用于 CAS 操作。
@sun.misc.Contended 可以解决伪共享问题,
Cell 内部有一个声明为 volatile 的变量,并通过 CAS 更新该值,保证了更新操作的原子性。Cell 是 AtomicLong 的优化。保证了线程操作 Cell 元素的原子性。
Cell 数组的大小一定为 2 的 n 次方。
threadLocalRandomProbe 用来计算当前线程访问 Cell 数组的下标。
cellsBusy 作为标识锁变量,状态只有 0 和 1 ,为 1 表示 Cell 数组正在初始化或者扩容,其他线程则不能进行初始化或者扩容。
LongAdder 源码分析
我们应该关注下面几个问题:
- 当前线程应该访问
Cell数组里的哪个元素。 - 如何初始化
Cell数组。 Cell数组何时扩容- 线程访问分配的
Cell元素有冲突时怎么办
sum()
publiclongsum(){Cell[] as = cells; Cell a;
long sum = base;
if (as != null) { // 如果 Cell 数组为空,则直接返回 base
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
累加所有 Cell 内部的 value 值,然后再累加上 base。由于没有对 Cell 数组进行加锁,所以在累加的过程中,可能有其他线程对 Cell 数组的内容进行了修改,返回的值可能不是很精确。
add()
publicvoidadd(long x){Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) { // ( 1 )
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 || // ( 2 )
(a = as[getProbe() & m]) == null || // ( 3 )
!(uncontended = a.cas(v = a.value, v + x))) // ( 4 )
longAccumulate(x, null, uncontended); // ( 5 )
}
}
( 1 ) 判断 cells 是否为 null,如果为 null,则直接在 base 上进行累加,此时类似 AtomicLong,如果 cells 不为 null 或者 CAS 操作失败,则进行下面的操作。刚开始并发线程较少时,所有的累加操作都是对 base 变量进行,当某个线程第一次 CAS 操作失败时,则进行初始化 Cell 数组。
( 2 ) 、 ( 3 ) 决定当前线程应该访问 Cell 数组里的哪个元素 (解决了问题 1 ) ,通过 getProbe() & m 计算的,getProbe 用于获取当前线程的 ThreadLocalRandomProbe 的值, m 是 Cell 数组的长度。如果访问的 Cell 数组元素为 null,则执行代码 ( 5 )。
如果该 Cell 元素存在则执行代码 ( 4 ),通过 CAS 更新 Cell 元素的 value 值,如果更新失败则执行代码
( 5 ),并且 uncontended 的值为 false。
longAccumulate()
longAccumulate 是涉及处理初始化、扩容、解决冲突的方法,在 Striped64 类中。我们能在里面找到问题 2 、 3 、 4 的答案。
int h; // 记录当前线程的 threadLocalRandomProbe 的值if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // 初始化当前线程的 threadLocalRandomProbe 的值
h = getProbe();
wasUncontended = true;
}
最开始是判断当前线程的 threadLocalRandomProbe 值是否为 0 ,为 0 则初始化 threadLocalRandomProbe。这个变量用于计算当前线程应该被分配到 Cell 数组的哪个下标。
boolean collide = false;for (;;) { // 无限循环
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
// cells 不为 null 时
...
}
// cells 为 null 则进行初始化
elseif (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
if (cells == as) {
Cell[] rs = new Cell[2]; // 初始化大小为2
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// 为了能找到一个空闲的 Cell,重新计算 hash 值
h = advanceProbe(h);
}
Cell 数组为 null 时,则进行初始化。
初始化时通过 casCellsBusy() 将 cellsBusy 的值设为 1,这时其他线程就不能进行扩容或者初始化了。
初始化 Cell 数组的大小为 2,并通过 h & 1 计算出当前线程访问的 Cell 元素,并进行赋值操作。(回答了问题 2 )
boolean collide = false; // 为 true 表示冲突for (;;) { // 无限循环
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) { // 当前线程访问的 cell 元素为 null
if (cellsBusy == 0) {
Cell r = new Cell(x); // 初始化 Cell 元素 (采用了延迟加载,用到时才初始化 Cell)
if (cellsBusy == 0 && casCellsBusy()) { // 获取锁变量
boolean created = false;
try {
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue;
}
}
collide = false;
}
elseif (!wasUncontended) // 之前 CAS 更新失败
wasUncontended = true;
// 当前线程访问的 Cell 元素存在了,则进行 CAS 加操作
elseif (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// NCPU 代表当前机器的 CPU 个数,Cell 数组的元素不能超过 NCPU
elseif (n >= NCPU || cells != as) ( 7 )
collide = false;
elseif (!collide) ( 8 )
collide = true;
// 扩容操作
elseif (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue;
}
// 为了能找到一个空闲的 Cell,重新计算 hash 值
h = advanceProbe(h); ( 9 )
}
}
( 7 ) 、 ( 8 ) 都不符合条件时,才会执行扩容操作。即:当前 Cell 数组的个数小于 CPU 的个数 并且 多个线程间发生了冲突。
( 7 ) 处表示只有当前 Cell 数组的长度小于 CPU 的个数,才能扩容。为什么要做这样的限制呢 :只有当每个 CPU 运行一个线程时才会使多线程的效果最佳,也就是当 Cell 数组元素的个数与 CPU 个数一致时,每个 Cell 元素都用一个 CPU 处理,效果最佳。
( 8 ) 表示多个线程访问了 Cell 数组中的同一个元素,或者多个线程尝试获取 cellsBusy 锁变量 导致了冲突。
扩容时先获取 cellsBusy 锁变量,然后大小扩充为原来的两倍再复制原来的变量到新数组。(解决了问题 3)。
( 9 ) 处对 CAS 失败的线程重新计算 threadLocalRandomProb , 减少冲突机会。(解决了问题 4)
总结
LongAccumulate() 源码表面复杂,但是只要围绕文章开头题的四个问题去看,也不是很难。
以上是 并发编程第六天----LongAdder源码深度解析 的全部内容, 来源链接: utcz.com/a/19215.html