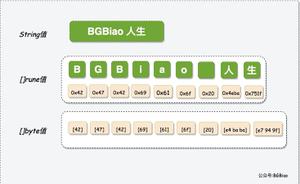
unicode与utf8的对比

UTF-8一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
以汉字“严”为例,演示如何实现UTF-8编码。
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
以上是 unicode与utf8的对比 的全部内容, 来源链接: utcz.com/z/540509.html