阿里慢SQL治理5大经典案例

菜鸟供应链金融慢sql治理已经有一段时间,自己负责的应用持续很长时间没有慢sql告警,现阶段在推进组内其他成员治理应用慢sql。这里把治理过程中的一些实践拿出来分享下。
菜鸟供应链金融慢sql治理已经有一段时间,自己负责的应用持续很长时间没有慢sql告警,现阶段在推进组内其他成员治理应用慢sql。这里把治理过程中的一些实践拿出来分享下。
一、全表扫描
1、案例
SELECT count(*) AS tmp_count FROM (
SELECT * FROM `XXX_rules` WHERE 1 = 1 ORDER BY gmt_create DESC ) a
2、溯源
在分页查询治理的文章里已经介绍过我们系统旧的分页查询逻辑,上面的查询sql明显就是分页查询获取总记录数,通过XXX_rules表的分页查询接口溯源,找到发起调用的页面是我们小二后台的一个操作商家准入的页面,页面打开后直接调用分页查询接口,除了分页参数,不传入其他任何查询参数,导致扫描全表。
3、分析
灵魂拷问:为什么要扫描全表?全表数据展示到页面,花里胡哨的数据有用吗?
调研:和经常使用这个页面的运营聊后了解到,打开页面查询出的全表数据对运营是没有用的,他们根本不看这些数据。运营的操作习惯是拿到商家id,在页面查询框中输入商家id,查到商家数据后进行操作。
4、解决方案
由此优化方案就很明朗了:打开页面时不直接查询全量数据,等运营输入商家id后,将商家id作为参数进行查询。XXX_rules表中,商家id这一常用查询条件设置为索引,再结合分页查询优化,全表扫描慢sql得以解决。
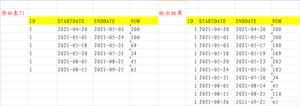
优化后的小二后台页面如下:
打开页面时未查询任何数据,查询条件商家账户为必填项。
优化后的sql为:
SELECT count(*) AS tmp_count FROM (
SELECT * FROM `xxx_rules` WHERE 1 = 1 AND `rule_value` = "2928597xxx" ) a
执行EXPLAIN得到结果如下:
可以看到命中了索引,扫描行数为3,查询速度明显提高。
5、思考
扫描全表治理简单来说就是加入查询条件,命中索引,去除全表扫描查询,虽然有些粗暴,但并不是没有道理。实际业务场景中,很少有要扫描全表获取全部数据的情况,限制调用上游必须传入查询条件,且该查询条件能命中索引,能很大程度上避免慢sql。
另外,再引申下,XXX_rules初始的用意是准入表,记录金融货主维度的准入情况,最多也就几千条数据,但是很多同事将这张表理解为规则表,写入很多业务相关规则,导致这个表膨胀到一百多万条数据,表不clean了。这就涉及到数据表的设计使用,明确表的使用规范,不乱写入数据,能给后期维护带来很大的便利。
二、索引混乱
1、示例
2、分析
除了时间、操作人字段,XXX_rules表就rule_name、rule_value、status、product_code四个字段,表的索引对这四个字段做各种排列组合。存在如下问题:
1)rule_name离散度不高,放在索引首位不合适;
2)前三个索引重合度很高;
显然是对索引的命中规则不够了解。XXX_rules表很多业务有定时任务对其写入删除,索引多、混乱,对性能有很大的影响。
高性能的索引有哪些,再来回顾下:
①独立的列:索引列不能是表达式的一部分;
②选择区分度高的列作为索引;
③选择合适的索引列顺序:将选择性高的索引列放在最前列;
④覆盖索引:查询的列均在索引中,不需要回查聚簇索引;
⑤使用索引扫描来做排序;
⑥在遵守最左前缀的原则下,尽量扩展索引,而不是创建索引。
但凡记得第③和⑥规则,也不至于把索引建成这样。
3、治理
对索引进行整合如下:
系统中有很多任务拉取整个产品下的准入记录,然后进行处理,所以将区分度较高的product_code放在索引首位,然后添加rule_name、status字段到索引里,进一步过滤数据,减少扫描行数,避免慢sql。针对常用的rule_value查询条件,可以命中UK,因此不用单独建立索引。
三、非必要排序
1、问题描述
很多业务逻辑中,需要拉取满足某个条件的记录列表,查询的sql语句带有order by,记录比较多的情况,排序代价往往很大,但是查询出来的记录是否有序对业务逻辑没有影响,比如分页治理里讨论的count语句,只需要统计条数,order by对条数没有影响,再比如查出记录列表后,不依赖记录的顺序遍历列表处理数据,这时候order by多此一举。
2、解决方案
查询sql无limit语句,且业务处理逻辑不依赖于order by后列表记录的顺序,则去除查询sql中的order by语句。
四、粗粒度查询
1、问题描述
业务中有很多定时任务,扫描某个表中某个产品下所有数据,对数据进行处理,比如:
SELECT * FROM XXX_rules
WHERE rule_name = "apf_distributors"
AND status = "00"
AND product_code = "ADVANCE"
三个查询条件都是区分度不高的列,查出的数据有27W条,加索引意义也不大。
2、分析
实际业务量没那么大,顶多几千条数据,表里的数据是从上游同步过来的,最好的办法是让上游精简数据,但是由于业务太久远,找上游的人维护难度太大,因此只能想其他的办法。
这个定时任务目的是拉出XXX_rules表的某些产品下的数据,和另一张表数据对比,更新有差异的数据。每天凌晨处理,对时效性没有很高的要求,因此,能不能转移任务处理的地方,不在本应用机器上实时处理那么多条数据?
