[离线计算Spark|Hive]数据近实时同步数仓方案设计

本文主要针对hudi进行调研, 设计MySQL CDC 近实时同步至数仓中方案, 写入主要利用hudi的upsert以及delete能力. 针对hudi 表的查询,引入kyuubi 框架,除 了增强平台 spark sql 一些即席查询服务的能力外,同时支持查询hudi表,并可以实现hudi表与hive表的联合查询, 同时对原有hive相关服务没有太大影响.
背景
最近阅读了大量关于hudi相关文章, 下面结合对Hudi的调研, 设计一套技术方案用于支持 MySQL数据CDC同步至数仓中,避免繁琐的ETL流程,借助Hudi的upsert, delete 能力,来缩短数据的交付时间.
组件版本:
- Hadoop 2.6.0
- Hive 1.1.0
- hudi 0.7.0
- spark 2.4.6
架构设计
- 使用canal(阿里巴巴MySQL Binlog增量订阅&消费组件)dump mysql binlog 数据
- 采集后将binlog 数据采集到kafka中, 按照库名创建topic, 并按照表名将数据写入topic 固定分区
- spark 消费数据将数据生成DF
- 将DF数据写入hudi表
- 同步hudi元数据到hive中
写入主要分成两部分全量数据和增量数据:
历史数据通过bulkinsert 方式 同步写入hudi
增量数据直接消费写入使用hudi的upsert能力,完成数据合并
写入hudi在hdfs的格式如下:
hudi
hudi 如何处理binlog upsert,delete 事件进行数据的合并?
upsert好理解, 依赖本身的能力.
针对mysql binlog的delete 事件,使用记录级别删除:
需要在数据中添加 "_HOODIE_IS_DELETED" 且值为true的列
需要在dataFrame中添加此列,如果此值为false或者不存在则当作常规写入记录
如果此值为true则为删除记录
示例代码如下:
StructField(_HOODIE_IS_DELETED, DataTypes.BooleanType, true, Metadata.empty());
dataFrame.write.format("org.apache.hudi") .option("hoodie.table.name", "test123")
.option("hoodie.datasource.write.operation", "upsert")
.option("hoodie.datasource.write.recordkey.field", "uuid")
.option("hoodie.datasource.write.partitionpath.field", "partitionpath")
.option("hoodie.datasource.write.storage.type", "COPY_ON_WRITE")
.option("hoodie.datasource.write.precombine.field", "ts")
.mode(Append)
.save(basePath)
写入hudi及同步数据至hive,需要注意的事情和如何处理?
声明为hudi表的path路径, 非分区表 使用tablename/, 分区表根据分区路径层次定义/个数
在创建表时需添加 TBLPROPERTIES "spark.sql.sources.provider"="hudi" 声明为datasource为hudi类型的表
hudi如何处理新增字段?
当使用Spark查询Hudi数据集时,当数据的schema新增时,会获取单个分区的parquet文件来推导出schema,若变更schema后未更新该分区数据,那么新增的列是不会显示,否则会显示该新增的列;若未更新该分区的记录时,那么新增的列也不会显示,可通过 mergeSchema来控制合并不同分区下parquet文件的schema,从而可达到显示新增列的目的
hudi 写入时指定mergeSchema参数 为true
spark如何实现hudi表数据的写入和读取?
Spark支持用户自定义的format来读取或写入文件,只需要实现对应的(RelationProvider、SchemaRelationProvider)等接口即可。而Hudi也自定义实现了 org.apache.hudi/ hudi来实现Spark对Hudi数据集的读写,Hudi中最重要的一个相关类为 DefaultSource,其实现了 CreatableRelationProvider#createRelation接口,并实现了读写逻辑
kyuubi
如何读取hudi表数据?
使用网易开源的kyuubi
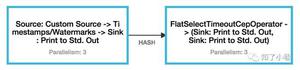
kyuubi架构图:
支持HiveServer2 Thrift API协议,可以通过beeline 连接
hive: beeline -u jdbc:hive2://ip:10000 -n userName -p kyuubi: beeline -u jdbc:hive2://ip:8333 -n userName -p
hudi 元数据使用hive metastore
spark来识别加载hudi表
实现hudi表与hive表关联查询
kyuubi 支持SparkContext的动态缓存,让用户不需要每次查询都动态创建SparkContext。作为一个应用在yarn 上一直运行,终止beeline 连接后,应用仍在运行,下次登录,使用SQL可以直接查询
总结
本文主要针对hudi进行调研, 设计MySQL CDC 近实时同步至数仓中方案, 写入主要利用hudi的upsert以及delete能力. 针对hudi 表的查询,引入kyuubi 框架,除 了增强平台 spark sql作为即席查询服务的能力外,同时支持查询hudi表,并可以实现hudi表与hive表的联合查询, 同时对原有hive相关服务没有太大影响.
参考
- https://blog.csdn.net/weixin_38166318/article/details/111825032
- https://blog.csdn.net/qq_37933018/article/details/120864648
- https://cxymm.net/article/qq_37933018/120864648
- https://www.jianshu.com/p/a271524adcc3
- https://jishuin.proginn.com/p/763bfbd65b70
本文作者: chaplinthink, 关注领域:大数据、基础架构、系统设计, 一个热爱学习、分享的大数据工程师
以上是 [离线计算Spark|Hive]数据近实时同步数仓方案设计 的全部内容, 来源链接: utcz.com/z/536249.html