Hadoop入门MapRedu使用
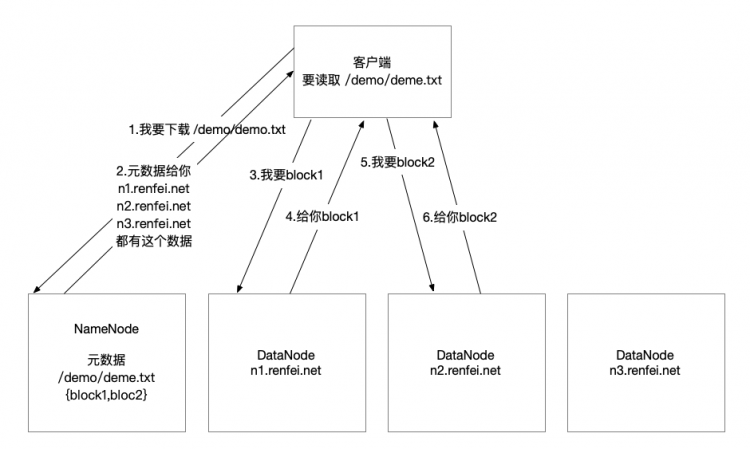
上一篇文章我们大致了解了什么是 MapReduce,这一节我们将使用代码编程的方式实现 WordCount 案例,体验一下 MapReduce 到底是怎么回事。本章的完整代码分享在:https://github.com/renfei/demo/blob/master/hadoop/hadoop_api/src/main/java/net/renfei/hadoop/WordCountMapReduce.java
Mapper类
先新建一个 Mapper 类,我这里叫 WordCountMapper,代码如下:
/** * Map(映射)
*/
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final Text word = new Text();
private final IntWritable intWritable = new IntWritable(1);
/**
* Mapper 的业务逻辑需要写在 map() 里,我们这里重写父类的 map()
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 拿到一行数据
String line = value.toString();
// 按照空格切分单词
String[] words = line.split(" ");
// 遍历单词
for (String word : words
) {
this.word.set(word);
// 把Map(映射)好的东西返回给框架
context.write(this.word, this.intWritable);
}
}
}
我们继承了 org.apache.hadoop.mapreduce.Mapper,传递了 4 个类型 <LongWritable, Text, Text, IntWritable>,分别代表 输入Key类型、输入Value类型、输出Key类型、输出Value类型,然后重写 map() 方法。
其中 LongWritable, Text, IntWritable 类型是 Hadoop 中的类型,其实跟 Java 是一样的后面加了个 Writable,Text 其实就是 String,你可以理解为包装类型。下一章我们就会讲这个 Writable。
map() 方法里面就是我们的主要业务逻辑。
Reducer类
新建一个 Reducer 类,我这里叫 WordCountReducer,代码如下:
/** * Reduce(归约)
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable total = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 遍历我们上面 Map(映射)出的 同 Key 的 Value
for (IntWritable value : values
) {
// 对 Value 求和
sum += value.get();
}
// 装箱包装一下
this.total.set(sum);
// 把 Reduce(归约)结果返回给框架
context.write(key, this.total);
}
}
代码的含义跟上面的 Mapper 一样,继承了 org.apache.hadoop.mapreduce.Reducer,传递 4 个类型,同样代表 输入Key类型、输入Value类型、输出Key类型、输出Value类型,然后重写 reduce() 方法。
reduce() 方法里面就是我们的主要业务逻辑。
驱动类
我们再新建一个类,来驱动我们的 Map 和 Reduce,我这里起名叫 WordCountMapReduce,并提供一个 main 入口,代码如下:
/** * 程序的入口
*
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
// 告知框架我们的类路径
job.setJarByClass(WordCountMapReduce.class);
// 告知框架mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 告知框架mapper和reducer的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 告知框架输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交job
boolean exc = job.waitForCompletion(true);
System.exit(exc ? 0 : 1);
}
本地运行代码
如果你还没配置搭建本地运行环境,请先阅读《Hadoop入门教程(九):本地搭建 Hadoop 开发环境》配置好环境变量。
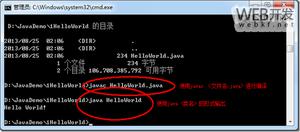
当你直接执行的时候,程序会报错,因为 main 参数数组越界了,我们没有提供两个参数,可以这样修改,如下图:
:编程的方式使用 MapRedu...")
打包到集群中运行
在 Maven 中执行 package 打包,你会得到一个 jar 包,如下:
:编程的方式使用 MapRedu...")
然后上传到集群里,执行:
hadoop jar hadoop-1.0.0.jar net.renfei.hadoop.WordCountMapReduce /demo/demo.txt /outdemo后面的参数分别是 jar包、类路径、输入文件、输出文件夹
以上是 Hadoop入门MapRedu使用 的全部内容, 来源链接: utcz.com/a/125952.html