3、解决方案
数据是离线任务odps同步过来的,首先想到的就是dataWork数据处理平台。
建立数据对比任务,将定时任务做的数据对比逻辑放到dataWork上用sql实现,每天差异数据最多几百条,且结果集含有区分度很高的列,将差异数据写入odps表,再将数据回流到idb。
新建定时任务,通过回流回来的差异数据中区分度高的列作为查询条件查询XXX_rules,更新XXX_rules,解决了慢sql问题。
这个方法的前提是对数据实效性要求不高,且离线产出的结果集很小。
五、OR导致索引失效
1、案例
SELECT count(*)
FROM XXX_level_report
WHERE 1 = 1
AND EXISTS (
SELECT 1
FROM XXX_white_list t
WHERE (t.biz_id = customer_id
OR customer_id LIKE CONCAT(t.biz_id, "@%"))
AND t.status = 1
AND (t.start_time <= CURRENT_TIME
OR t.start_time IS NULL)
AND (t.end_time >= CURRENT_TIME
OR t.end_time IS NULL)
AND t.biz_type = "GOODS_CONTROL_BLACKLIST"
2、分析
explain上述查询语句,得到结果如下:
XXX_white_list表有将biz_id作为索引,这里查询XXX_white_list表有传入biz_id作为查询条件,为啥explain结果里type为ALL,即扫描全表?索引失效了?索引失效有哪些情况?
索引失效场景:
①OR查询左右有未命中索引的;
②复合索引不满足最左匹配原则;
③Like以%开头;
④需要类型转换;
⑤where中索引列有运算;
⑥where中索引列使用了函数;
⑦如果mysql觉得全表扫描更快时(数据少时)
上述查询语句第8行,customer_id为XXX_level_report表字段,未命中XXX_white_list表索引,导致索引失效。
3、解决方案
这个语句用condition、枚举、join花里胡哨的代码拼接起来的,改起来好麻烦,而且看起来“OR customer_id LIKE CONCAT(t.biz_id, "@%")”这句不能直接删掉。最后重构了该部分的查询语句,去除or查询,解决了慢sql。
作者丨如期
菜鸟供应链金融慢sql治理已经有一段时间,自己负责的应用持续很长时间没有慢sql告警,现阶段在推进组内其他成员治理应用慢sql。这里把治理过程中的一些实践拿出来分享下。
一、全表扫描
1、案例
SELECT count(*) AS tmp_count FROM (
SELECT * FROM `XXX_rules` WHERE 1 = 1 ORDER BY gmt_create DESC ) a
2、溯源
在分页查询治理的文章里已经介绍过我们系统旧的分页查询逻辑,上面的查询sql明显就是分页查询获取总记录数,通过XXX_rules表的分页查询接口溯源,找到发起调用的页面是我们小二后台的一个操作商家准入的页面,页面打开后直接调用分页查询接口,除了分页参数,不传入其他任何查询参数,导致扫描全表。
3、分析
灵魂拷问:为什么要扫描全表?全表数据展示到页面,花里胡哨的数据有用吗?
调研:和经常使用这个页面的运营聊后了解到,打开页面查询出的全表数据对运营是没有用的,他们根本不看这些数据。运营的操作习惯是拿到商家id,在页面查询框中输入商家id,查到商家数据后进行操作。
4、解决方案
由此优化方案就很明朗了:打开页面时不直接查询全量数据,等运营输入商家id后,将商家id作为参数进行查询。XXX_rules表中,商家id这一常用查询条件设置为索引,再结合分页查询优化,全表扫描慢sql得以解决。
优化后的小二后台页面如下:
打开页面时未查询任何数据,查询条件商家账户为必填项。
优化后的sql为:
SELECT count(*) AS tmp_count FROM (
SELECT * FROM `xxx_rules` WHERE 1 = 1 AND `rule_value` = "2928597xxx" ) a
执行EXPLAIN得到结果如下:
可以看到命中了索引,扫描行数为3,查询速度明显提高。
5、思考
扫描全表治理简单来说就是加入查询条件,命中索引,去除全表扫描查询,虽然有些粗暴,但并不是没有道理。实际业务场景中,很少有要扫描全表获取全部数据的情况,限制调用上游必须传入查询条件,且该查询条件能命中索引,能很大程度上避免慢sql。
另外,再引申下,XXX_rules初始的用意是准入表,记录金融货主维度的准入情况,最多也就几千条数据,但是很多同事将这张表理解为规则表,写入很多业务相关规则,导致这个表膨胀到一百多万条数据,表不clean了。这就涉及到数据表的设计使用,明确表的使用规范,不乱写入数据,能给后期维护带来很大的便利。
二、索引混乱
1、示例
2、分析
除了时间、操作人字段,XXX_rules表就rule_name、rule_value、status、product_code四个字段,表的索引对这四个字段做各种排列组合。存在如下问题:
1)rule_name离散度不高,放在索引首位不合适;
