
Python爬虫爬取搜狐证券股票数据
![Python爬虫爬取搜狐证券股票数据[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/3146211702_1.jpg)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于IT信息教室,作者:M先森看世界

数据的爬取
我们以上证50的股票为例,首先需要找到一个网站包含这五十只股票的股票代码,例如这里我们使用搜狐证券提供的列表。
https://q.stock.sohu.com/cn/bk_4272.shtml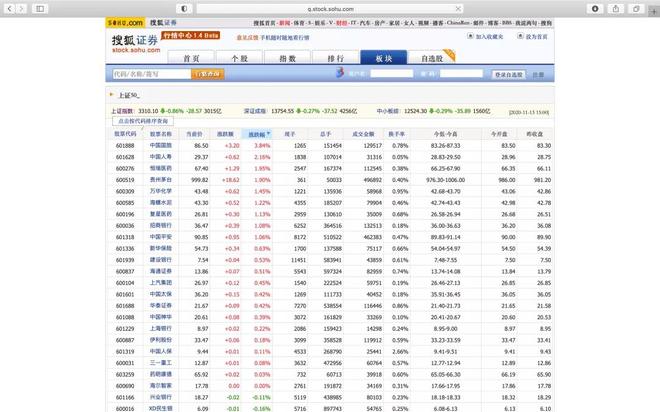
可以看到,在这个网站中有上证50的所有股票代码,我们希望爬取的就是这个包含股票代码的表,并获取这个表的第一列。
爬取网站的数据我们使用 Beautiful Soup 这个工具包,需要注意的是,一般只能爬取到静态网页中的信息。
简单来说,Beautiful Soup 是 Python 的一个库,最主要的功能是从网页抓取数据。
像往常一样,使用这个库之前,我们需要先导入该库 bs4。除此之外,我们还需要使用 requests 这个工具获取网站信息,因此导入这两个库:
import bs4 as bsimport requests
我们定义一个函数 saveSS50Tickers() 来实现上证50股票代码的获取,获取的数据来自于搜狐证券的网页,使用 get() 方法获取给定静态网页的数据。
python">def saveSS50Tickers(): resp = requests.get("https://q.stock.sohu.com/cn/bk_4272.shtml")
接下来我们打开搜狐证券的这个网址,在页面任意位置右键选择 查看元素,或者 Inspect Element,或者类似的选项来查看当前网站的源代码信息。
我们需要先在这里找出网页的一些基本信息和我们需要爬取的数据的特征。
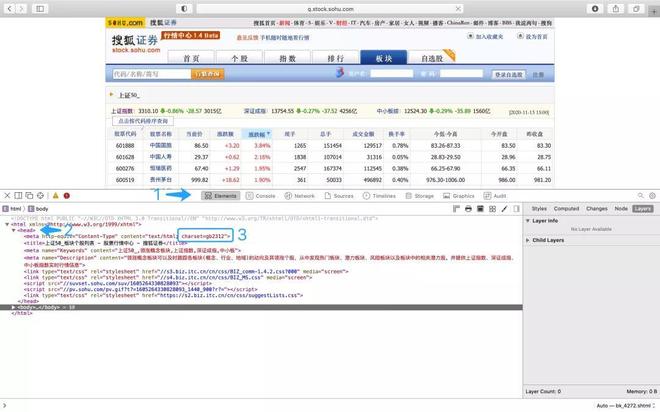
首先,找到 Element,在下面的内容中找到网页的 头文件 (head)。然后找到网页的 文字的编码方式。这里这个网页文字的编码方式是 gb2312。
如果我们想爬取并正确显示这个网页上,就需要先对获取到的网页内容解码。
解码可以使用 encoding 这个方法:
resp.encoding = "gb2312"接下来使用 BeautifulSoup 和 lxml 解析网页信息:
soup = bs.BeautifulSoup(resp.text, "lxml")这里为了方便后期的处理,首先使用 resp.text 将网页信息转成了文本格式,然后再解析网页的数据。
接下来我们需要在网页的源码中找到需要爬取信息的标签,这里我们需要爬取这个表格中的信息,首先,可以通过网站源码的搜索功能搜索表格里的相关数据定位到表格的源码。
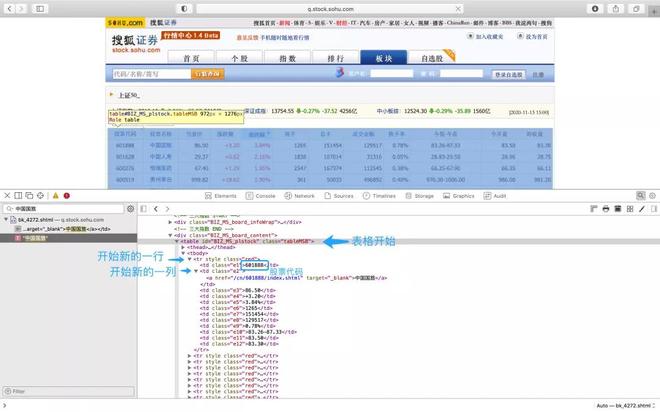
同样以这个页面为例,一般网页使用 HTML 语言编译的,因为要准确定位,我们需要了解一些 HTML 语言的基础内容。在这个页面的源码中,
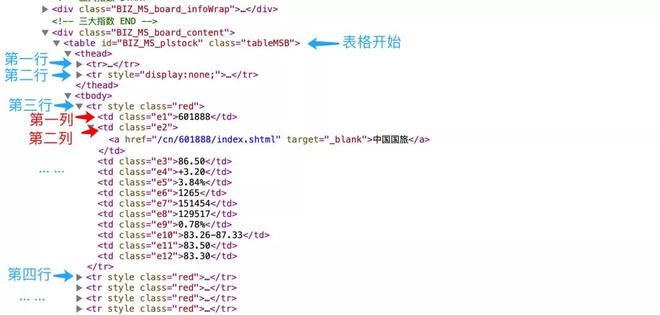
<table 表示表格开始,后面是这个表格的一些属性。</table> 表示表格结束。
首先,我们使用 soup.find 在网页信息中找到这个表格标签的入口:
table = soup.find("table", {"id": "BIZ_MS_plstock"})其中 "table" 表示这里需要找到一个表格,{"id": "BIZ_MS_plstock"} 则是通过内容或者属性实现表格的进一步定位。
找到表格的位置之后,我们需要继续查找需要的数据,同样以这个页面为例:
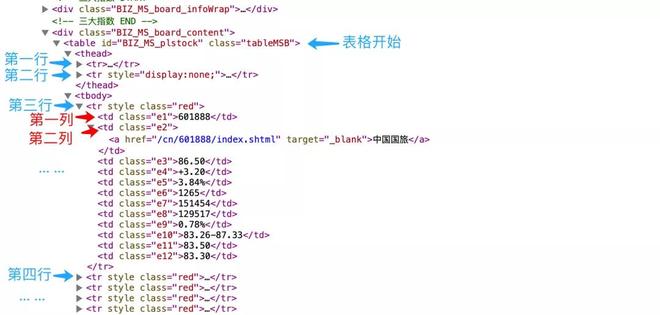
在网页开发语言中,
<tr 表示表格中开始新的一行,<td 表示在这一行中又新建了一列,而 </td> 则表示这一列结束了,对应的 </tr> 则表示这一行结束了。
通过该网页的源码,我们可以发现,
表格的第一行和第二行都是表头的信息,第三行开始是五十家公司的股票信息。另外每家公司的股票代码在表格的第一列位置。
因为,在Python中,我们需要从表格的第三行开始抓取,每行抓取表格的第一列的数据,将抓取到的数据转换成文本格式,我们用一个列表 tickers 来存储抓取到的数据:
tickers = []for row in table.findAll("tr")[2:]:
