Hadoop大数据路在何方?
近期Hadoop消息不断,众说纷纭。本文以Hadoop的盛衰变化为楔子聊下大数据分析的发展现状和未来趋势。
15秒钟简缩版:
Hadoop
- 巅峰已过,正在成为遗留系统
- Hadoop 和分布式数据库在同一个赛道上,Hadoop 在这个赛道上目前并无优势
大数据
- 大数据市场是 SQL市场,是分布式数据库市场
- 基础分析如BI、交互查询等技术已经成熟
- 高级分析(机器学习)下沉,向数据库内嵌分析方向发展
- 高级分析(机器学习)主要问题不在分析而在数据本身
1. Hadoop 巅峰已过几多年,正在成为遗留系统
自2015年开始 Hadoop 暴露出诸多问题引起注意。随后 Gartner、IDG 等公司分析师、Hadoop用户和Hadoop和大数据圈内人士越来越多的反映出各种问题。
究其原因,主要如下:
- Hadoop 栈过于复杂,组件众多,集成困难,玩转代价过高
- Hadoop 创新速度不够(或者说起点过低),且缺乏统一的理念和管控,使得其众多组件之间的集成非常复杂
- 受到 Cloud 技术的冲击,特别是类 S3 对象存储提供了比 HDFS 更廉价、更易用、更可伸缩的存储,撬动了 Hadoop 的根基 HDFS
- 对 Hadoop 期望过高,Hadoop 发迹于廉价存储和批处理,而人们期望 Hadoop 搞定大数据所有问题,期望不匹配造成满意度很低
- 人才昂贵,且人才匮乏
Hadoop 巅峰已过成为行业事实,本文不打算在这个问题上继续论证。有兴趣的读者可以参考网上的诸多评论,甄选了一些笔者觉得有参考价值或沾边的文章罗列如下(从标题可以感觉到浓厚的萧瑟之气):
- Hadoop还有没有前途?Hadoop发展历史和未来方向解读
- Hadoop 气数已尽:逃离复杂性,拥抱云计算
- 超越云计算:对数据库管理系统未来的思考
- Big Data Is Still Hard. Here’s Why
- Big Data Will Get By (but only with a little help from its friends)
- Cloudera and Hortonworks merger means Hadoop’s influence is declining
- From data ingestion to insight prediction: Google Cloud smart analytics accelerates your business transformation
- Hadoop is Dead. Long live Hadoop (中文翻译:Hadoop已死,Hadoop万岁)
- Hadoop Has Failed Us, Tech Experts Say
- Hadoop Past, Present, and Future
- Hadoop: Past, present and future(又一个)
- Hadoop runs out of gas
- Hadoop Struggles and BI Deals: What’s Going On?
- Hitting the Reset Button on Hadoop
- Is Hadoop officially dead
- Mike Olson on Zoo Animals, Object Stores, and the Future of Cloudera
- More turbulence is coming to the big-data analytics market in 2019
- Object and Scale-Out File Systems Fill Hadoop Storage Void
- The Decline of HADOOP and Ushering An Era of Cloud
- The elephant’s dilemma: What does the future of databases really look like?
- The Future of Database Management Systems is Cloud!
- The history of Hadoop
- Why is Hadoop dying?
