MySQL45讲之查询慢或者阻塞flowers

本文介绍锁表和执行慢的例子,以及发生锁表时的排查方法。
前言
本文介绍锁表和执行慢的例子,以及发生锁表时的排查方法。
锁表
1. 等MDL锁
比如像 select * from t where id=1; 长时间不返回,可能是因为等 MDL 锁而阻塞。
排查方法:
使用 show processlist; 查看线程状态
由上图可知,其他线程正在表上请求或者持有 MDL 写锁,所以阻塞了 select 获取 MDL 读锁。
如果想模拟获取 MDL 写锁,可以通过
lock table t write;实现。
解决办法:
只需要找到阻塞 select 获取 MDL 读锁的线程,kill 掉就可以了。因为 MDL 是表级锁,所以查询 sys 表的 schema_table_lock_waits 字段,就可以得到阻塞的 process id。
2. 等待flush
MySQL里面对表做flush操作的用法,一般有以下两个:
# 关闭表 tflush tables t with read lock;
# 关闭所有打开的表
flush tables with read lock;
等待 flush 表示一个线程正要对表做 flush 操作,但是被其他线程阻塞,而 flush 操作又会阻塞后来的 select 查询操作。
排查方法:
很简单,通过 show processlist; 就可以发现。
3. 等行锁
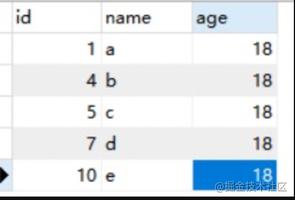
如上图,session A 对 id=1 的行上了行锁,且事务一直没有提交,导致阻塞 session B 对该行执行当前读。
排查方法:
同样通过 show processlist; 方法排查。
其中,id=8 行就是被阻塞的查询,线程被阻塞状态为 statistics。
解决办法:
同样是找到阻塞的线程 id,然后 kill 掉。行锁是 innodb 引擎提供的,通过查询 sys 表的 innodb_lock_waits 行可以得到 process id。
执行慢
session A 中第二条查询语句比第一条查询快很多。因为第二条加锁查询是当前读,直接获取当前行数据;第一条查询是快照读,因为 session B 在之前对 id=1 的行更新了 100 万次,所以需要根据 undo log 日志对当前行执行 100 万次回滚操作。
总结
对于阻塞问题的排查,使用 show processlist;。对于阻塞问题的解决,通过在 sys 表中查询阻塞线程的 process id,比如 schema_table_lock_waits、innodb_lock_waits。
提问
存在索引的字段进行当前读,我们知道会在索引树上对符合的行上锁,那对于 select * from t where c = 5 for update; (字段 c 不存在索引)语句如何上锁,什么时候释放锁?
回答:
(1)提交读 rc 隔离级别下
因为字段 c 不存在索引,所以进入存储引擎后,会在主键索引树上对全表加排他锁。在此优化器做了一些优化,返回 MySQL server 后,会判断出不符合条件的行,即 c != 5 的行,释放这些行上的排他锁。最后,在事务提交的时候释放锁。
所以,在一个事务执行完这条 SQL 后,在另一个事务可以对 c != 5 的行进行更新和删除操作,并且可以在任何位置执行插入操作(因为 rc 模式下,没有使用间隙锁)。
(2)可重复读 rr 隔离级别下
因为字段 c 不存在索引,所以进入存储引擎后,会在主键索引树上对全表加排他和间隙锁。最后,在事务提交的时候释放锁。
所以,在一个事务执行完这条 SQL 后,在另一个事务对全表任何一行的更新操作都需要等待,在全表任何位置的插入操作也需要等待。
参考
- [1] 为什么我只查一行的语句,也执行这么慢
以上是 MySQL45讲之查询慢或者阻塞flowers 的全部内容, 来源链接: utcz.com/z/535955.html