详细记录一次stampstime字段引起pxc集群脑裂

事故回顾
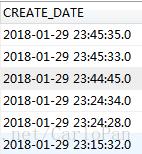
运维执行导入sql,导入后收到master2和master3节点宕机的报警;
检查集群状态发现master1进入初始化模式,无法读写;master2和master3已经下线;
处理方法
分别进入3个master节点,发现master2和master3两个节点已经退出;
master1节点可以进入,使用命令show global status like "wsrep_local_state_comment";查看发现集群进入Initialized状态,集群不能读写;
重启master1节点,重启完成后,节点恢复读写,业务恢复正常;
逐个启动master2和master3节点,恢复集群的状态;
注1:master2和master3数据同步时可能会存在锁表造成集群不可访问,所以建议在业务低峰时恢复业务;
注2:如果master2和master3下线时间过长,可能触发全量同步;
注3:建议将数据库的wsrep_sst_method参数值改为xtrabackup,可用方法有mysqldump、rsync和xtrabackup,前两者在传输时都需要对Donor加全局只读锁(FLUSH TABLES WITH READ LOCK),xtrabackup则不需要(它使用percona自己提供的backup lock);
事故原因
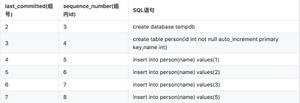
业务需求从beta导一个表结构到生产,运维导出时漏加了--skip-tz-utc参数,导致使用了mysqldump的默认值--tz-utc;
导出的sql中会增加一个将session改为utc时区(+00:00)的设置,并将timestamp字段的时间同步减8小时(由+8:00时区改为+00:00);
将这个sql导入pxc集群时,master1导入成功。当这个操作同步到另外2个pxc节点时,session中的时区设置并不会同步,造成导入sql的时间比实际少了8小时;
我们导入的表默认时间为1970:08:01,时间减少后变成了1970:00:01,超过了cts时区(+08:00)timestamp字段允许的最小值(1970:08:00),建表失败;
master2和3数据跟master1不一致,节点下线。master1发现只有自己最后1个节点存在,认为集群失效,变为初始化状态,pxc集群无法读写;
后续处理与防范
使用脚本来操作数据库的导入导出,避免人为因素导致集群异常;
排期配置和验证允许脏读,让集群出问题时,数据库至少能提供查询服务。这个需要考虑业务是否支持;
以上是 详细记录一次stampstime字段引起pxc集群脑裂 的全部内容, 来源链接: utcz.com/z/536196.html