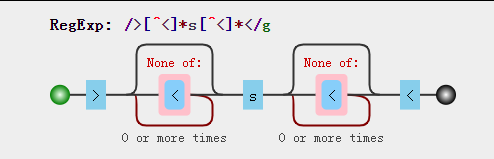
js正则匹配中文字符

我们知道用正则可以匹配的事物有很多,不论是生活上的,还是程序地址上的,都可以选择用正则来匹配。这里想讨论的是,正则对于中文字符的匹配,毕竟中文是我们每天随处可见的。这里我们先学正则的创建,然后讨论对于文字的匹配,最后为大家带来匹配中文字符的实例。
1.创建正则表达式
字面量创建方式
两个斜杆之间包起来的,都是用来描述规则的元字符
js;toolbar:false">let reg1 = /\d+/;
2.匹配所有统一表意文字
然而时光飞逝,Unicode 在2017年6月发布了10.0.0版本。在这20年间,Unicode 添加了许多汉字。比如 Unicode 8.0 添加的 109 号化学元素「鿏(⿰⻐麦)」,其码点是 9FCF,不在这个正则表达式范围中。而如果我们期望程序里的`/[\u4e00-\u9fa5]/`可以与时俱进匹配最新的 Unicode 标准,显然是不现实的事情。因此,我们需要换一个思路,写一个无需维护的正则表达式:
/\p{Unified_Ideograph}/u3.中文正则实例
//包含中文正则var cnPattern = /[\u4E00-\u9FA5]/;
//输出 true
console.log(cnPattern.test("蔡宝坚"));
以上就是js正则匹配中文字符的方法,相信经过创建正则表达式、对匹配文字的理论,最后简短的匹配代码部分已经很好理解了。
以上是 js正则匹配中文字符 的全部内容, 来源链接: utcz.com/z/542233.html
![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)