豆瓣电影top250用xpath爬取时遇到的一些问题
豆瓣电影top250的页面结构如图示

我现在想获取每个电影的电影名,也就是图中的span标签,代码如下
items = html.xpath('//ol/li/div[@class="item"]')for item in items:
name = ""
try:
name = item.xpath('//div[@class="info"]//div[@class="hd"]//a/span/text()')
print(name)
except Exception as e:
raise e
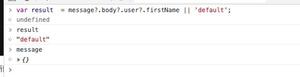
输出结果如下,反正就是把整个页面的电影名都放在一起了
''肖申克的救赎', '\xa0/\xa0The Shawshank Redemption', '\xa0/\xa0月黑高飞(港) / 刺激1995(台)', '这个杀手不太冷', '\xa0/\xa0Léon', '\xa0/\xa0杀手莱昂 / 终极追杀令(台)', '阿甘正传', '\xa0/\xa0Forrest Gump', '\xa0/\xa......但是我想要的结果是分开获取,得到下面这样的效果
意思就是下面这样的效果[
['肖申克的救赎', 'xa0/xa0The Shawshank Redemption', 'xa0/xa0月黑高飞(港) / 刺激1995(台)'],
['这个杀手不太冷', 'xa0/xa0Léon', 'xa0/xa0杀手莱昂 / 终极追杀令(台)'],
...
]
所以想问一下有什么办法?
-------------------------------------华丽分割线-----------------------------
-------------我已经找到解决办法了,但还是要谢谢大家了------------
其实修改办法很简单,是我自己对xpath用法不是很熟练,xpath用法中的反斜杠“/”我总是很混乱的用,看了网上的栗子明白了,修改之后结果得到了我想要的。代码如下
items = html.xpath('//ol/li/div[@class="item"]')for item in items:
name, info, star, quote = "", "", "", ""
try:
# 仅仅修改了这一行就行了,最前面加个点号,表示当前节点,反斜杠用一个就行了,用两个表示匹配所有的(虽然我知道,但还是乱用了。。。)
# 修改之前的代码
# name = item.xpath('//div[@class="info"]//div[@class="hd"]//a/span/text()')
name = item.xpath('./div[@class="info"]/div[@class="hd"]/a//span/text()')
print(name)
except Exception as e:
raise e
得到的结果如下

注:参考http://www.mobile-open.com/20...
回答:
虽然不对题。但是该偷得懒就得偷啊 https://api.douban.com/v2/mov...
这个top250有接口的
回答:
把try里改成这样:
name = item.xpath('//div[@class="info"]//div[@class="hd"]//a')for k in name:
#print(k.xpath("//span/text()"))
content = k.xpath("//span/text()")
for v in content:
print(v.encode('utf-8'))
print()
你要在Windows cmd上完全输出中文,可能有问题,因为一些字符在gbk里没有.可以写到文件里.
以上是 豆瓣电影top250用xpath爬取时遇到的一些问题 的全部内容, 来源链接: utcz.com/a/162118.html