Ok,如果你和我一样,把上面所有文章都读了一个遍,说明你确实对这个问题很感兴趣。发邮件给我(yyao@pivotal.io),请你喝酒细聊。
Hadoop 是否还能重振雄风?Hadoop 若要重回大数据的中心,需要的是信心和时间,然而现在 Hadoop 最缺的恰恰是信心和时间。业界已经给了 Hadoop 十多年的时间,不管什么原因,Hadoop 没有很好的解决大数据的问题,甚至没有很好的解决大数据的基本问题。人们很难相信再给它十年时间就可以搞定。随着问题暴露面越来越广,业界对 Hadoop 的信心逐渐大幅下滑。同样紧要的是,和十多年前没有选择不同,现在业界有多种大数据方案(特别是开源方案)可供选择。
然而这并不意味着 Hadoop 会消失,经过十多年的发展,现在全球部署有很多 Hadoop 集群,这些遗留资产及其衍生需求会持续相当一段时间。Hadoop 的根基 HDFS 受到对象存储挑战,在公有云上已经败下阵来,在企业内部暂时会保住守势,然而随着云厂商进入企业级市场,很快也会面临极大挑战。Hadoop 也在向对象存储发展,将来或许有望成为多种对象存储解决方案中的一个候选项,然而可以肯定的是Hadoop不再是讨论的中心。
HortonWorks 联合创始人、CPO,现任 Cloudera CPO Arun C Murthy 于2019年9月10日发文表示:
The old way of thinking about Hadoop is dead — done, and dusted. Hadoop as a philosophy to drive an ever-evolving ecosystem of open source technologies and open data standards that empower people to turn data into insights is alive and enduring.
(来自微信公众号的译文:你所认为的传统的Hadoop已经死了,确实如此。但Hadoop作为一门哲学,推动不断发展的开源技术生态系统和开放数据标准,使人们能够将数据转化为洞察力,这门哲学是充满活力和持久的。)
“形而上者谓之道,形而下者谓之器”。无器以为载体,则坐而论道。
2. Hadoop 市场是数据仓库市场,然而在这个市场里目前并不占优势
首先捋一下Hadoop 几个主要组件的发展脉络。
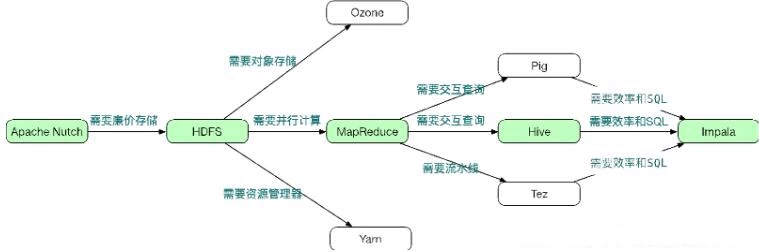
- Apache Nutch 是 Hadoop 一哥 Doug Cutting 写的开源网页爬虫。为了存储海量网页,Nutch 需要一个分布式存储层。受 Google GFS 论文的启发,Doug 设计了一个开源 GFS 实现,成为后来的 HDFS。相比于当时昂贵的磁盘阵列和 SAN,HDFS 提供了廉价、高可靠且可扩展的存储;
- 分布式存储层解决后,Nutch 需要能适应分布式环境的并行计算模型。受 Google MapReduce 论文的启发,Doug 设计了开源版的 MapReduce。HDFS 和 MapReduce 解决了大数据的存储和计算问题,受到当时受困于大数据问题的大型互联网公司的追捧,很快 Hadoop 吸引了大量的开发者,成为 Apache 顶级项目;
- Hadoop 解决了有无问题。很快人们发现 MapReduce 复杂度很高,即使技术实力强大如 Facebook 都很难写出高效正确的 MapReduce 程序。此外除了解决批处理问题,人们需要 Hadoop 能解决其遇到的交互式查询任务。为此,Facebook 开发了 Hive,该项目快速流行起来,到现在还有很多用户。Facebook 当时更是高达 95% 的用户使用 Hive 而不是裸写 MapReduce 程序。
- 由于 Hadoop 不是为交互式处理而设计,Hive 效率低,并发度也低。此外 Hive不支持标准 SQL,使得和其他产品的集成困难重重。为此 Cloudera 开发了 Impala。Impala 实际上是一款分布式 MPP(大规模并行处理) 数据库。
从上面的发展脉络可以清楚的看出,Hadoop 从分布式存储和并行计算模型开始,逐渐发展成了 MPP 数据库,而 MPP 数据库做为成熟数据仓库解决方案已经发展了三十多年。可见 Hadoop 市场主要是 SQL 市场。然而 Hadoop 和其他经典 MPP 数据库相比,从性能、SQL 兼容性、扩展性等各个方面来看,Hive、Impala 等并不占优势。Gartner 2019年发布的数据分析市场排名,Hadoop 三大发行商排名都在十名以外(前三名是 Teradata、Oracle和Greenplum)。

从市场角度也印证了这一说法:Cloudera 官方表示其收入的75%来自于 SQL 产品。最近(2019年9月4日)Cloudera 宣布收购AI驱动的云原生BI厂商 Arcadia Data,印证了 Hadoop 市场领头羊 Cloudera 发力的发展方向。上文中提到的 Cloudera CPO 也公开指出:“For several years now, Cloudera has stopped marketing itself as a Hadoop company, but instead as an enterprise data company.”
