SQL为聚合结果指定条件(HAVING)

目录
- 一、HAVING 子句
- 二、HAVING 子句的构成要素
- 三、相对于 HAVING 子句,更适合写在 WHERE 子句中的条件
- 请参阅
学习重点
使用
COUNT函数等对表中数据进行汇总操作时,为其指定条件的不是WHERE子句,而是HAVING子句。聚合函数可以在
SELECT子句、HAVING子句和ORDER BY子句中使用。
HAVING子句要写在GROUP BY子句之后。
WHERE子句用来指定数据行的条件,HAVING子句用来指定分组的条件。
一、HAVING 子句
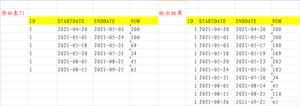
使用前一节学过的 GROUP BY 子句,可以得到将表分组后的结果。在此,我们来思考一下通过指定条件来选取特定组的方法。例如,如何才能取出“聚合结果正好为 2 行的组”呢(图 8)?
图 8 取出符合指定条件的组
说到指定条件,估计大家都会首先想到 WHERE 子句。但是,WHERE 子句只能指定记录(行)的条件,而不能用来指定组的条件(例如,“数据行数为 2 行”或者“平均值为 500”等)。
因此,对集合指定条件就需要使用其他的子句了,此时便可以用 HAVING 子句 [1]。
KEYWORD
HAVING子句
HAVING 子句的语法如下所示。
语法 3 HAVING 子句
SELECT <列名1>, <列名2>, <列名3>, …… FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……
HAVING <分组结果对应的条件>
HAVING 子句必须写在 GROUP BY 子句之后,其在 DBMS 内部的执行顺序也排在 GROUP BY 子句之后。
▶ 使用 HAVING 子句时 SELECT 语句的顺序
SELECT → FROM → WHERE → GROUP BY → HAVING
法则 13
HAVING子句要写在GROUP BY子句之后。
接下来就让我们练习一下 HAVING 子句吧。例如,针对按照商品种类进行分组后的结果,指定“包含的数据行数为 2 行”这一条件的 SELECT 语句,请参见代码清单 20。
代码清单 20 从按照商品种类进行分组后的结果中,取出“包含的数据行数为2行”的组
SELECT product_type, COUNT(*) FROM Product
GROUP BY product_type
HAVING COUNT(*) = 2;
执行结果
product_type | count--------------+------
衣服 | 2
办公用品 | 2
我们可以看到执行结果中并没有包含数据行数为 4 行的“厨房用具”。未使用 HAVING 子句时的执行结果中包含“厨房用具”,但是通过设置 HAVING 子句的条件,就可以选取出只包含 2 行数据的组了(代码清单 21)。
代码清单 21 不使用 HAVING 子句的情况
SELECT product_type, COUNT(*) FROM Product
GROUP BY product_type;
执行结果
下面我们再来看一个使用 HAVING 子句的例子。这次我们还是按照商品种类对表进行分组,但是条件变成了“销售单价的平均值大于等于 2500 日元”。
首先来看一下不使用 HAVING 子句的情况,请参见代码清单 22。
代码清单 22 不使用 HAVING 子句的情况
SELECT product_type, AVG(sale_price) FROM Product
GROUP BY product_type;
执行结果
product_type | avg--------------+----------------------
衣服 | 2500.0000000000000000
办公用品 | 300.0000000000000000
厨房用具 | 2795.0000000000000000
按照商品种类进行切分的 3 组数据都显示出来了。下面我们使用 HAVING 子句来设定条件,请参见代码清单 23。
代码清单 23 使用 HAVING 子句设定条件的情况
SELECT product_type, AVG(sale_price) FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;
执行结果
product_type | avg--------------+----------------------
衣服 | 2500.0000000000000000
厨房用具 | 2795.0000000000000000
销售单价的平均值为 300 日元的“办公用品”在结果中消失了。
二、HAVING 子句的构成要素
HAVING 子句和包含 GROUP BY 子句时的 SELECT 子句一样,能够使用的要素有一定的限制,限制内容也是完全相同的。HAVING 子句中能够使用的 3 种要素如下所示。
常数
聚合函数
GROUP BY子句中指定的列名(即聚合键)
代码清单 20 中的例文指定了 HAVING COUNT(*)= 2 这样的条件,其中 COUNT(*) 是聚合函数,2 是常数,全都满足上述要求。反之,如果写成了下面这个样子就会发生错误(代码清单 24)。
