大数据Hadoop生态系统介绍

目录
- 一、概述
- 1)Hadoop发行版本
- 1、Apache Hadoop发行版
- 2、DKhadoop发行版
- 3、Cloudera发行版
- 4、Hortonworks发行版
- 5、华为hadoop发行版
- 2)Hadoop1.x -》 Hadoop2.x的演变
- 3)Hadoop2.x与Hadoop3.x区别对比
- 1)Hadoop发行版本
- 二、Hadoop的发展简史
- 三、Hadoop生态系统
一、概述
Hadoop是Apache软件基金会下一个开源分布式计算平台,以hdfs(Hadoop Distributed File System)、MapReduce(Hadoop2.0加入了YARN,Yarn是资源调度框架,能够细粒度的管理和调度任务,还能够支持其他的计算框架,比如spark)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。hdfs的高容错性、高伸缩性、高效性等优点让用户可以将Hadoop部署在低廉的硬件上,形成分布式系统。目前最新版本已经是3.x了,官方文档
1)Hadoop发行版本
1、Apache Hadoop发行版
官方地址:https://hadoop.apache.org
Apache版本最原始(最基础)的版本,对于入门学习最好。
2、DKhadoop发行版
Github地址:https://github.com/dkhadoop/dk-fitting
有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
3、Cloudera发行版
官方地址:https://www.cloudera.com/products/open-source/apache-hadoop.html
CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。
4、Hortonworks发行版
官方地址:https://www.cloudera.com/products/hdp.html
Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
5、华为hadoop发行版
华为FusionInsight大数据平台是集Hadoop生态发行版、大规模并行处理数据库、大数据云服务于一体的融合数据处理与服务平台,拥有端到端全生命周期的解决方案能力。除了提供包括批处理、内存计算、流计算和MPPDB在内的全方位数据处理能力外,还提供数据分析挖掘平台、数据服务平台,帮助用户实现从数据到知识,从知识到智慧的转换,进而帮助用户从海量数据中挖掘数据价值。
2)Hadoop1.x -》 Hadoop2.x的演变
3)Hadoop2.x与Hadoop3.x区别对比
License
- Hadoop 2.x - Apache 2.0,开源
- Hadoop 3.x - Apache 2.0,开源
支持的最低Java版本
- Hadoop 2.x - java的最低支持版本是java 7
- Hadoop 3.x - java的最低支持版本是java 8
容错
- Hadoop 2.x - 可以通过复制(浪费空间)来处理容错。
- Hadoop 3.x - 可以通过Erasure编码处理容错。
数据平衡
- Hadoop 2.x - 对于数据,平衡使用HDFS平衡器。
- Hadoop 3.x - 对于数据,平衡使用Intra-data节点平衡器,该平衡器通过HDFS磁盘平衡器CLI调用。
存储Scheme
- Hadoop 2.x - 使用3X副本Scheme。
- Hadoop 3.x - 支持HDFS中的擦除编码。
存储开销
- Hadoop 2.x - HDFS在存储空间中有200%的开销。
- Hadoop 3.x - 存储开销仅为50%。
存储开销示例
Hadoop 2.x - 如果有6个块,那么由于副本方案(Scheme),将有18个块占用空间。
Hadoop 3.x - 如果有6个块,那么将有9个块占用6块空间,3个用于奇偶校验。
YARN时间线服务
- Hadoop 2.x - 使用具有可伸缩性问题的旧时间轴服务。
- Hadoop 3.x - 改进时间线服务v2并提高时间线服务的可扩展性和可靠性。
默认端口范围
- Hadoop 2.x - 在Hadoop 2.0中,一些默认端口是Linux临时端口范围。所以在启动时,他们将无法绑定。
- Hadoop 3.x - 但是在Hadoop 3.0中,这些端口已经移出了短暂的范围。
工具
- Hadoop 2.x - 使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。
- Hadoop 3.x - 可以使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。
兼容的文件系统
- Hadoop 2.x - HDFS(默认FS),FTP文件系统:它将所有数据存储在可远程访问的FTP服务器上。 Amazon S3(简单存储服务)文件系统Windows Azure存储Blob(WASB)文件系统。
- Hadoop 3.x - 它支持所有前面以及Microsoft Azure Data Lake文件系统。
Datanode资源
- Hadoop 2.x - Datanode资源不专用于MapReduce,我们可以将它用于其他应用程序。
- Hadoop 3.x - 此处数据节点资源也可用于其他应用程序。
MR API兼容性
- Hadoop 2.x - 与Hadoop 1.x程序兼容的MR API,可在Hadoop 2.X上执行。
- Hadoop 3.x - 此处,MR API与运行Hadoop 1.x程序兼容,以便在Hadoop 3.X上执行。
支持Microsoft Windows
- Hadoop 2.x - 它可以部署在Windows上。
- Hadoop 3.x - 它也支持Microsoft Windows。
插槽/容器
- Hadoop 2.x - Hadoop 1适用于插槽的概念,但Hadoop 2.X适用于容器的概念。通过容器,我们可以运行通用任务。