3. 大数据分析市场当前是 SQL 市场
大数据分析包括两个层面,第一个层面是基本分析,第二个层面是高级分析。
基本分析层面涉及的主要应用和场景为 BI、交互查询、可视化等场景。这些场景使用的主流核心技术是 SQL,BI 等产品的基本玩法是 SQL+图形用户界面(UI)。和此相关的主要SQL特性是分组(group by)和聚集(aggregation)、窗口(window)函数、数据立方格(Cube)等。这些SQL功能背后的主要计算基本都是小学数学中的加减乘除,看起来高大上的“大数据分析”大都是些小学数学的东西,当然对海量数据进行这些分组加减乘除且保证 ACID 特性是很有挑战性的。诸如 Greenplum、Vertica 之类的分布式 MPP 数据库已经很好的解决了这些问题。
高级分析层面涉及到诸如机器学习、模式识别、AI等复杂算法的采用。目前这一层面有下沉到数据库内部的趋势。Apache MADLib 是最早引领这一趋势的成熟商业产品。2017年谷歌发布了 BigQuery ML 亦是基于SQL的高级分析方案。对此感兴趣的请参见数据库内建分析介绍一文。
从大数据分析的两个层面来看,其核心均为 SQL。对更多这方面信息感兴趣,以及对数据处理平台演进历史和其原动力感兴趣的朋友,可参考Greenplum中文社区资料下载页面的《2.数据处理平台之演进》和《3.大数据≈分布式数据库》(
greenplum.cn/2019/06/17/…)。
4. 高级数据分析之难点不在分析而在数据本身
如果你有足够多整洁的数据,那么高级数据分析对你而言不是问题。
这里“足够多”不一定意味着PB级海量数据,仅指可以满足需求的数据量,不同场景需求不同,从MB到GB到PB级不等。高级数据分析不一定需要大数据,现在还广为使用的商业分析产品如 SAS、SPSS 都是单节点的,可处理数据量大不到那里去。
大量的研究也证明,即使所用算法不变,数据量越大,模型的精度也会更好,结果准确度也越好。因而尽量使用更多数据,使用全量数据而不是抽样成为提升精度的首要手段。
“整洁”意味着数据是标准的、准确的。然而现实却远非如此。不准确的数据会造成高级分析结果的严重偏差。
数据工程师和数据科学家面临着数据发现、数据集成和数据清洗等大量复杂问题。为了解决这些问题,数据科学家需要花费大量时间去整理数据而不是分析数据。大量报到表明,数据科学家花费至少70%以上的时间进行数据发现、集成和清洗工作。iRobot上一位数据科学家甚至表示:“我90%的时间用于发现和清洗数据,剩余10%时间中的90%用于纠正清洗过程中的错误”。这或许有些夸张,然而数据库科学家的主要工作内容可见一斑。如何提高数据工作者这方面的效率是目前国内外非常活跃的投资领域。
总结
综上,作为第一代大数据方案的Hadoop巅峰已过,大数据进入第二代:分布式数据库。
分布式数据库特别是 MPP 数据库已经很好的解决了大数据基本分析层面的问题,未来持续向着更易用更快的方向发展。
高级数据分析向着下沉到数据库内部的方向发展。高级数据分析层面的难点不在分析,而在于数据本身的数量和质量。期待这一方面有更多创新涌现。
以上是 Hadoop大数据路在何方? 的全部内容, 来源链接: utcz.com/a/19203.html