慢SQL治理方法论

本文介绍了笔者实际工作中慢SQL治理的方法论,1、发现:如何发现慢SQL。2、定位:如何定位到慢SQL写在哪。3、分析:遇到慢SQL时的分析思路。4、解决:慢SQL的解决思路。
@
目录- 一、背景
- 二、发现
- 三、定位
- 四、分析
- 4.1 索引层面分析
- 4.2 业务层面分析
- 五、解决
- 5.1 SQL优化
- 5.1.1索引优化
- 5.1.2 子查询优化
- 5.1.3 分页优化
- 5.1.4 Using filesort文件排序优化
- 解决
- 5.2 业务改造
- 5.2.1 总量显示优化
- 5.2.1 关联表优化
- 5.3 减少数据
- 5.1 SQL优化
- 总结
一、背景
从业务的角度来看:慢SQL会导致产品用户体验差,会减低用户对产品的好感度。
从数据库的角度来看:慢SQL会影响数据库的性能,每个SQL执行都需要消耗一定的I/O资源。假设总资源是100,有一条慢SQL占用了30的资源共计1分钟。那么在这1分钟时间内,其他SQL能够分配的资源总量就是70,如此循环,当资源分配完的时候,所有新的SQL执行将会排队等待。
二、发现
在治理慢SQL前我们需要知道哪些SQL是慢SQL,即明确治理的对象。MySQL本身提供了慢查询日志,当SQL耗时超过指定阈值的时候,会将SQL记录到慢查询日志文件中,用户能够从慢查询日志文件中提取出慢SQL。
MySQL是可以动态开启慢查询日志,即线上的服务器没有开启慢日志,重启后会失效。为防止线上业务受影响,可以先这样修改,同时将my.cnf配置文件补上配置项即可。
查看配置
- slow_query_log 是否启用慢查询日志
- long_query_time 慢查询阈值
- slow_query_log_file 慢查询日志文件slow.log位置
show VARIABLES like "%query%";开启慢查询日志
MySQL数据库默认不启动慢查询日志,需要手动设置,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响
# 开启慢查询日志set global slow_query_log=ON;
# 慢查询阈值
set global long_query_time=1;
# 慢查询日志文件
set global slow_query_log_file=/tmp/mysql_slow.log
三、定位
我们通过慢查询日志提取出慢SQL,将这些慢SQL按不同的应用进行区分并整理一份文档,再定位到对应应用的代码,在文档中记录慢SQL应用在什么业务中,运行在什么场景中(定时任务、在线实时查询等)。
四、分析
接下来是根据整理的文档,对这些慢SQL做一些分析,找出慢SQL产生的原因。
4.1 索引层面分析
使用explain命令输出SQL的执行计划,透过执行计划我们可以了解慢SQL的执行细节。
Mysql中的执行计划各列说明。
- id: 按照sql语法解析后分层后的编号
- type:执行计划中指定表使用的访问路径方式。
这是个非常重要的字段,也是我们判断一个SQL执行效率的主要依据(以下只列举常见的几种)。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
- system:从系统表读一行。这是const联接类型的一个特例。
- const:表最多有一个匹配行,它将在查询开始时被读取。const用于常数值比较PRIMARY KEY或UNIQUE索引的所有部分
- eq_ref:它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
- ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
- ref是我们日常开发中较为常见的情况,也是原则上期望要达到的级别,查询命中到索引。
- range:索引范围扫描
- index:只扫描索引树,不需要回表查询。在这种情况下,explain 的 Extra 列的结果是 Using index
- all:全表扫描。
- possible_keys:查找表中的行时可选择的索引。
- key:显示MySQL实际决定使用的索引。
- key_len:显示MySQL使用索引键的长度,就是此次查询所选择的索引长度有多少字节。
- ref:ref字段标识哪些字段或者常量被用来和key配合从表中查询记录出来,如果为NULL表示没有
- rows:该列表明MySQL估计要读取并检查的行数,需要注意的是,这个不是结果集里的行数。
- filtered:它指返回结果的行数(MySQL层where过滤生效的数据量)占需要扫描到的行数(rows列的值)的百分比,一般来说越高越好,越低证明查询代价越高。
- Extra:该列包含MySQL解决查询的详细信息(以下只列举常见的几种)。
- Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。
- Using index:这个值重点强调了只需要使用索引就可以满足查询表的要求,不需要直接访问表数据了,一般表示使用了覆盖索引。
- Using temporary:这个值表示使用了内部临时表(基于内存的表)。这种情况通常发生在查询时包含了group by和order by子句,或者来自不同表的列使用了distinct。
- Using where:where条件查询,通常using where表示优化器需要通过索引回表查询数据
4.2 业务层面分析
根据具体的业务场景进行考虑
- 查询条件是否都是必须的
- 查询时间范围可否缩短
- 表里面存在的一些大字段,根据实际情况缩短字段长度
- 如果不是每次都必须获取的话,可以考虑从当前表拆出去,主表都是小字段,子表维护大字段,这样效率会更高
五、解决
5.1 SQL优化
5.1.1索引优化
- 左前缀原则:索引了多个列时,查询时必须从最左列开始,不能跳过,否则索引失效
- 在使用不等于符号时(!=,<>)会索引失效
