
Python爬虫实战详解:爬取图片之家
![Python爬虫实战详解:爬取图片之家[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2785211352_1.jpg)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
如何使用python去实现一个爬虫?
- 模拟浏览器
请求并获取网站数据
在原始数据中提取我们想要的数据 数据筛选
将筛选完成的数据做保存
完成一个爬虫需要哪些工具
- Python3.6
- pycharm 专业版
目标网站
图片之家
https://www.tupianzj.com/
爬虫代码
导入工具
python 自带的标准库
import ssl系统库 自动创建保存文件夹
import os下载包
import urllib.request网络库 第三方包
import requests网页选择器
from bs4 import BeautifulSoup
默认请求https网站不需要证书认证
ssl._create_default_https_context = ssl._create_unverified_context
模拟浏览器
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",}
自动创建文件夹
ifnot os.path.exists("./插画素材/"):os.mkdir(
"./插画素材/")else:pass
请求操作
url = "https://www.tupianzj.com/meinv/mm/meizitu/"html
= requests.get(url, headers=headers).text
对页面原始数据做数据提取
soup = BeautifulSoup(html, "lxml")images_data
= soup.find("ul", class_="d1 ico3").find_all_next("li")for image in images_data:image_url
= image.find_all("img")for _ in image_url:print(_["src"], _["alt"])
下载
try:urllib.request.urlretrieve(_[
"src"], "./插画素材/" + _["alt"] + ".jpg")except:pass
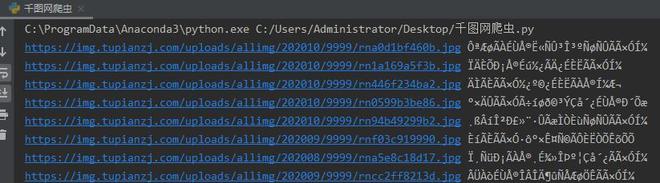
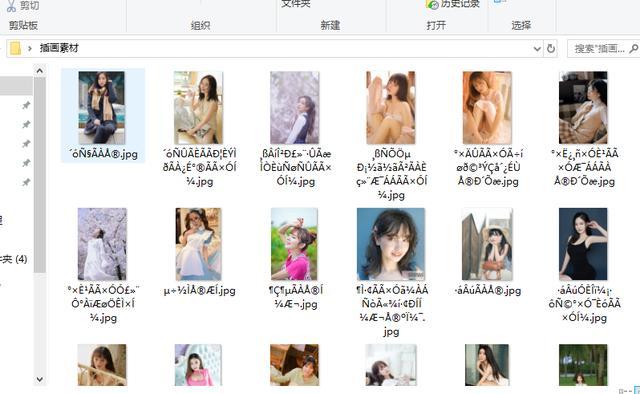
效果图


以上是 Python爬虫实战详解:爬取图片之家 的全部内容, 来源链接: utcz.com/z/537695.html