- Hadoop 3.x - 它也适用于容器的概念。
单点故障
- Hadoop 2.x - 具有SPOF的功能,因此只要Namenode失败,它就会自动恢复。
- Hadoop 3.x - 具有SPOF的功能,因此只要Namenode失败,它就会自动恢复,无需人工干预就可以克服它。
HDFS联盟
- Hadoop 2.x - 在Hadoop 1.0中,只有一个NameNode来管理所有Namespace,但在Hadoop 2.0中,多个NameNode用于多个Namespace。
- Hadoop 3.x - Hadoop 3.x还有多个名称空间用于多个名称空间。
可扩展性
- Hadoop 2.x - 我们可以扩展到每个群集10,000个节点。
- Hadoop 3.x - 更好的可扩展性。 我们可以为每个群集扩展超过10,000个节点。
访问数据
- Hadoop 2.x - 由于数据节点缓存,我们可以快速访问数据。
- Hadoop 3.x - 这里也通过Datanode缓存我们可以快速访问数据。
HDFS快照
- Hadoop 2.x - Hadoop 2增加了对快照的支持。 它为用户错误提供灾难恢复和保护。
- Hadoop 3.x - Hadoop 2也支持快照功能。
平台
- Hadoop 2.x - 可以作为各种数据分析的平台,可以运行事件处理,流媒体和实时操作。
- Hadoop 3.x - 这里也可以在YARN的顶部运行事件处理,流媒体和实时操作。
群集资源管理
- Hadoop 2.x - 对于群集资源管理,它使用YARN。 它提高了可扩展性,高可用性,多租户。
- Hadoop 3.x - 对于集群,资源管理使用具有所有功能的YARN。
二、Hadoop的发展简史
Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。Hadoop源自始于2002年的Apache Nutch项目——一个开源的网络搜索引擎并且也是Lucene项目的一部分。
在2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身。
2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想。
2005年,Nutch开源实现了谷歌的MapReduce。
到了2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎。
2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用。
2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒。
在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准。
三、Hadoop生态系统
- HDFS——Hadoop分布式文件系统,GFS的Java开源实现,运行于大型商用机器集群,可实现分布式存储。
- MapReduce——一种并行计算框架,Google MapReduce模型的Java开源实现,基于其写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理T级别及以上的数据集。(第一代的计算框架,自身存在一些弊端,所以导致企业里已经很少使用了)。
- Yarn——Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
- Spark——Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷。使用场景如下:
复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
- Storm——Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。如今已被Flink替代。
- Flink——Apache Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。由于流处理和批处理所提供的SLA(服务等级协议)是完全不相同, 流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。
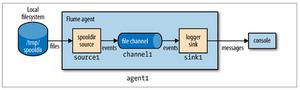
- Flume——一个可用的、可靠的、分布式的海量日志采集、聚合和传输系统。
- Hive——是为提供简单的数据操作而设计的分布式数据仓库,它提供了简单的类似
SQL语法的HiveQL语言进行数据查询。
- Zookeeper——分布式协调系统,Google Chubby的Java开源实现,是高可用的和可靠的分布式协同(coordination)系统,提供分布式锁之类的基本服务,用于构建分布式应用。
- Hbase——基于Hadoop的分布式数据库,Google BigTable的开源实现 是一个有
序、稀疏、多维度的映射表,有良好的伸缩性和高可用性,用来将数据存储到各个计算节点上。
- Cloudbase——基于Hadoop的数据仓库,支持标准的SQL语法进行数据查询。
- Pig——大数据流处理系统,建立于Hadoop之上为并行计算环境提供了一套数据工
作流语言和执行框架。
- Mahout——基于HadoopMapReduce的大规模数据挖掘与机器学习算法库。
- Oozie——MapReduce工作流管理系统。
- Sqoop——数据转移系统,是一个用来将Hadoop和关系型数据库中的数据相互转
移的工具,可以将一个关系型数据库中的数据导入Hadoop的HDFS中,也可以将HDFS
的数据导入关系型数据库中。
- Scribe——Facebook开源的日志收集聚合框架系统。
这里只是列举了一部分Hadoop生态里的组件,稍微介绍了一下,上面提到的目前企业里最常见的组件的原理介绍,安装部署,以及企业级使用会在后续分享出来,请耐心等待……
以上是 大数据Hadoop生态系统介绍 的全部内容, 来源链接: utcz.com/z/536397.html