关于数据抓取很多新人的误区
![关于数据抓取很多新人的误区[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2432211050_1.jpg)
个人写博客习惯没什么理论偏向于实战
一.为什么我解析数据明明就是这个位置为什么拿不到
博问:https://q.cnblogs.com/q/132792/
错误寻找内容方法:
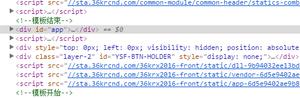
在Element中定位寻找到参数(很多页面能用但是会他并不是真正寻找数据的方法)
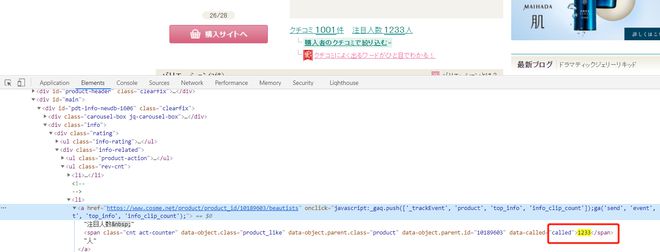
正确寻找内容方法:
我们应该在network页面response寻找我们需要找的内容
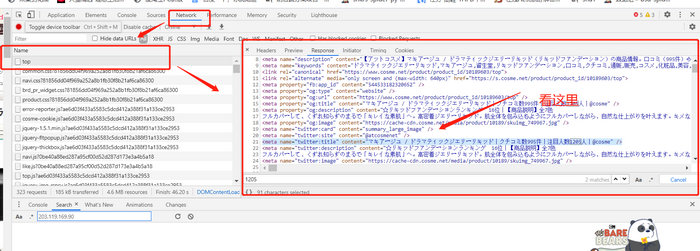
原因
Element中是最终渲染后的内容,不一定是我们get网页url拿到的数据,期间会有些js或者其他数据接口会改变他原始的界面
简单代码
import requestsfrom lxml.html import etree
url = "https://www.cosme.net/product/product_id/10189603/top"
res =requests.get(url) #为什么不加请求头呢,人家没校验请求头就不用加了,不过多进程多线程爬取时候请务必和真实请求一模一样
res_demo = etree.HTML(res.text)
meta_content = res_demo.xpath("//*[@property="og:title"]/@content")[0].split("|")[2]
print(meta_content)
二.抓不到包
情况一
证书位置本地校验
解决方法
adb命令将抓包工具证书从用户目录移动至系统目录,解决反爬对于本地证书认证(点击跳转)
情况二
对于抓包工具的监测
解决方法
如果是页面:使用network界面抓取
如果是app:python爬虫用drony转发进行抓包转发(点击跳转),ProxyDroid+wifi设置抓xx点评抓不到的包(点击跳转)
情况三
对于协议进行判断
解决方法
VirtualXposed结合justTrustMe 模块傻瓜式破解app没法抓包问题(点击跳转)
情况四
证书双向认证
解决方法
找到app中证书所在的位置,或者查看他的校验规则
三.关于乱码
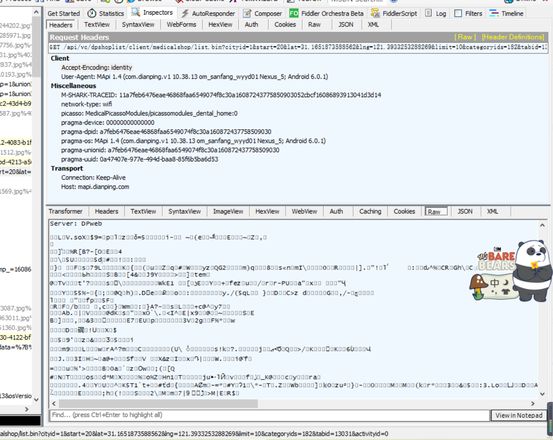
原因:人家是用二进制进行传输常见的是用谷歌传输协议进行传输,大公司可能会自己写一套算法进行加密解析
python谷歌序列化传输(点击跳转)
四.关于加密(如今比较常见的加密)
RSA加密
我们解析页面或者app反编译后找他公钥的时候找不到他公钥,这时候他加密可能就是通过模和指数进行加密的
AES加密
关于ASE加密有填充和无填充的识别方法
其实很简单加密通一条加密数据连续2次加密加密内容,key,iv不变的情况,最后输出参数不变就是无填充.变就是填充
加密模板
直接拿取用就好了(python模板)(点击跳转)
五.关于app逆向
难点:工具的使用,寻找加密的经验少,C和java要会,so层要用到汇编调试,脱壳,所有呢同学们先打好基础
hook工具推荐:
frida:容易学,缺点语言比较弱有些位置没法进行hook
yafha:不容易学,相比与frida语言要强有些位置frida没法hook可以用yafha
目前都在卡人数网上的资料不会很多,如果真的要学推荐去看雪论坛或吾爱破解学习
也可以在我博客上看,但是细节方面也没写的很到位,个人只用于自己使用
学习链接:python爬虫(学习整理)(点击跳转)
以上是 关于数据抓取很多新人的误区 的全部内容, 来源链接: utcz.com/z/537754.html