java抓取网页数据获取网页中所有的链接实例分享
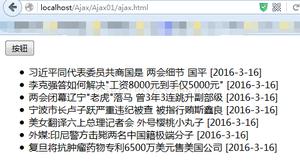
效果图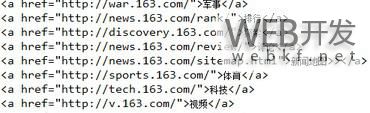
public class HtmlParser { /** * 要分析的网页 */ String htmlUrl;
/** * 分析结果 */ ArrayList<String> hrefList = new ArrayList();
/** * 网页编码方式 */ String charSet;
public HtmlParser(String htmlUrl) { // TODO 自动生成的构造函数存根 this.htmlUrl = htmlUrl; }
/** * 获取分析结果 * * @throws IOException */ public ArrayList<String> getHrefList() throws IOException {
parser(); return hrefList; }
/** * 解析网页链接 * * @return * @throws IOException */ private void parser() throws IOException { URL url = new URL(htmlUrl); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setDoOutput(true);
String contenttype = connection.getContentType(); charSet = getCharset(contenttype);
InputStreamReader isr = new InputStreamReader( connection.getInputStream(), charSet); BufferedReader br = new BufferedReader(isr);
String str = null, rs = null; while ((str = br.readLine()) != null) { rs = getHref(str);
if (rs != null) hrefList.add(rs); }
}
/** * 获取网页编码方式 * * @param str */ private String getCharset(String str) { Pattern pattern = Pattern.compile("charset=.*"); Matcher matcher = pattern.matcher(str); if (matcher.find()) return matcher.group(0).split("charset=")[1]; return null; }
/** * 从一行字符串中读取链接 * * @return */ private String getHref(String str) { Pattern pattern = Pattern.compile("<a href=.*</a>"); Matcher matcher = pattern.matcher(str); if (matcher.find()) return matcher.group(0); return null; }
public static void main(String[] arg) throws IOException { HtmlParser a = new HtmlParser("http://news.163.com/"); ArrayList<String> hrefList = a.getHrefList(); for (int i = 0; i < hrefList.size(); i++) System.out.println(hrefList.get(i));
}
}
以上是 java抓取网页数据获取网页中所有的链接实例分享 的全部内容, 来源链接: utcz.com/p/207625.html