- 使用is not null会索引失效,但is null 不会
- like模糊查询中以通配符开头会索引失效
- 使用or时,左右两边的字段都需要加上索引,否则索引失效
- 在索引列上使用函数会索引失效
- 避免隐式类型转换-字符串类型字段不加单引号索引失效
- 有时候MySQL优化器选择的索引不一定是最优的,可以通过FORCE INDEX(idx_order_id)强制要求走某个索引,当然,必须保证这个索引以后不能被删除,不然就是个BUG
5.1.2 子查询优化
select something from user_table where id in (select user_id from order_table where xxx=yyyy);
MySQL从5.7开始优化器对子查询进行了优化,会自动转换为join再执行,而对于5.7以下版本的MySQL 我们建议把子查询改成join的方式:
select a.something from user_table a, order_table b
where a.id=b.user_id
and b.xxx=yyyy;
5.1.3 分页优化
Limit中分页查询会随着pageNo增大而变缓慢,通过子查询+表连接解决
select * from mytbl order by id limit 100000,10 改进后的SQL语句如下:
select * from mytbl where id >= ( select id from mytbl order by id limit 100000,1 )
limit 10
# 或者
select * from mytbl
inner join (select id from mytbl order by id limit 100000,10) as tmp
on tmp.id=ori.id;
5.1.4 Using filesort文件排序优化
orders建立了idx_ppo_created_at索引,使用EXPLAIN进行分析
EXPLAINSELECT id,
temp_id,
pos_id,
`type`,
member_id,
temp_status,
money_amount,
trans_amount,
return_trans_amount,
coupon_id,
cash_points,
is_cancel,
is_auto_cancel,
is_compensate,
is_multi_equity,
company_id,
store_id,
store_type,
source_orders,
return_order_id,
created_at,
updated_at
FROM orders
WHERE 1 = 1
AND `created_at` >= "2021-08-27 00:00:00"
AND `created_at` <= "2021-08-27 23:59:59"
AND `type` = 0
AND `is_cancel` = 0
AND `temp_status` = 0
ORDER BY id DESC
LIMIT 0,100
我们可以看到Extra列出现了Using filesort,说明MySQL会对数据使用一个外部的索引排序, 而不是按照表内索引顺序进行读取。
解决
因为索引的叶子节点数据是根据 created_at 有序的,我们可以利用这一点来避免排序。
我们将 ORDER BY id DESC 换成 ORDER BY created_at DESC,查看执行计划,Using filesort 已消失:
5.2 业务改造
如果SQL本身的性能已经到达极限了,但是耗时仍然很长。这时候,我们可以业务角度着手,看看在业务上能不能做一些变通、妥协。
5.2.1 总量显示优化
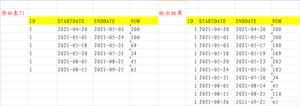
如上图所示,我们在做分页时,页底都会展示符合条件的记录总数,以及分页页数。数据量少的时候,不会带来性能问题,但如果数据量较大,这个计算总量的count() 本身就不会太快,再加上每次打开页面都要计算一次的话,那这样会就带性能问题了,同时也会拖慢页面打开速度。
如果业务上允许,当数据量少时,精确显示,当数据量过大后,用户对真实数据不敏感时,那我们就可以通过 1000+ 等模糊的方式进行初步显示,减少不必要的扫描,同时也可以让用户首次打开时达到加速效果。
原SQL:select count() from table where xxx=yyy;
调整后:select count(*) from (select id from table where xxx=yyy limit 1000);
5.2.1 关联表优化
由于业务很复杂,某条SQL关联了很多表,导致表关联时的匹配耗时很长。这时候可以看看能不能将多关联SQL改成较少表的关联,使用代码方式进行关联,但是会增加请求次数。
5.3 减少数据
如果单表行数超过500万行或者单表容量超过2GB,SQL再怎么优化还是会慢,这个时候就要做数据拆分,这属于架构层面的变动,影响的面很大,除了慢SQL本身之外,其他的相关SQL也可能会被“波及”到。这种慢SQL治理的手段,能够一定程度上解决慢SQL问题。减少作用数据的方式有:
- 垂直拆分
- 水平拆分
- 综合拆分(垂直+水平)
总结
本文介绍了实际工作中慢SQL治理的方法论
1、发现:如何发现慢SQL。
2、定位:如何定位到慢SQL写在哪。
3、分析:遇到慢SQL时的分析思路。
4、解决:慢SQL的解决思路。
SQL优化本身是一个比较复杂的问题,上面所列举的,只是部份优化的案例,但所有优化的思路都是尽可能的减少SQL在执行中过程中扫描数据块的次数,只要遵从这一核心思想,SQL优化并不是什么太难的事情。
以上就是今天要讲的内容,本文是笔者实际治理过程中的一些总结和心得,如有不正之处,还请指正。
以上是 慢SQL治理方法论 的全部内容, 来源链接: utcz.com/z/536370.html