ticker = row.findAll("td")[0].text
tickers.append(ticker + ".SS")
因此为了方便后续进行数据处理,这里我们存储上证50的每家公司的股票代码时,都在代码后面再添加 ".SS" 的字符。这时我们运行目前的代码,并将列表 tickers 输出:
# 导入 beautiful soup4 包,用于抓取网页信息
import bs4 as bs
# 导入 pickle 用于序列化对象
import pickle
# 导入 request 用于获取网站上的源码
import requests
def saveSS50Tickers():
resp = requests.get("https://q.stock.sohu.com/cn/bk_4272.shtml")
resp.encoding = "gb2312"
soup = bs.BeautifulSoup(resp.text, "lxml")
# print(soup)
table = soup.find("table", {"id": "BIZ_MS_plstock"})
# print(table)
tickers = []
# print(table.find_all("tr"))
for row in table.findAll("tr")[2:]:
# print(row)
ticker = row.findAll("td")[0].text
tickers.append(ticker + ".SS")
return tickers
tickers = saveSS50Tickers()
print(tickers)
观察到输出信息如下:
["600036.SS", "601229.SS", "600031.SS", "601166.SS", "600104.SS", "600030.SS", "603259.SS", "601668.SS", "601628.SS", "601766.SS", "601857.SS", "601398.SS", "601390.SS", "600029.SS", "600028.SS", "601818.SS", "601211.SS", "601066.SS", "601111.SS", "600837.SS", "600887.SS", "601888.SS", "600690.SS", "600519.SS", "600016.SS", "601989.SS", "601988.SS", "601601.SS", "600019.SS", "601186.SS", "600703.SS", "600196.SS", "601318.SS", "601800.SS", "600050.SS", "601319.SS", "601288.SS", "601688.SS", "603993.SS", "600309.SS", "600048.SS", "600276.SS", "601138.SS", "601336.SS", "601088.SS", "600585.SS", "600000.SS", "601328.SS", "601939.SS", "600340.SS"]这样我们就从搜狐证券这个网站上爬取到了上证50的公司股票代码,并将其以字符串的格式存放在了一个列表变量中。
将股票代码保存到本地
一般像股票代码这种内容,短时间内不会有很大的变动,所以我们也不需要每次使用时重新爬取,一种方便的做法是可以将股票代码信息以文件的格式保存到本地,需要使用时直接从本地读取就可以了。
这里我们将股票代码数据保存为 pickle 格式。pickle 格式的数据可以在 Python 中高效的存取,当然,将文件导出成该格式前需要先导入相应的pickle 库:
import picklepickle可以保存任何数据格式的数据,在经常存取的场景(保存和恢复状态)下读取更加高效。
把文件导出成 pickle 格式的方法是 pickle.dump,同时需要结合文件读写操作:
with open("SS50tickers.pickle", "wb") as f: pickle.dump(tickers, f)这里的 "SS50tickers.pickle" 就是保存的文件的名称,"wb" 则表示向文件中写入数据。pickle.dump(tickers, f) 表示将列表 tickers 写入到文件中。
以上是 Python爬虫爬取搜狐证券股票数据 的全部内容, 来源链接: utcz.com/z/537639.html



