TDSQLMySQL版基本原理水平分表读写分离弹性扩展强同步

TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分、Shared Nothing 架构的分布式数据库。TDSQL MySQL版 即业务获取的是完整的逻辑库表,而后端会将库表均匀的拆分到多个物理分片节点。
水平分表
概述
水平拆分方案是 TDSQL MySQL版 的基础原理,它的每个节点都参与计算和数据存储,且每个节点都仅计算和存储一部分数据。因此,无论业务的规模如何增长,我们仅需要在分布式集群中不断的添加设备,用新设备去应对增长的计算和存储需要即可。
通过如下视频,您可以了解水平拆分的过程与原理:https://cloud.tencent.com/document/product/557/10521
水平切分
水平切分(分表):是按照某种规则,将一个表的数据分散到多个物理独立的数据库服务器中,形成“独立”的数据库“分片”。多个分片共同组成一个逻辑完整的数据库实例。
常规的单机数据库中,一张完整的表仅在一个物理存储设备上读写。
分布式数据库中,根据在建表时设定的分表键,系统将根据不同分表键自动分布到不同的物理分片中,但逻辑上仍然是一张完整的表。
在 TDSQL MySQL版 中,数据的切分通常就需要找到一个分表键(shardkey)以确定拆分维度,再采用某个字段求模(HASH)的方案进行分表,而计算 HASH 的某个字段就是 shardkey。 HASH 算法能够基本保证数据相对均匀地分散在不同的物理设备中。
写入数据( SQL 语句含有 shardkey )
- 业务写入一行数据。
- 网关通过对 shardkey 进行 hash。
- 不同的 hash 值范围对应不同的分片(调度系统预先分片的算法决定)。
- 数据根据分片算法,将数据存入实际对应的分片中。
数据聚合
数据聚合:如果一个查询 SQL 语句的数据涉及到多个分表,此时 SQL 会被路由到多个分表执行,TDSQL MySQL版 会将各个分表返回的数据按照原始 SQL 语义进行合并,并将最终结果返回给用户。
注意:
执行 SELECT 语句时,建议您在 where 条件带上 shardKey 字段,否则会导致数据需要全表扫描然后网关才对执行结果进行聚合。全表扫描响应较慢,对性能影响很大。
读取数据(有明确 shardkey 值)
- 业务发送 select 请求中含有 shardkey 时,网关通过对 shardkey 进行 hash。
- 不同的 hash 值范围对应不同的分片。
- 数据根据分片算法,将数据从对应的分片中取出。
读取数据(无明确 shardkey 值)
- 业务发送 select 请求没有 shardkey 时,将请求发往所有分片。
- 各个分片查询自身内容,发回 Proxy 。
- Proxy 根据 SQL 规则,对数据进行聚合,再答复给网关。
读写分离">读写分离
功能简介
当处理大数据量读请求的压力大、要求高时,可以通过读写分离功能将读的压力分布到各个从节点上。
TDSQL MySQL版 默认支持读写分离功能,架构中的每个从机都能支持只读能力,如果配置有多个从机,将由网关集群(TProxy)自动分配到低负载从机上,以支撑大型应用程序的读取流量。
基本原理
读写分离基本的原理是让主节点(Master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),让从节点(Slave)处理查询操作(SELECT)。
只读账号
只读帐号是一类仅有读权限的帐号,默认从数据库集群中的从机(或只读实例)中读取数据。
通过只读帐号,对读请求自动发送到备机,并返回结果。
弹性扩展
概述
TDSQL MySQL版 支持在线实时扩容,扩容方式分为新增分片和现有分片扩容两种方式,整个扩容过程对业务完全透明,无需业务停机。扩容时仅部分分片存在秒级的只读或中断,整个集群不会受影响。
扩容过程
TDSQL MySQL版 主要是采用自研的自动再均衡技术保证自动化的扩容和稳定。
新增分片扩容
- 在 TDSQL MySQL版控制台 对需要扩容的 A 节点进行扩容操作。
- 根据新加 G 节点配置,将 A 节点部分数据搬迁(从备机)到 G 节点。
- 数据完全同步后,A、G 节点校验数据库,存在一至几十秒的只读,但整个服务不会停止。
- 调度通知 proxy 切换路由。
现有分片扩容
基于现有分片的扩容相当于更换了一块更大容量的物理分片。
说明:
基于现有分片的扩容没有增加分片,不会改变划分分片的逻辑规则和分片数量。
- 按需要升级的配置分配一个新的物理分片(以下简称新分片)。
- 将需要升级的物理分片(以下简称老分片)的数据、配置等同步数据到新分片中。
- 同步数据完成后,在腾讯云网关做路由切换,切换到新分片继续使用。
相关操作
分布式数据库由多个分片组成,如您需要将现有 TDSQL MySQL版 实例的规格升级到更高规格,请参见 升级实例。
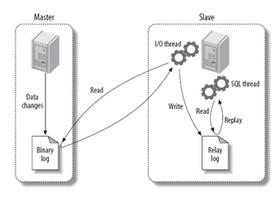
强同步
背景
传统数据复制方式有如下三种:
- 异步复制:应用发起更新请求,主节点(Master) 完成相应操作后立即响应应用,Master 向从节点(Slave)异步复制数据。
- 强同步复制:应用发起更新请求,Master 完成操作后向 Slave 复制数据,Slave 接收到数据后向 Master 返回成功信息,Master 接到 Slave 的反馈后再应答给应用。Master 向 Slave 复制数据是同步进行的。
- 半同步复制:应用发起更新请求,Master 在执行完更新操作后立即向 Slave 复制数据,Slave 接收到数据并写到 relay log 中(无需执行) 后才向 Master 返回成功信息,Master 必须在接受到 Slave 的成功信息后再向应用程序返回响应。
存在问题
当 Master 或 Slave 不可用时,以上三种传统数据复制方式均有几率引起数据不一致。
数据库作为系统数据存储和服务的核心能力,其可用性要求非常高。在生产系统中,通常都需要用高可用方案来保证系统不间断运行,而数据同步技术是数据库高可用方案的基础。
解决方案
MAR 强同步复制方案是腾讯自主研发的基于 MySQL 协议的并行多线程强同步复制方案,只有当备机数据完全同步(日志)后,才由主机给予应用事务应答,保障数据正确安全。
原理示意图如下:
在应用层发起请求时,只有当从节点(Slave)返回信息成功后,主节点(Master)才向应用层应答请求成功,以确保主从节点数据完全一致。
MAR 强同步方案在性能上优于其他主流同步方案,具体数据详情可参见 强同步性能对比数据。主要特点如下:
一致性的同步复制,保证节点间数据强一致性。
对业务层面完全透明,业务层面无需做读写分离或同步强化工作。
将串行同步线程异步化,引入线程池能力,大幅度提高性能。
支持集群架构。
支持自动成员控制,故障节点自动从集群中移除。
支持自动节点加入,无需人工干预。
每个节点都包含完整的数据副本,可以随时切换。
无需共享存储设备。
以上是 TDSQLMySQL版基本原理水平分表读写分离弹性扩展强同步 的全部内容, 来源链接: utcz.com/z/535898.html