2)前三个索引重合度很高;
显然是对索引的命中规则不够了解。XXX_rules表很多业务有定时任务对其写入删除,索引多、混乱,对性能有很大的影响。
高性能的索引有哪些,再来回顾下:
①独立的列:索引列不能是表达式的一部分;
②选择区分度高的列作为索引;
③选择合适的索引列顺序:将选择性高的索引列放在最前列;
④覆盖索引:查询的列均在索引中,不需要回查聚簇索引;
⑤使用索引扫描来做排序;
⑥在遵守最左前缀的原则下,尽量扩展索引,而不是创建索引。
但凡记得第③和⑥规则,也不至于把索引建成这样。
3、治理
对索引进行整合如下:
系统中有很多任务拉取整个产品下的准入记录,然后进行处理,所以将区分度较高的product_code放在索引首位,然后添加rule_name、status字段到索引里,进一步过滤数据,减少扫描行数,避免慢sql。针对常用的rule_value查询条件,可以命中UK,因此不用单独建立索引。
三、非必要排序
1、问题描述
很多业务逻辑中,需要拉取满足某个条件的记录列表,查询的sql语句带有order by,记录比较多的情况,排序代价往往很大,但是查询出来的记录是否有序对业务逻辑没有影响,比如分页治理里讨论的count语句,只需要统计条数,order by对条数没有影响,再比如查出记录列表后,不依赖记录的顺序遍历列表处理数据,这时候order by多此一举。
2、解决方案
查询sql无limit语句,且业务处理逻辑不依赖于order by后列表记录的顺序,则去除查询sql中的order by语句。
四、粗粒度查询
1、问题描述
业务中有很多定时任务,扫描某个表中某个产品下所有数据,对数据进行处理,比如:
SELECT * FROM XXX_rules
WHERE rule_name = "apf_distributors"
AND status = "00"
AND product_code = "ADVANCE"
三个查询条件都是区分度不高的列,查出的数据有27W条,加索引意义也不大。
2、分析
实际业务量没那么大,顶多几千条数据,表里的数据是从上游同步过来的,最好的办法是让上游精简数据,但是由于业务太久远,找上游的人维护难度太大,因此只能想其他的办法。
这个定时任务目的是拉出XXX_rules表的某些产品下的数据,和另一张表数据对比,更新有差异的数据。每天凌晨处理,对时效性没有很高的要求,因此,能不能转移任务处理的地方,不在本应用机器上实时处理那么多条数据?
3、解决方案
数据是离线任务odps同步过来的,首先想到的就是dataWork数据处理平台。
建立数据对比任务,将定时任务做的数据对比逻辑放到dataWork上用sql实现,每天差异数据最多几百条,且结果集含有区分度很高的列,将差异数据写入odps表,再将数据回流到idb。
新建定时任务,通过回流回来的差异数据中区分度高的列作为查询条件查询XXX_rules,更新XXX_rules,解决了慢sql问题。
这个方法的前提是对数据实效性要求不高,且离线产出的结果集很小。
五、OR导致索引失效
1、案例
SELECT count(*)
FROM XXX_level_report
WHERE 1 = 1
AND EXISTS (
SELECT 1
FROM XXX_white_list t
WHERE (t.biz_id = customer_id
OR customer_id LIKE CONCAT(t.biz_id, "@%"))
AND t.status = 1
AND (t.start_time <= CURRENT_TIME
OR t.start_time IS NULL)
AND (t.end_time >= CURRENT_TIME
OR t.end_time IS NULL)
AND t.biz_type = "GOODS_CONTROL_BLACKLIST"
2、分析
explain上述查询语句,得到结果如下:
XXX_white_list表有将biz_id作为索引,这里查询XXX_white_list表有传入biz_id作为查询条件,为啥explain结果里type为ALL,即扫描全表?索引失效了?索引失效有哪些情况?
索引失效场景:
①OR查询左右有未命中索引的;
②复合索引不满足最左匹配原则;
③Like以%开头;
④需要类型转换;
⑤where中索引列有运算;
⑥where中索引列使用了函数;
⑦如果mysql觉得全表扫描更快时(数据少时)
上述查询语句第8行,customer_id为XXX_level_report表字段,未命中XXX_white_list表索引,导致索引失效。
3、解决方案
这个语句用condition、枚举、join花里胡哨的代码拼接起来的,改起来好麻烦,而且看起来“OR customer_id LIKE CONCAT(t.biz_id, "@%")”这句不能直接删掉。最后重构了该部分的查询语句,去除or查询,解决了慢sql。
作者丨如期
本文来自云海天,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/5_Classic_Cases_of_Alibaba_Slow_SQL_Governance.html
以上是 阿里慢SQL治理5大经典案例 的全部内容, 来源链接: utcz.com/z/536360.html