pyquery爬虫图片无法保存
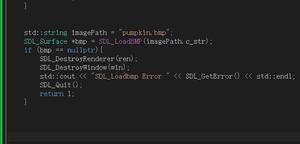
使用pyquery爬虫,使用urllib.request.urlretrieve保存图片时报错, HTTP Error 403: Forbidden,按照网上说的添加了headers 但运行仍然报错,另外hearder内容是怎么生成的啊,我是直接复制的
但运行仍然报错,另外hearder内容是怎么生成的啊,我是直接复制的
回答:
headers 是dict
例如
headers = {
'Accept':'*/*','Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'6',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
例子:
import requests
headers = {
'Accept':'image/webp,image/*,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Cache-Control':'no-cache',
'Host':'img1.mm131.me',
'Pragma':'no-cache',
'Referer':'http://www.mm131.com/xinggan/3627.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
r = requests.get('http://img1.mm131.me/pic/3627/1.jpg', headers=headers)
with open('1.jpg', 'wb') as w: #保存图片
w.write(r.content)
以上是 pyquery爬虫图片无法保存 的全部内容, 来源链接: utcz.com/a/162108.html