代码清单 24 HAVING 子句的不正确使用方法
SELECT product_type, COUNT(*) FROM Product
GROUP BY product_type
HAVING product_name = "圆珠笔";
执行结果
ERROR: 列"product,product_name"必须包含在GROUP BY子句当中,或者必须在聚合函数中使用行 4: HAVING product_name = "圆珠笔";
product_name 列并不包含在 GROUP BY 子句之中,因此不允许写在 HAVING 子句里。在思考 HAVING 子句的使用方法时,把一次汇总后的结果(类似表 2 的表)作为 HAVING 子句起始点的话更容易理解。
表 2 按照商品种类分组后的结果
product_typeCOUNT(*)
厨房用具
4
衣服
2
办公用品
2
可以把这种情况想象为使用 GROUP BY 子句时的 SELECT 子句。汇总之后得到的表中并不存在 product_name 这个列,SQL 当然无法为表中不存在的列设定条件了。
三、相对于 HAVING 子句,更适合写在 WHERE 子句中的条件
也许有的读者已经发现了,有些条件既可以写在 HAVING 子句当中,又可以写在 WHERE 子句当中。这些条件就是聚合键所对应的条件。原表中作为聚合键的列也可以在 HAVING 子句中使用。因此,代码清单 25 中的 SELECT 语句也是正确的。
代码清单 25 将条件书写在 HAVING 子句中的情况
SELECT product_type, COUNT(*) FROM Product
GROUP BY product_type
HAVING product_type = "衣服";
执行结果
product_type | count--------------+------
衣服 | 2
上述 SELECT 语句的返回结果与代码清单 26 中 SELECT 语句的返回结果是相同的。
代码清单 26 将条件书写在 WHERE 子句中的情况
SELECT product_type, COUNT(*) FROM Product
WHERE product_type = "衣服"
GROUP BY product_type;
执行结果
product_type | count--------------+------
衣服 | 2
虽然条件分别写在 WHERE 子句和 HAVING 子句当中,但是条件的内容以及返回的结果都完全相同。因此,大家可能会觉得两种书写方式都没问题。
如果仅从结果来看的话,确实如此。但笔者却认为,聚合键所对应的条件还是应该书写在 WHERE 子句之中。
理由有两个。
首先,根本原因是 WHERE 子句和 HAVING 子句的作用不同。如前所述,HAVING 子句是用来指定“组”的条件的。因此,“行”所对应的条件还是应该写在 WHERE 子句当中。这样一来,书写出的 SELECT 语句不但可以分清两者各自的功能,理解起来也更加容易。
WHERE 子句 = 指定行所对应的条件
HAVING 子句 = 指定组所对应的条件
其次,对初学者来说,研究 DBMS 的内部实现这一话题有些深奥,这里就不做介绍了,感兴趣的读者可以参考随后的专栏——WHERE 子句和 HAVING 子句的执行速度。
法则 14
聚合键所对应的条件不应该书写在
HAVING子句当中,而应该书写在WHERE子句当中。
专栏
WHERE子句和HAVING子句的执行速度在
WHERE子句和HAVING子句中都可以使用的条件,最好写在WHERE子句中的另一个理由与性能即执行速度有关系。由于性能不在本教程介绍的范围之内,因此暂不进行说明。通常情况下,为了得到相同的结果,将条件写在WHERE子句中要比写在HAVING子句中的处理速度更快,返回结果所需的时间更短。为了理解其中原因,就要从 DBMS 的内部运行机制来考虑。使用
COUNT函数等对表中的数据进行聚合操作时,DBMS 内部就会进行排序处理。排序处理是会大大增加机器负担的高负荷的处理[2]。因此,只有尽可能减少排序的行数,才能提高处理速度。通过
WHERE子句指定条件时,由于排序之前就对数据进行了过滤,因此能够减少排序的数据量。但HAVING子句是在排序之后才对数据进行分组的,因此与在WHERE子句中指定条件比起来,需要排序的数据量就会多得多。虽然 DBMS 的内部处理不尽相同,但是对于排序处理来说,基本上都是一样的。此外,
WHERE子句更具速度优势的另一个理由是,可以对WHERE子句指定条件所对应的列创建索引,这样也可以大幅提高处理速度。创建索引是一种非常普遍的提高 DBMS 性能的方法,效果也十分明显,这对WHERE子句来说也十分有利。KEYWORD
- 索引(index)
请参阅
- 对表进行聚合查询
- 对表进行分组
- 为聚合结果指定条件
- 对查询结果进行排序
(完)
HAVING是 HAVE( 拥有 )的现在分词,并不是通常使用的英语单词。 ↩︎虽然 Oracle 等数据库会使用散列(hash)处理来代替排序,但那同样也是加重机器负担的处理。 ↩︎
以上是 SQL为聚合结果指定条件(HAVING) 的全部内容, 来源链接: utcz.com/z/536080.html